![[Pandas] describe(), hist()를 통한 데이터 분석](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbk7eK8%2Fbtrc8hJ8sdE%2FoHQGjIixDOZvAezNwFeQR0%2Fimg.png)
사용 데이터
MovieLens 영화 데이터 -> ml-latest-small.zip -> ratings.csv
https://grouplens.org/datasets/movielens/
import pandas as pd
ratings = pd.read_csv('[파일 경로]/ratings.csv')
describe()
ratings['rating'].describe()데이터의 개수 및 최대,최소값 분석
<결과>
count 100836.000000
mean 3.501557
std 1.042529
min 0.500000
25% 3.000000
50% 3.500000
75% 4.000000
max 5.000000
Name: rating, dtype: float64
hist()
ratings['rating'].hist()pandas에서 기본적으로 제공하는 히스토그램 함수
<결과>
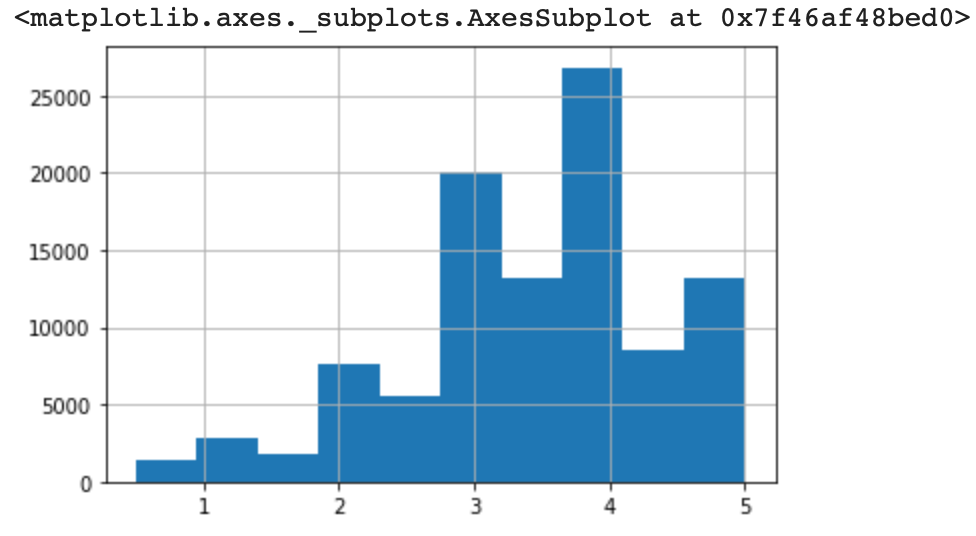
+) 만약 그래프가 안보이는 경우 앞에 다음 코드를 추가하자.
%matplotlib inline # 추가
ratings['rating'].hist()'python > data analysis' 카테고리의 다른 글
| [Pandas] 영화 평점 데이터 분석 (0) | 2021.08.26 |
|---|---|
| [Pandas] 멱함수 분포 (0) | 2021.08.26 |
| [Pandas] seaborn - heatmap을 사용한 데이터 상관관계 시각화 (0) | 2021.08.26 |
| [Pandas] get_dummies를 사용한 수치화된 데이터 생성 (0) | 2021.08.26 |
| [Pandas] apply 함수를 사용한 데이터 분석 (0) | 2021.08.25 |