![[Pandas] 영화 평점 데이터 분석](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FpweCE%2Fbtrdetbs34S%2FLeze5D7HjI5i7Y6QSJkAM0%2Fimg.png)
최근 Pandas를 통해 영화 평점 데이터를 분석하면서 실습했던 내용을 기록한다.
사용 데이터
MovieLens 영화 데이터 -> ml-latest-small.zip -> movies.csv, ratings.csv
https://grouplens.org/datasets/movielens/
import pandas as pd
movies = pd.read_csv('[파일 경로]/movies.csv', index_col='movieId')
ratings = pd.read_csv('[파일 경로]/ratings.csv')

영화에 대한 목록(movies)과 각 영화에 대한 평점(ratings) 데이터
겨울왕국 평점보기
당연히 평점이 높을 것으로 예상되는 겨울왕국(Frozen)은 사람들이 어떻게 평점을 주었는지에 대한 궁금증에서 출발한다.
겨울왕국의 movieId는 106696이다.
# movieId = 106696
movies.loc[106696]
<결과>
title Frozen (2013)
genres Adventure|Animation|Comedy|Fantasy|Musical|Rom...
Name: 106696, dtype: object
겨울왕국에 평점 정보를 알아보자.
ratings[ratings['movieId'] == 106696]
<결과>
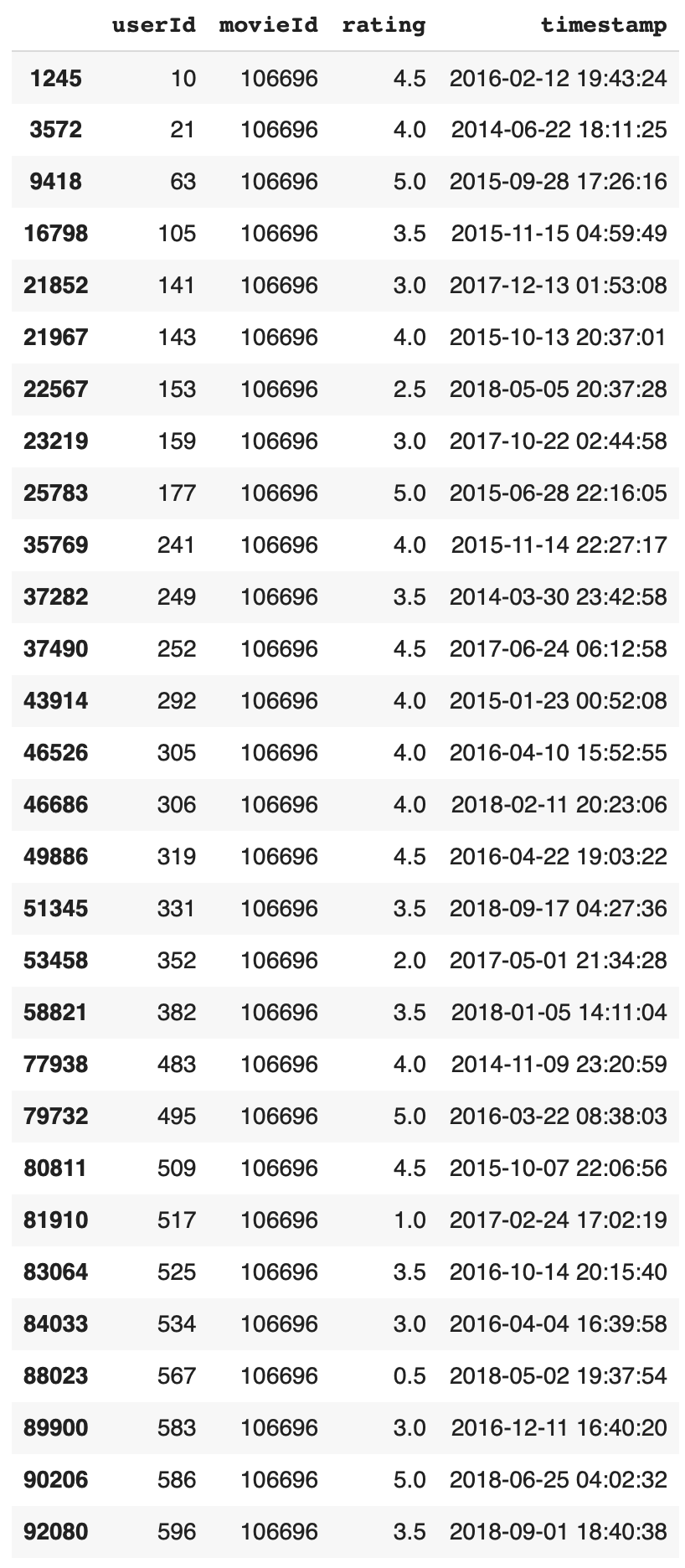
역시 예상대로 대체적으로 좋은 평점을 받고 있다.
frozen = ratings[ratings['movieId'] == 106696]
frozen['rating'].hist()
<결과>
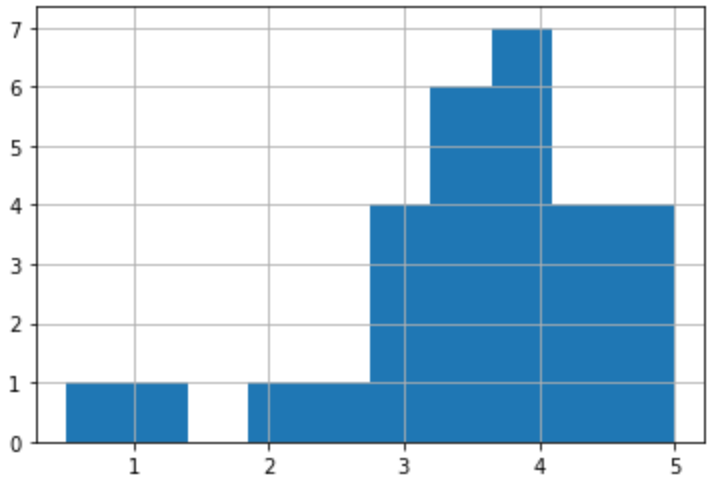
그런데 그래프를 보면 0.5점을 준 사람도 있다....!
ratings 데이터 밑에서 4번째를 보면 0.5점을 준 사람을 찾았다.

대체 뭐하는 사람이길래 겨울왕국에 0.5점을 주는 걸까...
저 사용자(userId = 567)가 궁금해졌다.
이 사용자의 특징을 두 가지로 생각해볼 수 있다.
- 겨울왕국을 특별히 재미없게 본 사람
- 전체적으로 영화 평점을 짜게 주는 사람
사용자가 1번인지 2번인지에 따라 완전히 다른 특징의 사람이 되기 때문에, 분석할 가치는 있다.
567번 사용자의 평점에 대한 분포를 보자.
ratings.loc[ratings['userId'] == 567, 'rating'].hist()
<결과>

평점 4, 5점은 많이 없는 것을 보면 1번의 특징을 가진 사용자임을 알 수 있다.
영화 전체 평점의 분포를 보면 차이를 확연히 알 수 있다.
ratings['rating'].hist()
<결과>

근데 평소에 평점을 짜게 주는 사용자임을 감안해도 0.5점은 정말 재미없었나 보다.
'python > data analysis' 카테고리의 다른 글
| [Scikit learn] 학습데이터, 평가 데이터 평균제곱근 편차(RMSE) 계산 (0) | 2021.08.26 |
|---|---|
| [Pandas] concat - 데이터 이어 붙이기 (0) | 2021.08.26 |
| [Pandas] 멱함수 분포 (0) | 2021.08.26 |
| [Pandas] describe(), hist()를 통한 데이터 분석 (0) | 2021.08.26 |
| [Pandas] seaborn - heatmap을 사용한 데이터 상관관계 시각화 (0) | 2021.08.26 |