![[Pandas] get_dummies를 사용한 수치화된 데이터 생성](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FboLNDw%2Fbtrdd4QsGXd%2FjYZIksBIEXY4RIrwDwg2xk%2Fimg.png)
사용 데이터
MovieLens 영화 데이터 -> ml-latest-small.zip -> movies.csv
https://grouplens.org/datasets/movielens/
import pandas as pd
movies = pd.read_csv('[파일 경로]/movies.csv', index_col='movieId')

+) year 컬럼은 title에서 추출하여 따로 추가해둔 상태
장르 데이터 숫자형으로 변경하기
현재 movies 데이터에 genres 컬럼을 살펴보면 한 영화가 여러 장르를 갖고 있다.
따라서 각 영화가 'Adventure' 장르를 갖고 있는지 알기 위해서는
movies['Adventure'] = movies['genres'].apply(lambda x: 'Adventure' in x)
또한 각 영화가 'Comedy' 장르를 갖고 있는지 알기 위해서는
movies['Comedy'] = movies['genres'].apply(lambda x: 'Comedy' in x)
<결과>

이처럼 각 장르의 존재 여부를 True, False로 알 수 있다.
다만 모든 장르에 대해 컬럼을 생성하는 것은 굉장히 비효율적이다.
get_dummies
이를 한 눈에 확인할 수 있게 해주는 함수가 바로 get_dummies이다.
genres_dummies = movies['genres'].str.get_dummies(sep='|')1. 판다스에서 문자열 관련 함수를 사용하거나 전처리를 하기 위해서는 str을 붙여주어야 한다.
2. get_dummies는 genre 데이터를 수치화된 데이터로 바꿔준다.
<결과>
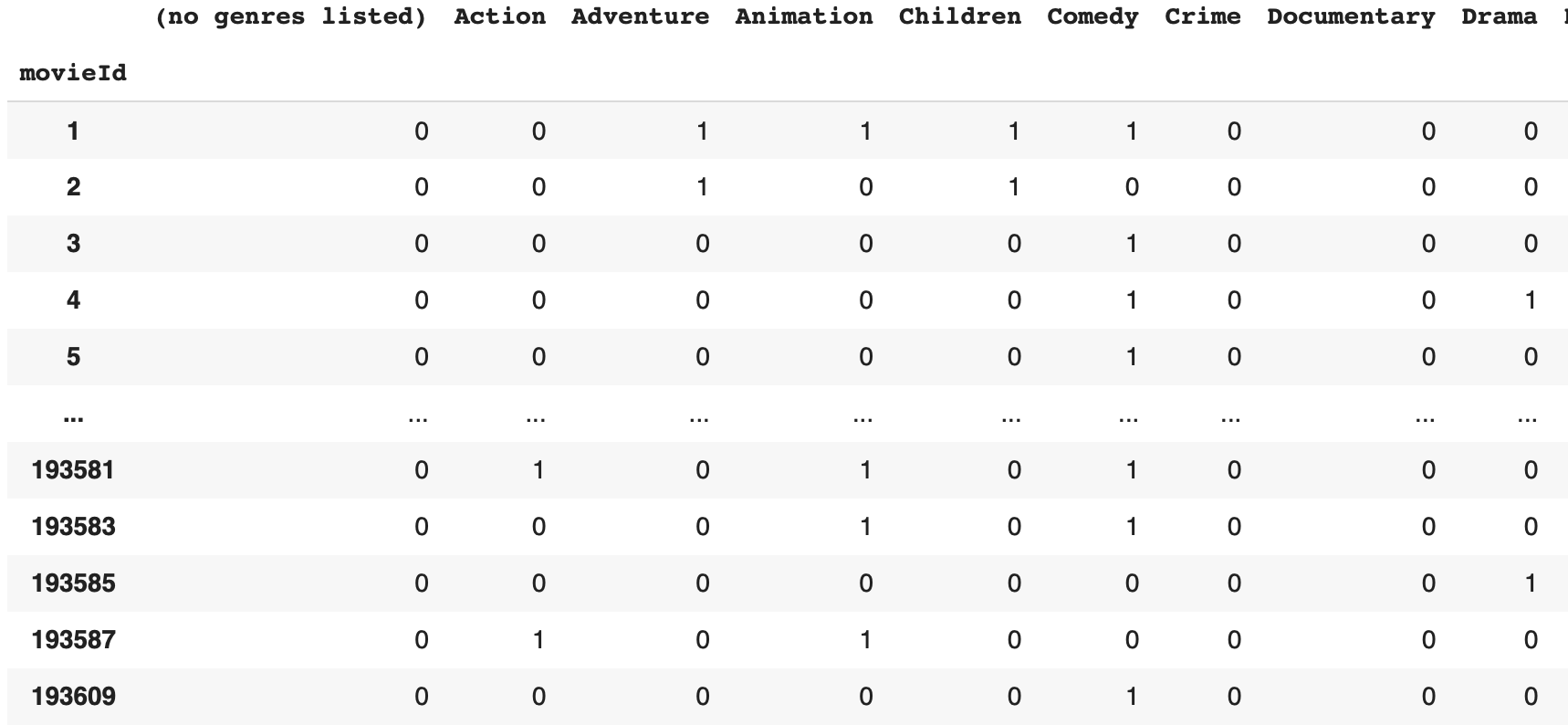
이렇게 각 영화 별로 어떤 장르가 속해있는지 0 또는 1로 한 눈에 확인할 수 있다.
Save pickle
genres_dummies.to_pickle('[파일 경로]/genres.p')이러한 수치화된 파일은 pickle 형식으로 저장해 두면 나중에 재사용하기 좋다.
+) csv와 pickle의 차이
'python > data analysis' 카테고리의 다른 글
| [Pandas] describe(), hist()를 통한 데이터 분석 (0) | 2021.08.26 |
|---|---|
| [Pandas] seaborn - heatmap을 사용한 데이터 상관관계 시각화 (0) | 2021.08.26 |
| [Pandas] apply 함수를 사용한 데이터 분석 (0) | 2021.08.25 |
| [Pandas] seaborn을 사용한 데이터 시각화 (0) | 2021.08.25 |
| [Pandas] str.extract를 사용한 데이터 전처리 + 결측값 핸들링하기 (0) | 2021.08.25 |