![[Pandas] str.extract를 사용한 데이터 전처리 + 결측값 핸들링하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoDwkt%2Fbtrdd43RKot%2FDH5O6iu6ERRiFjZvLVehsK%2Fimg.png)
사용 데이터
MovieLens 영화 데이터 -> ml-latest-small.zip -> movies.csv
https://grouplens.org/datasets/movielens/
import pandas as pd
movies = pd.read_csv('[파일 경로]/movies.csv', index_col='movieId')
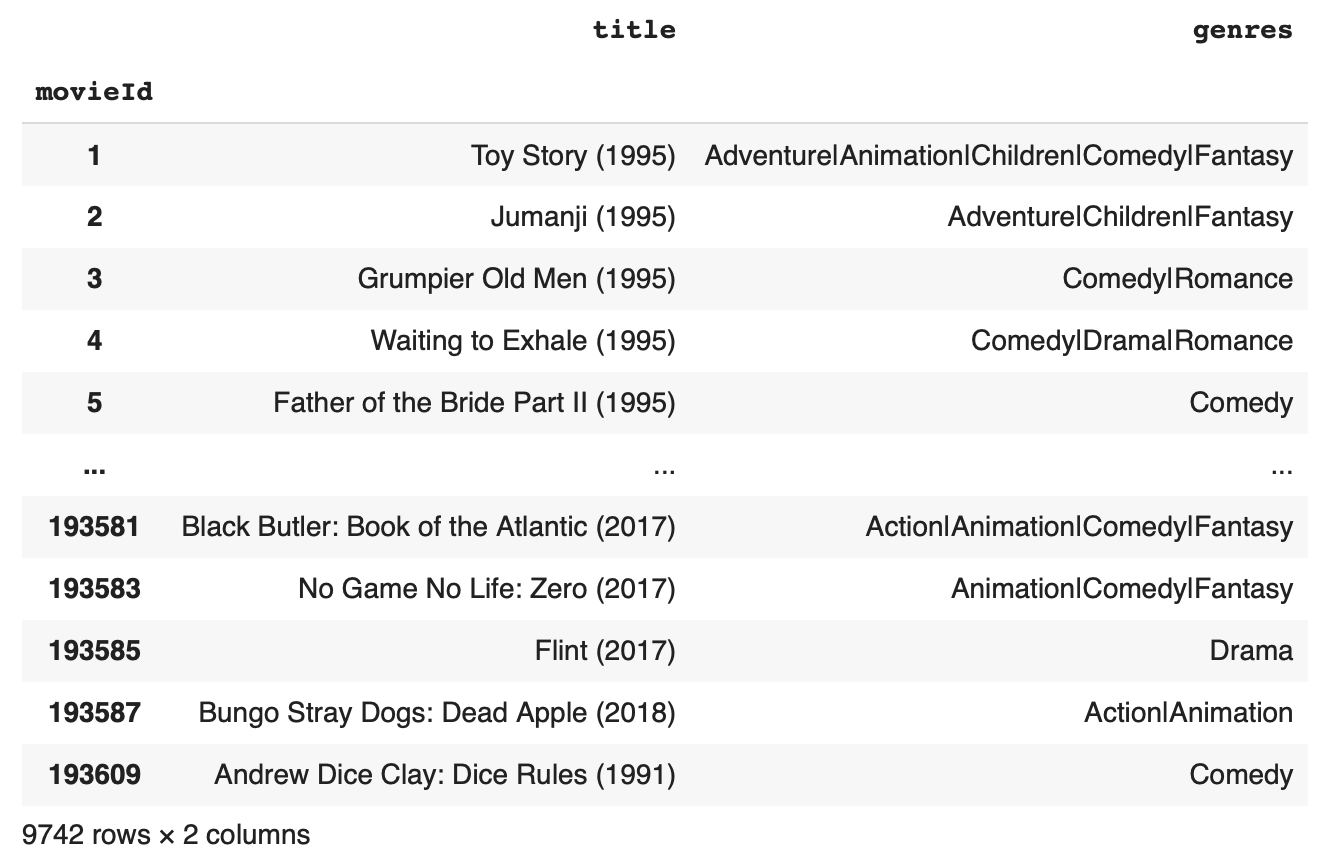
판다스에서 문자열 관련 함수를 사용하거나 전처리를 하기 위해서는 str을 붙여주어야 한다.
그중 원하는 문자열을 추출하는 extract 함수에 대해 알아보겠다.
개봉연도 데이터 정제하기(데이터 전처리, Preprocessing)
movies 데이터의 title에서 괄호 ( ) 안의 연도 4자리를 추출하고 싶을 때, 정규 표현식을 사용하면 편리하다.
movies['year'] = movies['title'].str.extract('(\(\d\d\d\d\))')str.extract('([정규표현식])') <- 바로 이 위치에 추출하고 싶은 문자열의 정규표현식을 대입하면 된다.
바로 숫자 4자리를 추출하지 않는 이유는 [Star Wars 1995]처럼 괄호 안의 연도가 아닌 title 자체에 숫자 4자리가 포함될 수도 있기 때문이다.
우선 (1995) 처럼 괄호를 포함한 연도를 추출하고,
movies['year'] = movies['year'].str.extract('(\d\d\d\d)')추출한 year 컬럼에서 그 안의 연도를 다시 추출한다.
<결과>
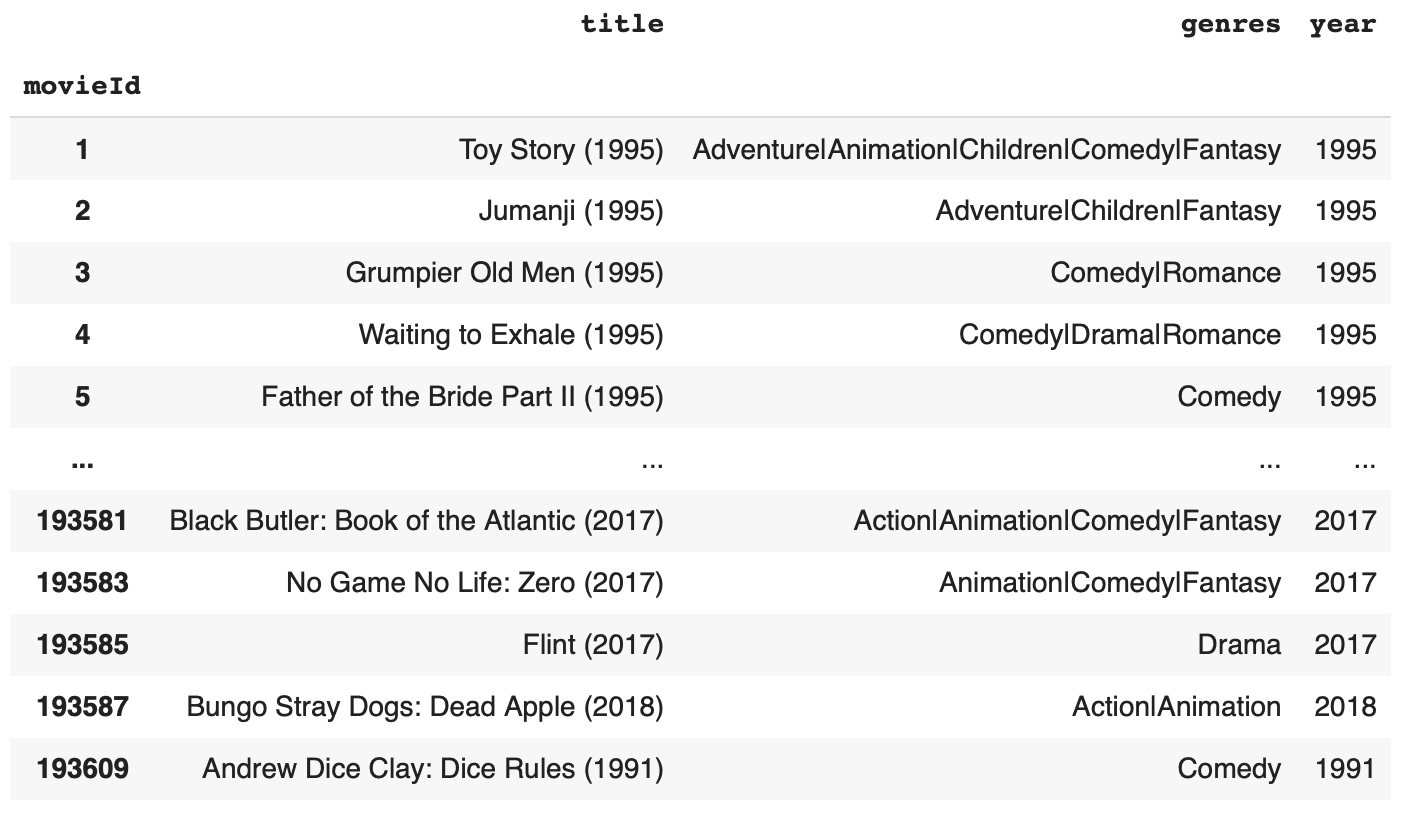
year 컬럼이 정상적으로 추가되었다.
컬럼 목록 보기
movies['year'].unique()어떤 데이터가 추출되었는지 중복 없이 확인할 수 있다.
<결과>
array(['1995', '1994', '1996', '1976', '1992', '1967', '1993', '1964',
'1977', '1965', '1982', '1990', '1991', '1989', '1937', '1940',
'1969', '1981', '1973', '1970', '1955', '1959', '1968', '1988',
'1997', '1972', '1943', '1952', '1951', '1957', '1961', '1958',
'1954', '1934', '1944', '1960', '1963', '1942', '1941', '1953',
'1939', '1950', '1946', '1945', '1938', '1947', '1935', '1936',
'1956', '1949', '1932', '1975', '1974', '1971', '1979', '1987',
'1986', '1980', '1978', '1985', '1966', '1962', '1983', '1984',
'1948', '1933', '1931', '1922', '1998', '1929', '1930', '1927',
'1928', '1999', '2000', '1926', '1919', '1921', '1925', '1923',
'2001', '2002', '2003', '1920', '1915', '1924', '2004', '1916',
'1917', '2005', '2006', '1902', nan, '1903', '2007', '2008',
'2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016',
'2017', '2018', '1908'], dtype=object)
결측값 핸들링하기
year의 목록을 보면 nan이라는 값이 끼어 있는 것을 확인할 수 있다. 이는 결측값으로서 연도가 없는 등의 여러 이유로 인해 연도를 추출할 수 없는 경우를 말한다.
데이터를 처리할 때는 이러한 결측값들을 따로 처리해주는 것이 매우 중요하다.
결측값 확인
# Not a Number, 결측치
movies[movies['year'].isnull()]movies에서 year가 nan인 값만을 확인한다.
<결과>

결측값 처리
movies['year'] = movies['year'].fillna('2050')year가 nan인 값들을 모두 2050으로 채운다.
2050 역시 해당 영화의 개봉연도는 아니지만 적어도 nan 값을 대체하는 것만으로 의미가 있다.
'python > data analysis' 카테고리의 다른 글
| [Pandas] seaborn - heatmap을 사용한 데이터 상관관계 시각화 (0) | 2021.08.26 |
|---|---|
| [Pandas] get_dummies를 사용한 수치화된 데이터 생성 (0) | 2021.08.26 |
| [Pandas] apply 함수를 사용한 데이터 분석 (0) | 2021.08.25 |
| [Pandas] seaborn을 사용한 데이터 시각화 (0) | 2021.08.25 |
| [Pandas] csv 파일 읽기 및 쓰기 (0) | 2021.08.25 |