![[Pandas] seaborn - heatmap을 사용한 데이터 상관관계 시각화](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbZi759%2FbtrdaFDGJsV%2FrxOwpn9k5q7ugaWWtm52MK%2Fimg.png)
사용 데이터
MovieLens 영화 데이터 -> ml-latest-small.zip -> movies.csv
https://grouplens.org/datasets/movielens/
import pandas as pd
movies = pd.read_csv('[파일 경로]/movies.csv', index_col='movieId')
genres_dummies = movies['genres'].str.get_dummies(sep='|')
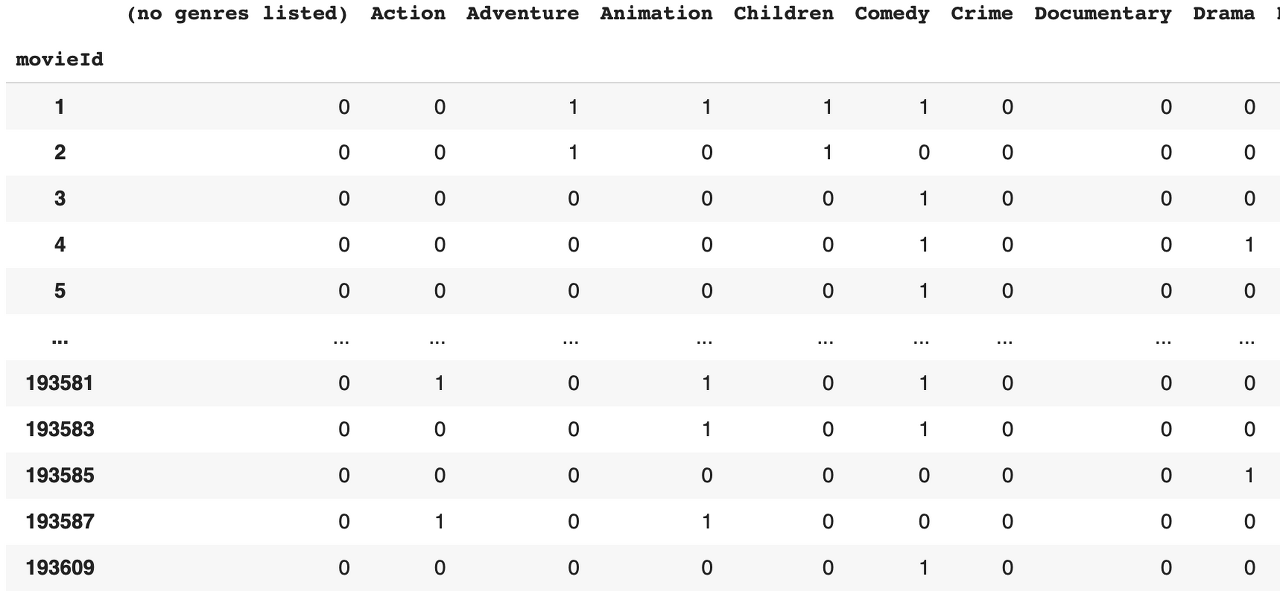
영화 별로 어떤 장르에 속하는지에 대한 데이터
corr()
genres_dummies.corr()데이터의 상관관계를 알 수 있다.
<결과>
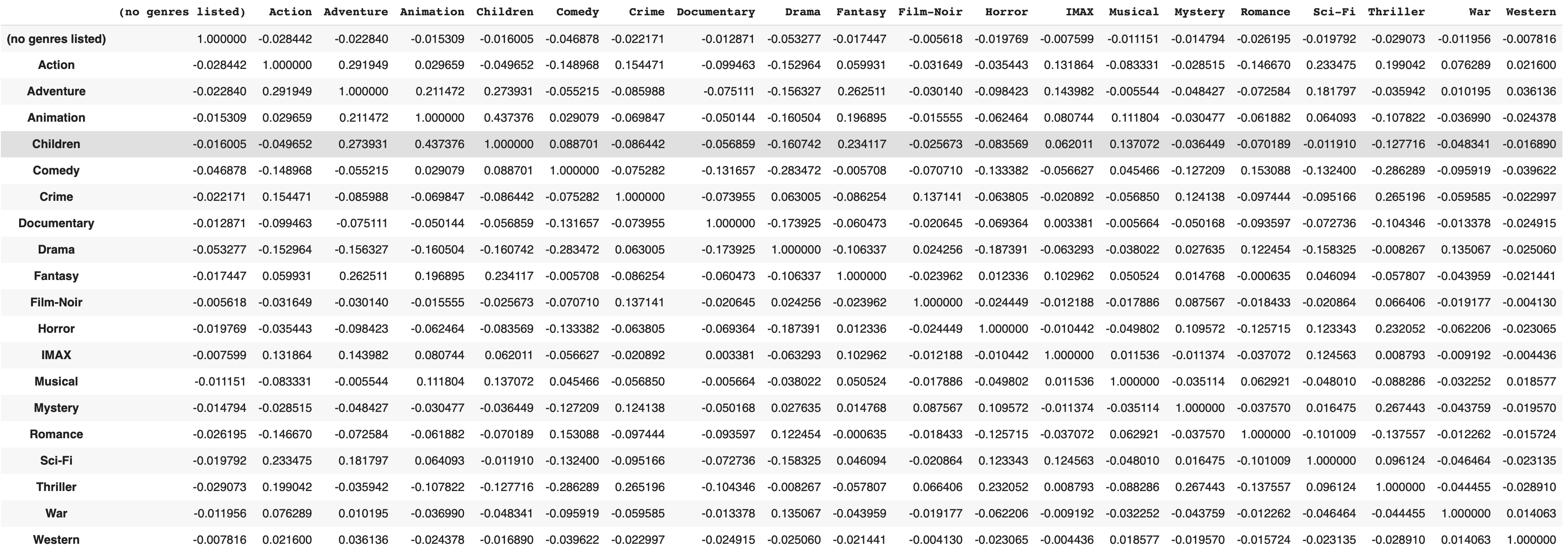
각 장르별 상관관계를 상관계수로서 표현한다.
두 장르의 관계가 1에 가깝다는 것은: 두 장르가 자주 같이 출현한다는 것
두 장르의 관계가 -1에 가깝다는 것은: 두 장르가 아주 드물게 출현 혹은 겹치는 영역이 없다는 것
-> 장르 A와 장르 B의 상관관계: 어떤 영화가 장르 A를 갖고 있을 때, 장르 B도 갖고 있는 정도를 의미한다.
seaborn - heatmap
앞선 출력 데이터가 보기 어려우니 이를 시각화해보자.
Seaborn은 matplotlib 기반의 파이썬 시각화 라이브러리이다.
matplotlib보다 쉽고, 직관적으로 시각화를 할 수 있어서 데이터 분석가들에게 인기가 좋다.
User guide and tutorial — seaborn 0.11.2 documentation
seaborn.pydata.org
%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt # seaborn figure 크기 조절을 위해서seaborn 라이브러리를 import한다.
plt.figure(figsize=(30, 15))
sns.heatmap(genres_dummies.corr(), annot=True)먼저 그래프의 size를 설정한다.
seaborn 라이브러리 중 데이터 상관관계를 보기 좋은 heatmap이라는 도구를 사용할 것이다.
<결과>

+) annot=True 옵션은 데이터의 색 뿐만 아니라 수치도 함께 보여주는 옵션이다.
'python > data analysis' 카테고리의 다른 글
| [Pandas] 멱함수 분포 (0) | 2021.08.26 |
|---|---|
| [Pandas] describe(), hist()를 통한 데이터 분석 (0) | 2021.08.26 |
| [Pandas] get_dummies를 사용한 수치화된 데이터 생성 (0) | 2021.08.26 |
| [Pandas] apply 함수를 사용한 데이터 분석 (0) | 2021.08.25 |
| [Pandas] seaborn을 사용한 데이터 시각화 (0) | 2021.08.25 |