![[자바 최적화] 자바 언어의 성능 향상 기법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F6Xe2U%2FbtsxkhKf9h6%2FJf6Cq6FIvpJkgQoz4XnJsk%2Fimg.png)
자바 최적화 책 정리
자바 최적화(Optimizing Java) | 벤저민 J. 에번스 - 교보문고
자바 최적화(Optimizing Java) | 자바 애플리케이션 성능을 한 단계 높여줄 튜닝 이야기성능 튜닝은 실험과학이다. 추측과 구전 튜닝에 의존할 일이 아니다. 이 책은 복잡한 기술 스택을 다루는 중/고
product.kyobobook.co.kr
컬렉션 최적화
✅ 자바 최적화의 한계
자바는 객체를 생성하면 객체를 가리키는 레퍼런스와(스택), 객체 자체(힙)를 따로 저장한다.
-> 이렇게 레이아웃을 나누는 방식은 C/C++ 형식의 배열이나 벡터를 사용하는 것만큼 성능을 얻을 수 없게 한다.
✅ 자바 컬렉션
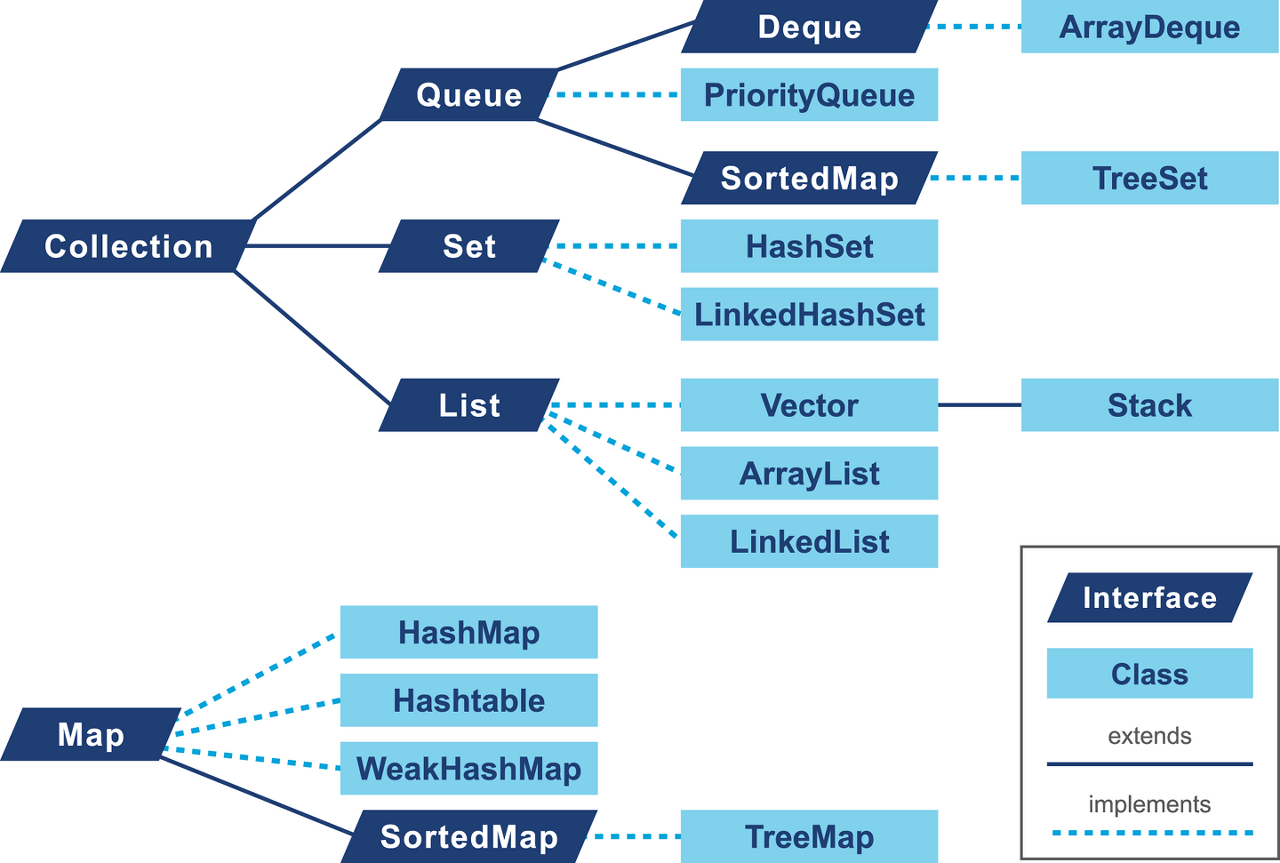
컬렉션이 애플리케이션 성능에 전체적인 영향을 끼칠 수 있다는 사실을 인식해야 한다.
List 최적화
ArrayList
✅ 고정 크기 배열에 기반한 리스트
ArrayList는 배열 최대 크기만큼 원소를 추가할 수 있고, 꽉차면 더 큰 배열을 새로 할당한 다음 기존 값을 복사한다.
-> 크기 조정 작업과 유연성을 잘 저울질해야 한다.
ArrayList에 초기 용량값을 설정하지 않으면 처음에 빈 배열로 시작하고 원소가 추가될 때 용량 10인 기반 배열을 할당한다.
-> 초기 용량값을 생성자에 전달하면 이렇게 크기 조정을 안해도 된다.
JMH 벤치마크로 확인해보자.
@Benchmark
public List<String> properlySizedArrayList() {
List<String> list = new ArrayList<>(1_000_000);
for (int i = 0; i < 1_000_000; i++) {
list.add(item);
}
return list;
}
@Benchmark
public List<String> properlySizedArrayList() {
List<String> list = new ArrayList<>();
for (int i = 0; i < 1_000_000; i++) {
list.add(item);
}
return list;
}
<결과>
Benchmark Mode Cnt Score Error Units
ResizingList.properlySizedArrayList thrpt 10 287.388 ± 7.135 ops/s
ResizingList.resizingArrayList thrpt 10 189.510 ± 4.530 ops/s-> properlySizedArrayList 테스트가 원소 추가 작업을 초당 약 100회 더 처리했다.
-> ArrayList 크기를 정확히 결정하고 시작하는 게 성능은 더 낫다.
LinkedList
✅ 동적으로 증가하는 리스트
이중 연결 리스트로 구현되어 있어서 리스트에 덧붙이는 작업은 항상 O(1)이다.

ArrayList vs LinkedList
✅ 데이터 추가/삭제
ArrayList는 특정 인덱스에 원소를 추가하려면 다른 원소들을 모두 한 칸씩 우측으로 이동시켜야 한다.
LinkedList는 삽입 지점을 찾기 위해 노드 레퍼런스를 따라가는 수고는 있지만, 삽입 작업은 간단히 끝난다.
다음은 두 리스트 타입의 시작부에 원소 추가 시 성능을 비교한 벤치마크 결과다.
Benchmark Mode Cnt Score Error Units
InsertBegin.beginArrayList thrpt 10 3.402 ± 0.239 ops/ms
InsertBegin.beginLinkedList thrpt 10 559.570 ± 68.629 ops/ms-> 원소 삭제도 비슷한 개념으로 동작한다.
✅ 데이터 액세스
ArrayList는 모든 원소를 O(1) 시간 만에 가져올 수 있다.
LinkedList는 처음부터 인덱스 카운트만큼 원소를 방문해야 한다.
다음은 두 리스트 타입의 액세스 성능을 비교한 벤치마크 결과다.
Benchmark Mode Cnt Score Error Units
AccessingList.accessArrayList thrpt 10 269568.627 ± 12972.927 ops/ms
AccessingList.accessLinkedList thrpt 10 0.863 ± 0.030 ops/ms
✅ 결론
LinkedList 고유 기능이 꼭 필요한 경우가 아니라면,
특히 랜덤 액세스가 필요한 알고리즘을 구사할 때는
-> ArrayList를 권장한다.
-> 또한, 가급적 미리 크기를 지정해서 중간에 다시 조정하는 일이 없도록 하는 게 좋다.
Map 최적화
HashMap
✅ 해시값(key)으로 값을 조회하는 맵
특정 key로 값을 찾으려면?
public Object get(Object key) {
// 편의상 널 키는 지원하지 않음
if (key == null) return null;
int hash = key.hashCode();
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
private int indexFor(int h, int length) {
return h & (length-1);
}1. key.hashCode(): key의 hasCode 값을 계산한다.
2. indexFor(): 해시코드를 해시버킷배열의 인덱스로 변환한다 -> 해시코드를 해시맵 내부 배열이 크기에 맞게 조절하는 역할을 한다.
3. 엔트리 반복: 해시버킷배열 내 인덱스에 해당하는 버킷에서 실제 key에 대한 value를 찾기 위해 반복문을 시작한다.
-> 해시버킷은 리스트 형태: 메모리 절약을 위해 같은 해시코드에 대한 key가 여러개일 수 있기 때문(해시 충돌)
4. 엔트리 비교: 현재 엔트리의 해시코드와 키가 일치한다면 해당 엔트리의 값을 반환한다.
-> key는 동일성, 동등성 비교를 모두 하기 때문에 key 중복은 없다.
✅ 해시 충돌 개선
자바 최근 버전에서는,
기존 indexFor() 메서드를 hash()라는 보조 해시 함수(key의 hashCode를 변형)로 대체하고,
최대한 해시 충돌을 줄이고자 했다.
✅ HashMap의 매개변수
HashMap 생성자에 전달하는 initialCapacity와 loadFactor는 HashMap 성능에 가장 큰 영향을 미친다.
- initialCapacity: 현재 생성된 버킷 개수(디폴트 16)
- loadFactor: 버킷 용량을 자동 증가(2배)시키는 한계치(디폴트 0.75: 현재 버킷 개수의 75%가 차면 버킷을 2배로 늘린다)
-> ArrayList와 마찬가지로 저장할 데이터 양을 미리 알 수 있다면 initialCapacity를 설정하면 좋다.
-> loadFactor 0.75(디폴트) 정도면 공간과 접근 시간의 균형이 대략 맞아서 조정하지 않아도 된다.
✅ 트리화
기본적으로 해시 버킷의 자료구조는 LinkedList인데,
이는 원소가 추가될수록 조회 비용이 증가한다.
최신 HashMap에서는 TREEIFY_THRESHOLD에 설정한 개수만큼 원소가 모이면 버킷을 TreeNode로 바꿔버린다.
(TreeMap처럼 동작)
Q: 그럼 처음부터 바꾸면 안될까?
A: TreeNode는 리스트 노드보다 약 2개 더 커서 그만큼 공간을 더 차지한다. 원소의 개수가 적을 때는 LinkedList가 공간 효율적이다.
✅ LinkedHashMap
HashMap의 서브 클래스로, 이중 연결 리스트를 사용해 원소의 삽입 순서를 관리한다.
-> Map을 사용하는 코드에서는 대부분 삽입/접근 순서가 별로 중요하지 않기 때문에 사용할 일은 비교적 드문 편이다.
TreeMap
✅ 레드-블랙 트리를 구현한 맵
레드-블랙 트리는 기본 이진 트리 구조에서 트리 균형이 한쪽으로 치우치는 현상을 방지한 트리다.
TreeMap은 get, put 등 메서드의 log(n) 성능을 보장하며,
서브맵에 신속히 접근할 수 있어 데이터를 분할하는 용도로도 쓰인다.
-> 실제로 대부분의 요건은 HashMap만으로도 충분하지만,
-> 스트림이나 람다로 Map의 일부를 처리하는 경우, 데이터 분할이 주특기인 TreeMap을 사용하는 것이 바람직하다.
MultiMap은 없어요
✅ 하나의 키에 여러 값을 묶은 맵
공식문서에는 MultiMap을 쓸 일이 드물고, 대부분 Map<K, List<V>> 형태로도 충분히 구현 가능하기에 지원하지 않는다고 한다.
Set
✅ 고려할 사항은 Map과 비슷하다
HashSet은 HashMap으로 구현되어 있다.
+) LinkedHashSet은 LinkedHashMap으로 구현되어 있다. (Map에 삽입한 순서 보장)
-> 삽입/삭제는 O(1)이다.
TreeSet 역시 TreeMap을 활용한다. (삽입 순서와 상관 없이 원소 자체 순서 보장 -> Comparator에 정의)
-> 삽입/삭제는 log(n)이다.
도메인 객체
✅ 도메인 객체 메모리 누수
jmap -histo 등의 명령을 통해 자바 힙 상태를 살펴보면,
보통 메모리 점유량은 코어 JDK에 있는 자료 구조가 상위권을 형성한다.
-> 만약 도메인 객체가 상위 30위 정도 안에 든다면, (꼭 그렇다고 단정 지을 순 없지만) 메모리 누수가 발생한 신호일 수 있다.
✅ 전체 세대 도메인
만약 세대 카운트별 바이트 히스토그램을 찍어봤을 때,
도메인 객체가 전체 세대에 걸쳐(영-테뉴어드) 분포한다면 누수를 일으킬 가능성이 있다.
-> 일단 도메인 객체에 대응되는 데이터셋의 크기를 살피고 그 수치가 온당한지 확인한다.
✅ 부유 가비지
한편, 단명 도메인 객체 역시 부유 가비지(아무도 참조하지 않는데 혼자 남아있는 객체)를 일으키는 원인이 될 수 있다.
-> 동시 수집기의 SATB 기법: 얼마나 짧게 살다 가든지, 마킹 사이클 시작 이후 할당된 객체는 모두 살아 있는 것으로 간주.
종료화 안 하기
무용담: 정리하는 걸 깜빡하다
✅ 책의 저자의 무용담(?)
수년간 문제 없이 돌아가던 운영계 코드를 변경했다가, 응답이 매우 느려지는 현상 발견
-> 원인은 TCP 접속 오픈 이후, close() 함수를 깜빡 잊고 놓친 것. (리소스를 정리하는 것은 매우 중요하다)
왜 종료화로 문제를 해결하지 않을까?
✅ 자바의 finalize() 메서드
Object 클래스에 정의되어 있는 finalize()를 서브 클래스에서 재정의한다.
객체가 GC 대상일 때, 그 객체에 있는 finalize() 메서드를 호출한다.
-> finalize()는 시스템 리소스를 처분하는 등 기타 정리 작업을 수행한다.
✅ 문제 1: GC가 finalize()를 만났을 때
finalize()를 오버라이드한 객체는 GC가 특별하게 처리한다.
- 종료화가 가능한 객체는 큐로 이동한다.
- 애플리케이션 스레드 재시작 후, 별도의 종료화 스레드가 큐를 비우고 각 객체마다 finalize() 메서드를 실행한다.
- finalize()가 종료되면 객체는 다음 사이클에 진짜 수집될 준비를 마친다.
-> 이는 종료화 가능한 객체는 적어도 한 번의 GC 사이클은 더 보존된다는 뜻이고, 테뉴어드 객체의 경우 상당히 긴 시간이 될 수 있다.
✅ 문제 2: finalize()에서 예외가 발생했을 때
아무런 컨텍스트가 없기 때문에 예외는 그냥 무시된다.
✅ 문제 3: 별도 스레드 생성
종료화를 구현한 코드는 JVM이 스레드를 하나 더 만들어 finalize() 메서드를 실행해야 한다.
-> 새 스레드를 생성하는 오버헤드를 감수해야 한다.
✅ 문제 4: C++과 다른 메모리 관리
C++은 해체자와 같은 자바의 finalize 역할을 하는 메서드가 있다.
그러나 C++은 어디까지나 프로그래머가 직접 객체 수명을 명시적으로 관리하는 체제이다.
-> 객체 수명과 리소스 획득/해제가 단단이 엮여 있다.
그에 반해 자바의 GC는 언제 일어날지 아무도 모르기 때문에, finalize()도 언제 실행될지 알 길이 없다.
-> 객체 수명과 리소스 획득/해제가 무관하다.
-> 종료화를 통해 자동으로 리소스를 관리한다는 것 자체가 어불성설이다.
✅ 결론: 종료화를 사용하지 말자
오라클은 애플리케이션 코드에 종료화를 사용하지 말라고 개발자들에게 권고해왔다.
-> 자바 9부터 Object.finalize()는 디프리케이드됐다.
try-with-resources
✅ 자바 7 이전
자바 7 이전에는 리소스를 닫는 일은 순전히 개발자의 몫이었다.
-> 따라서 깜빡하는 경우가 있다.
public void readFirstLineOld(File file) throws IOException {
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String firstLine = reader.readLine();
System.out.println(firstLine);
} finally {
if (reader != null) {
reader.close();
}
}
}
✅ 자바 7 이후
자바 7 이후부터 try 괄호 안에 리소스를 지정해서 생성하면, try 블록이 끝나는 지점에 close() 메서드를 예외 발생 여부와 상관없이 호출한다.
public void readFirstLineNew(File file) throws IOException {
try (BufferedReader reader = new BufferedReader(new FileReader(file))) {
String firstLine = reader.readLine();
System.out.println(firstLine);
}
}
✅ finalize() vs try-with-resources
finalize(): 런타임 기반, 특별한 GC 사용, 별도 종료화 스레드 동원.
-> GC에 의존 -> 객체 수명과 리소스 관리를 엮기 힘듬
try-with-resources: 컴파일 기반 -> 컴파일 시 리소스 close() 관련 코드가 알아서 생성됨.
-> 앵간하면 try-with-resources 사용하자.
메서드 핸들
✅ invokedynamic
자바 7부터 선보인 JVM에서 사용되는 바이트코드 명령어.
주로 런타임 코드 생성에 사용된다.
ex) 호출부가 어느 메서드를 호출할지 런타임에 결정한다.
호출부가 인터프리터에 이르면 부트스트랩 메서드(BSM, 보조메서드)가 호출되고,
BSM은 호출부에서 호출됐어야 할 실제 메서드를 가리키는 객체를 반환한다.
-> 이 객체를 "호출 대상"이라고 하며, 호출부 내부에 "가미됐다"고 표현한다.
✅ 메서드 핸들의 장점
메서드 핸들은 invokedynamic 호출부에 의해 호출되는 메서드를 나타낸 객체다.
리플렉션과 어느 정도 개념이 비슷하지만, 리플렉션은 자체 한계 때문에(성능, 안정성 등) invokedynamic과 더불어 사용하기 불편하다.
ex) 리플렉션 예시
Method m = ...
Object receiver = ...
Object o = m.invoke(receiver, new Object(), new Object());이를 바이트코드로 컴파일 해보면, 전체 호출 시그니처는 "invoke:(Ljava/lang/Object;[Ljava/lang/Object;)Ljava/lang/Object;" 다.
이는, Obejct 인수와 Object를 반환하므로, 컴파일 타임에는 이 메서드가 어떻게 호출될지 전혀 가늠할 길이 없다.
-> 런타임 직전까지 모든 가능성을 찔러보다가 매개변수 목록에 조금이라도 오류가 생기면 런타임에 실패할 가능성이 크다.
ex) 메서드 핸들 예시
MethodType mt = MethodType.methodType(int.class);
MethodHandles.Lookup l = MethodHandles.lookup();
MethodHandle mh = l.findVirtual(String.class, "hashCode", mt);
String receiver = "b";
int ret = (int) mh.invoke(receiver);
System.out.println(ret);MethodHandles.lookup(): 룩업 컨텍스트 생성, 컨텍스트 객체를 생성한 시점에 접근 가능한 메서드 및 필드를 기록한 상태 정보가 있다.
findVirtual(): 컨텍스트를 생성한 시점부터 보이는 모든 메서드의 핸들을 가져올 수 있다 -> hasCode() 메서드를 룩업.
invoke(): 리플렉션처럼 invoke() 호출이 모든 인수를 두루 받아들이는 만능 호출 대신, 런타임에 호출돼야 할 예상 시그니처를 기술한다.
-> 실제로 바이트코드를 살펴보면, 호출 시그니처가 "invoke:(Ljava/lang/String;)I" 다.
'book > 자바 최적화' 카테고리의 다른 글
| [자바 최적화] JIT 컴파일의 세계로 (0) | 2023.09.20 |
|---|---|
| [자바 최적화] JVM의 코드 실행 (0) | 2023.09.11 |
| [자바 최적화] GC 로깅, 모니터링, 튜닝, 툴 (0) | 2023.09.05 |
| [자바 최적화] 가비지 수집 고급 (0) | 2023.08.29 |
| [자바 최적화] 가비지 수집 기초 (2) | 2023.08.28 |