![[자바 최적화] JIT 컴파일의 세계로](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbvAUw1%2FbtsuQSL2Mml%2FDbwEiRcwTD5YQ07jR5Ye6k%2Fimg.png)
자바 최적화 책 정리
자바 최적화(Optimizing Java) | 벤저민 J. 에번스 - 교보문고
자바 최적화(Optimizing Java) | 자바 애플리케이션 성능을 한 단계 높여줄 튜닝 이야기성능 튜닝은 실험과학이다. 추측과 구전 튜닝에 의존할 일이 아니다. 이 책은 복잡한 기술 스택을 다루는 중/고
product.kyobobook.co.kr
JITWatch란?
✅ JITWatch
이 책의 필자 중 한 사람인 크리스 뉴랜드가 개인 프로젝트로 구축한 오픈 소스 자바FX 툴.
-> 실행 중인 자바 애플리케이션이 생성한 핫스팟 컴파일 상세 로그를 파싱/분석하여 그 결과를 자바FX GUI 형태로 보여준다.
-> 애플리케이션을 실행할 때 다음 플래그를 추가해야 JVM이 JITWatch에 입력할 로그를 생성한다.
-XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+LogCompilation
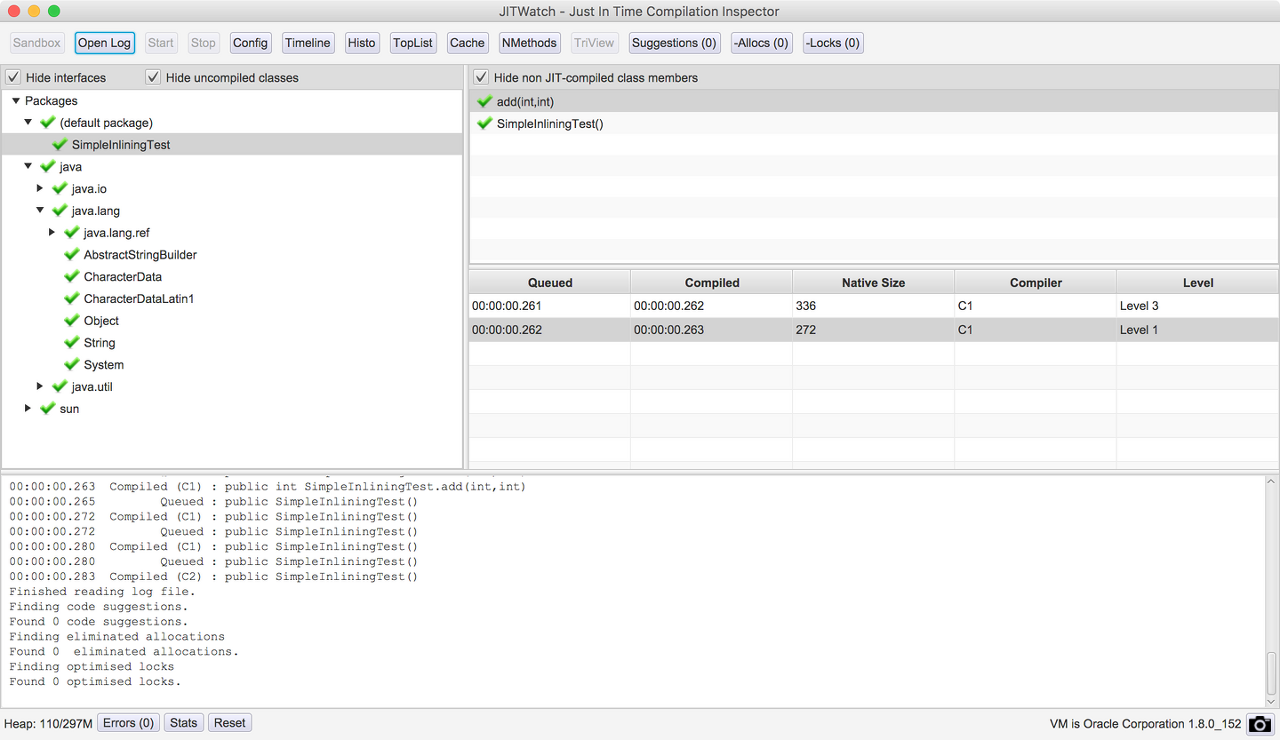
기본적인 JITWatch 뷰
✅ 메인 창
애플리케이션을 실행해서 JITWatch를 시동한 다음, 로그를 로드하면 다음과 같은 뷰가 펼쳐진다.
✅ 샌드박스
JITWatch는 로그를 적재하는 일뿐만 아니라, JIT 작동을 시험해볼 수 있는 샌드박스라는 환경을 제공한다.
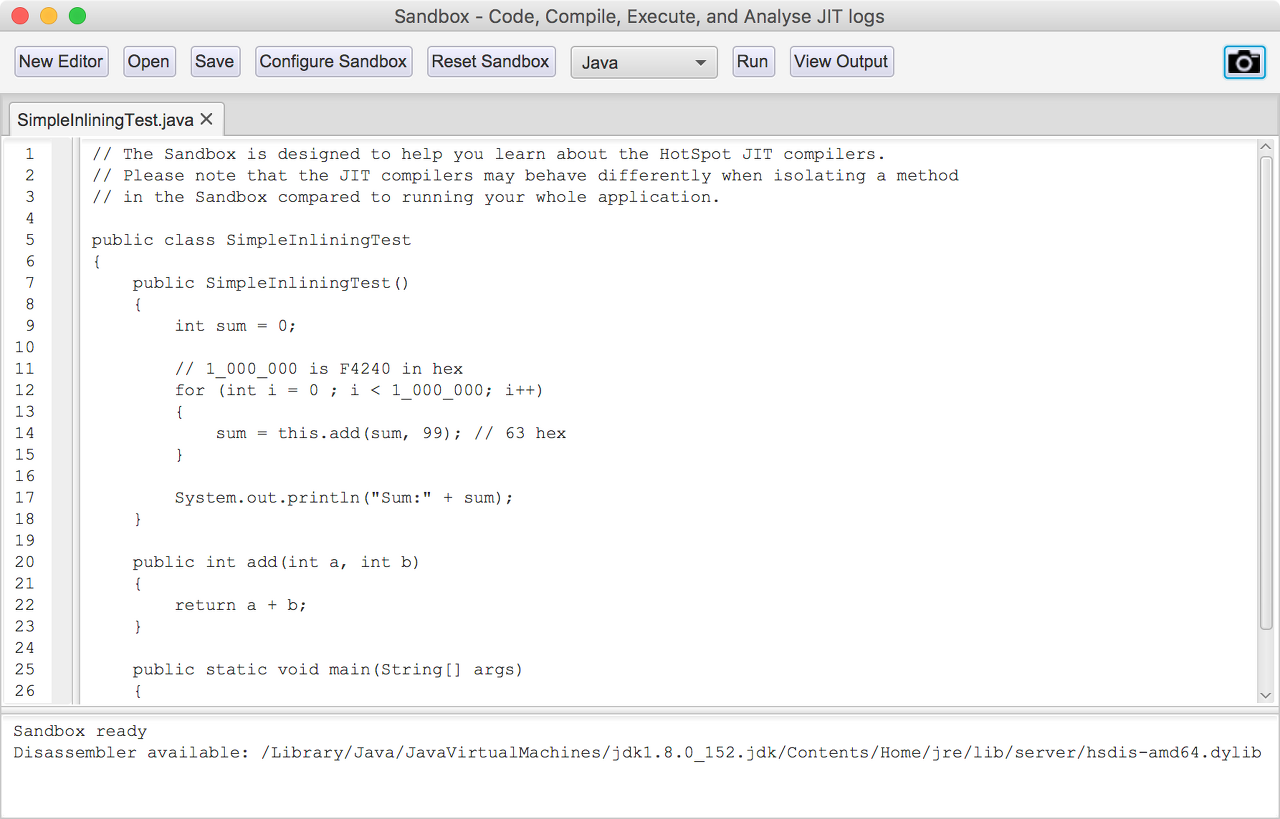
Run 버튼을 클릭하면 다음 작업이 수행된다.
- 프로그램을 바이트코드로 컴파일한다.
- JIT 로그를 켜 놓고 JVM에서 프로그램을 실행한다.
- 분석용 JIT 로그파일을 JITWatch에 로드한다.
또한, 샌드박스는 JIT를 조정하는 VM 스위치를 시험해볼 수 있는 환경을 제공한다.
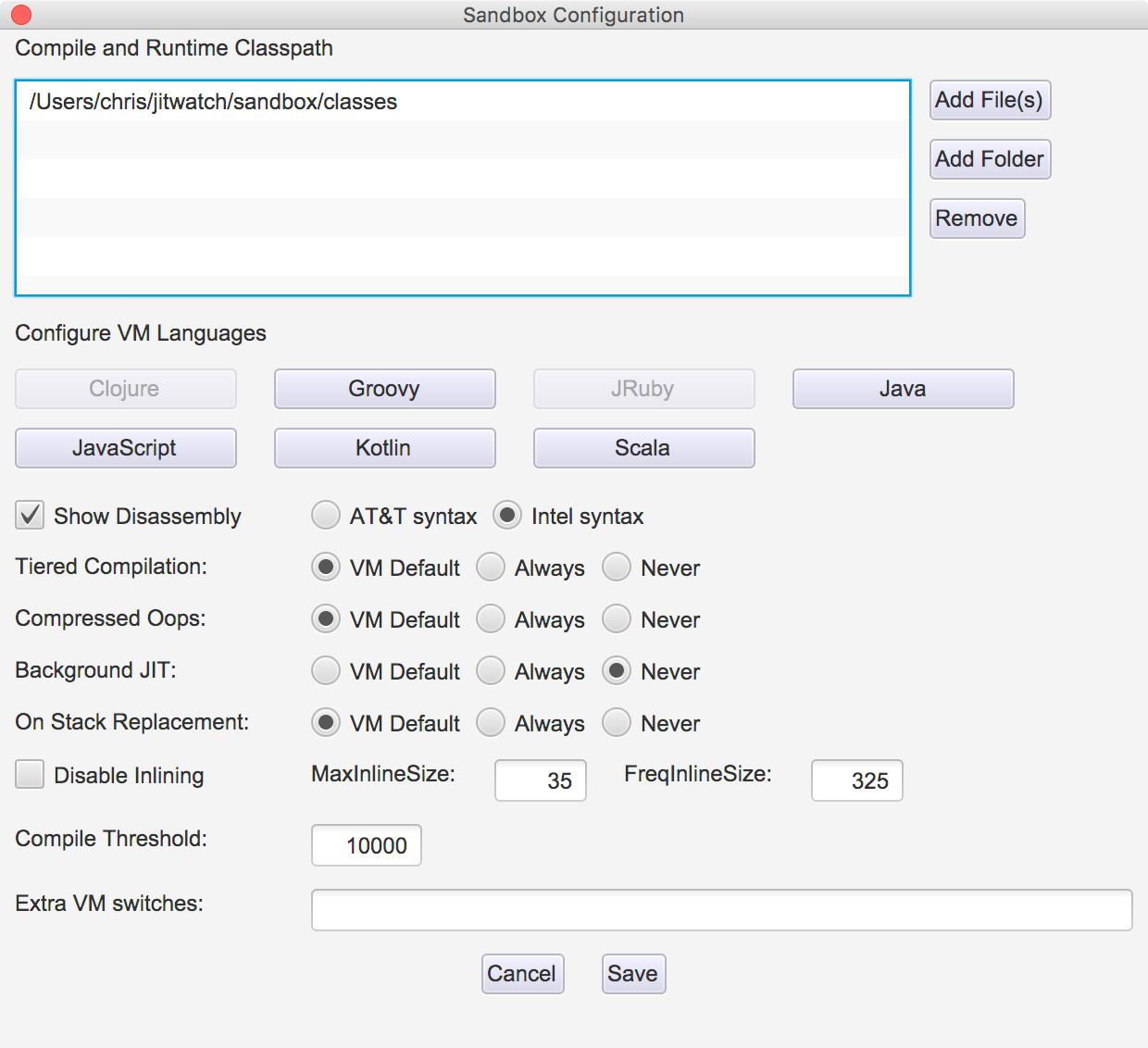
ex)
- 역어셈블리 네이티브 메서드를 특정 구문에 따라 출력한다.
- C1/C2를 사용하는 단계별 컴파일에 대한 디폴트를 오버라이드한다.
- 압축 oop 사용을 오버라이드한다.
- OSR을 해제한다.
- 인라이닝 디폴트 한계치를 오버라이드한다.
디버그 JVM과 hsdis
✅ 디버그 JVM
운영 JVM보다 더 상세한 디버깅 정보를 추출하려고 제작한 가상 머신.
-> 그만큼 성능 희생은 감수해야 한다.
✅ hsdis
JIT 컴파일러가 생성한, 역어셈블된 네이티브 코드를 살펴보기 위한 바이너리.
참고: hsdis 빌드하기
VM에서 메서드 어셈블리를 출력하려면 다음 스위치를 추가한다.
-XX:+PrintAssembly
JIT 컴파일 개요
✅ 메서드 데이터 객체(MDO)
핫스팟이 실행 프로그램 정보를 저장하는 구조체.
-> 인터프리터와 C1 컴파일러에서 JIT 컴파일러 최적화를 결정하는 데 필요한 정보를 기록한다.
ex) 어떤 메서드가 얼마나 호출됐는지에 대한 정보
✅ 컴파일
이렇게 프로파일링 데이터가 모이고 컴파일 결정을 내린 후엔,
컴파일할 코드의 내부 표현형(ex. 바이트코드)을 빌드한다.
컴파일러는 다양한 최적화 기법을 총동원한다.
- 인라이닝
- 루프 펼치기
- 탈출 분석
- 락 생략/확장
- 단일형 디스패치
- 인트린직
- 온-스택 치환
-> 다음 절부터 하나씩 설명한다.
✅ C1 vs C2
C1은 추측성 최적화를 하지 않는다.
-> 확실하지 않으면 최적화를 하지 않는다.
C2는 런타임 실행의 결과를 토대로 추정을 하고 그에 따른 최적화를 한다.
-> 추정이어서 적잖은 성능 향상 효과를 볼 때도 있고, 추정한 것과 엉뚱하게 흘러가 무용지물이 되는 경우도 있다.
-> 후자 상황을 대비해, 최적화된 코드를 실행할 때마다 '가드(guard)'라는 타당성 검사를 한다.
-> 가드가 실패하면 컴파일드 코드는 인터프리티드 모드로 강등시켜 역최적화한다.
인라이닝
✅ 관문 최적화
JIT 컴파일러가 제일 먼저 적용하는 최적화.
-> 호출된 메서드(피호출부)의 콘텐츠를 호출한 지점(호출부)에 복사하는 것이다.
인라이닝 제한
✅ 인라이닝 제한을 걸어야 하는 경우
- JIT 컴파일러가 메서드를 최적화하는 데 소비하는 시간
- 생성된 네이티브 코드 크기(즉, 코드 캐시 메모리 사용량)
✅ 핫스팟이 인라이닝을 결정하는 기준
- 인라이닝할 메서드의 바이트코드 크기
- 현재 호출 체인에서 인라이닝할 메서드의 깊이
- 메서드를 컴파일한 버전이 코드 캐시에서 차지하는 공간
인라이닝 서브시스템 튜닝
✅ 인라이닝 튜닝 관련 JVM 스위치
| 스위치 | 디폴트 (JDK 8, Linux x86_64) |
설명 |
| -XX:MaxInlineSize=<n> | 35바이트의 바이트코드 | 메서드를 이 크기 이하로 인라이닝한다. |
| -XX:FreqInlineSize=<n> | 325바이트의 바이트코드 | (자주 호출되는) '핫' 메서드를 이 크기 이하로 인라이닝한다. |
| -XX:InlineSmallCode=<n> | 1,000바이트의 네이티브 코드(단계 없음) 2,000바이트의 네이티브 코드(단계 있음) |
코드 캐시에 이 수치보다 더 많은 공간을 차지한 최종 단계 컴파일이 이미 존재할 경우 메서드를 인라이닝하지 않는다. |
| -XX:MaxInlineLevel=<n> | 9 | 이 수준보다 더 깊이 호출 프레임을 인라이닝하지 않는다. |
루프 펼치기
✅ 루프 내부의 메서드 호출을 인라이닝
루프 내부의 메서드 호출을 전부 인라이닝 하면, 루프를 순회할 때의 비용을 줄일 수 있다.
✅ 배열 경계 검사
배열 인덱스 변수가 배열 경계 내에 있는지 확인하는 작업.
인덱스 변숫값과 경계값을 단순 비교하는 일이지만, 순회 횟수만큼 누적되면 그만큼 오버헤드가 발생한다.
| 루프 구역 | 경계 검사? | 설명 |
| 사전 루프 | 예 | 초기 순회는 경계 검사를 한다. |
| 메인 루프 | 아니오 | 루프 보폭을 이용해 경계 검사를 안 해도 순회 가능한 최대 횟수를 계산한다. |
| 사후 루프 | 예 | 나머지 순회는 경계 검사를 한다. |
✅ 핫스팟이 루프 펼치기 여부를 결정하는 기준
- 루프 카운터 변수 유형(대부분 객체 아닌 int나 long형을 사용)
- 루프 보폭 유형(한번 순회할 때마다 루프 카운터 값이 얼마나 바뀌는가)
- 루프 내부의 탈출 지점 개수(return 또는 break)
루프로 순회할 배열을 생성하고,
int형 카운터와 long형 카운터로 순회하면 각각 얼마나 성능이 차이 나는지 JMH 벤치마크로 비교해보자.
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
@State(Scope.Thread)
public class LoopInliningBenchmark {
private static final int MAX = 1_000_000;
private long[] data = new long[MAX];
@Setup
public void createDate() {
Random random = new Random();
for (int i = 0; i < MAX; i++) {
data[i] = random.nextLong();
}
}
@Benchmark
public long intStride1() {
long sum = 0;
for (int i = 0; i < MAX; i++) {
sum += data[i];
}
return sum;
}
@Benchmark
public long longStride1() {
long sum = 0;
for (long l = 0; l < MAX; l++) {
sum += data[(int) l];
}
return sum;
}
}
<결과>
int형 카운터 루프의 처리량이 약 64% 더 높다.
-> 실제 long형 카운터는 루프 바디가 펼쳐지지 않고, 세이브포인트 폴(세이브포인트 도달 여부를 폴링하여 체크하는 코드)이 박힌다.
루프 펼치기 정리
✅ 핫스팟 루프 펼치기 기법
- 카운터가 int, short, char형일 경우 루프를 최적화한다.
- 루프 바디를 펴리고 세이브포인트 폴을 제거한다.
- 루프를 펼치면 백 브랜치 횟수가 줄고 그만큼 분기 예측 비용도 덜 든다.
- 세이브포인트 폴을 제거하면 루프를 순회할 때마다 하는 일이 줄어든다.
탈출 분석
✅ 범위 기반 분석
핫스팟은 어떤 메서드가 내부에서 수행한 작업을 그 메서드 경계 밖에서도 볼 수 있는지 판별한다.
-> 이러한 기법을 탈출 분석이라고 한다.
+) 탈출 분석 최적화는 반드시 인라이닝을 수행한 이후 시도한다. (인라이닝을 하면 호출부 객체는 더 이상 탈출 객체가 아니다)
✅ 탈출 객체 유형
핫스팟의 탈출 객체는 다음과 같이 기술되어 있다.
typedef enum {
NoEscape = 1, // 객체가 메서드/스레드를 탈출하지 않고
// 호출 인수로 전달되지 않으며,
// 스칼라로 대체 가능하다.
ArgEscape = 2, // 객체가 메서드/스레드를 탈출하지 않지만
// 호출 인수로 전달되거나 레퍼런스로 참조되며,
// 호출 도중에는 탈출하지 않는다.
GlobalEscape = 3 // 객체가 메서드/스레드를 탈출한다.
}
힙 할당 제거
✅ 탈출 분석의 목적
할당된 객체가 메서드를 탈출하지 않는다면(NoEscape)
VM은 스칼라 치환이라는 최적화를 적용해 객체 필드를 마치 지역 변수인 스칼라 값으로 바꾼다.
그런 다음 레지스터 할당기에 의해 CPU 레지스터 속으로 배치된다.
-> 탈출 분석의 목표는 바로 힙 할당을 막을 수 있는지 추론하는 것이다.
-> 만약 그럴 수 있다면, 객체는 스택에 자동 할당되고 GC 압박을 조금이나마 덜 수 있다.
✅ 힙 할당 제거 예시
다음은 NoEscape한 코드의 예시이다.
public long noEscape() {
long sum = 0;
for (int i = 0; i < 1_000_000; i++) {
MyObj foo = new MyObj(i); // foo는 메서드를 탈출하지 않음(NoEscape)
sum += foo.bar();
}
return sum;
}
다음은 ArgEscape한 코드의 예시이다.
-> 그러나 탈출 분석 직전, extBar()이 루프 바디 안으로 인라이닝되면 MyObj는 NoEscape로 다시 분류되어 힙 할당을 막을 수 있다.
락과 탈출 분석
✅ 락 최적화
핫스팟은 탈출 분석 및 관련 기법을 통해 락 성능도 최적화한다.
+) 단, 인스린직 락(synchronized를 사용한)에만 해당되며, java.util.concurrent 패키지에 있는 락에는 적용되지 않는다.
- 비탈출 객체에 있는 락은 제거한다(락 생략).
- 같은 락을 공유한, 락이 걸린 연속된 영역은 병합한다(락 확장). (-XX:-EliminateLocks로 해제 가능)
- 락을 해제하지 않고 같은 락을 반복 획득한 블록을 찾아낸다(중첩 락). (-XX:-EliminateNestedLocks로 해제 가능)
탈출 분석의 한계
✅ 배열의 탈출 분석
기본적으로 원소가 64개 이상인 배열은 핫스팟에서 탈출 분석의 혜택을 볼 수 없다.
개수 제한은 다음 VM 스위치로 조정 가능하다.
-XX:EliminateAllocationArraySizeLimit=<n>
각각 길이가 63, 64, 65인 비탈출 배열을 할당하는 테스트 메서드를 통해 JMH 벤치마크를 해보자.
@State(Scope.Thread)
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
public class EscapeTestArraySize {
private Random random = new Random();
@Benchmark
public long arraySize63() {
int[] a = new int[63];
a[0] = random.nextInt();
a[1] = random.nextInt();
return a[0] + a[1];
}
@Benchmark
public long arraySize64() {
int[] a = new int[64];
a[0] = random.nextInt();
a[1] = random.nextInt();
return a[0] + a[1];
}
@Benchmark
public long arraySize65() {
int[] a = new int[65];
a[0] = random.nextInt();
a[1] = random.nextInt();
return a[0] + a[1];
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(EscapeTestArraySize.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
<결과>
Benchmark Mode Cnt Score Error Units
EscapeTestArraySize.arraySize63 thrpt 200 63483063.113 ± 133178.062 ops/s
EscapeTestArraySize.arraySize64 thrpt 200 63446955.148 ± 127710.844 ops/s
EscapeTestArraySize.arraySize65 thrpt 200 31082833.351 ± 531994.230 ops/s-> 탈출 분석 최적화가 안되면 성능이 죽 떨어지는 걸 알 수 있다.
✅ 부분 탈출 분석을 지원하지 않음
객체가 어느 분기점에서건 메서드 범위를 탈출하면 힙에 객체를 할당하지 않는 최적화는 적용되지 않는다.
다음은 조건에 따라 인라이닝 메서드, 인라이닝 되지 않는 메서드 둘 중 하나로 분기하는 코드다.
for (int i = 0; i < 100_000_000; i++) {
Object mightEscape = new Object(i);
if (condition) {
result += inlineableMethod(mightEscape);
} else {
result += tooBigToInline(mightEscape);
}
}-> 반드시 ArgEscape로 분류된다.
다음 코드처럼 비탈출 분기 조건 안에 객체 할당을 묶어둘 수 있다면 탈출 분석의 덕을 볼 수 있을 것이다.
for (int i = 0; i < 100_000_000; i++) {
if (condition) {
Object mightEscape = new Object(i);
result += inlineableMethod(mightEscape);
} else {
Object mightEscape = new Object(i);
result += tooBigToInline(mightEscape);
}
}
단형성 디스패치
✅ 추측정 최적화
C2 컴파일러의 추측성 최적화와 같이 단형성 디스패치도 경험적 연구 결과를 토대로 한다.
-> 사람이 작성한 코드를 보면 십중팔구 각 호출부마다 딱 한 가지 런타임 타입이 수신자 객체 타입이 된다'
즉, 어떤 객체에 있는 메서드를 호 출할 때, 그 메서드를 최초로 호출한 객체의 런타임 타입을 알아내면 그 이후의 모든 호출도 동일한 타입일 가능성이 크다.
-> 이 가정이 옳다면, 메서드 호출을 최적화할 수 있다.
-> klass 포인터 및 vtable에서 메서드를 참조하는 일은 딱 한번만 하면 된다. 그 이후로 메서드를 참조할 경우를 대비해 캐시한다.
✅ 다형성 디스패치
핫스팟은 자주 쓰이지는 않지만 이형성 디스패치(bimorphic dispatch) 최적화도 지원한다.
-> 호출부마다 상이한 klass 워드를 캐시해서 처리한다.
단형도, 이형도 아닌 호출부를 다형성(megamorphic)이라고 한다.
-> 소수의 타입을 지닌 다형성 호출부를 찾아내면 성능 향상을 도모할 수 있다.
또한 호출부에서 instanceof 체크를 하며 타입을 하나씩 벗겨내어(peeling off) 호출부 타입의 경우의 수를 줄일 수 있다.
다음 예제를 살펴보자.
interface Shape {
int getSides();
}
class Triangle implements Shape {
public int getSides() {
return 3;
}
}
class Square implements Shape {
public int getSides() {
return 4;
}
}
class Octagon implements Shape {
public int getSides() {
return 8;
}
}
@State(Scope.Thread)
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
public class PeelMegamorphicCallsite {
private Random random = new Random();
private Shape triangle = new Triangle();
private Shape square = new Square();
private Shape octagon = new Octagon();
@Benchmark
public int runBimorphic() {
Shape currentShape = null;
switch (random.nextInt(2))
{
case 0:
currentShape = triangle;
break;
case 1:
currentShape = square;
break;
}
return currentShape.getSides();
}
@Benchmark
public int runMegamorphic() {
Shape currentShape = null;
switch (random.nextInt(3))
{
case 0:
currentShape = triangle;
break;
case 1:
currentShape = square;
break;
case 2:
currentShape = octagon;
break;
}
return currentShape.getSides();
}
@Benchmark
public int runPeeledMegamorphic() {
Shape currentShape = null;
switch (random.nextInt(3))
{
case 0:
currentShape = triangle;
break;
case 1:
currentShape = square;
break;
case 2:
currentShape = octagon;
break;
}
// 하나씩 타입을 벗겨냄
if (currentShape instanceof Triangle) {
return ((Triangle) currentShape).getSides();
}
else {
return currentShape.getSides(); // 이형(bimorphic)
}
}
}
<결과>
Benchmark Mode Cnt Score Error Units
PeelMegamorphicCallsite.runBimorphic thrpt 200 75844310 ± 43557 ops/s
PeelMegamorphicCallsite.runMegamorphic thrpt 200 54650385 ± 91283 ops/s
PeelMegamorphicCallsite.runPeeledMegamorphic thrpt 200 62021478 ± 150092 ops/s-> 호출부에 구현체를 2개만 남겨두면 이형성 인라인이이 일어나며, 구현체가 3개인 다형성 호출부보다 38% 더 많이 일을 한다.
-> 또한, 여러 타입 중 하나를 다른 호출부로 벗겨내면 다형성 코드보다 13% 성능이 향상된다.
인트린직
✅ 하드웨어에 의존하는 구현체
인트린직은 JIT가 동적 생성하기 이전에, JVM이 이미 알고 있는, 고도로 튜닝된 네이티브 메서드 구현체를 가리키는 용어다.
주로 OS나 CPU 아키텍처의 특정 기능을 응용하는, 성능이 필수적인 코어 메서드에 쓰인다.
ex)
| 메서드 | 설명 |
| java.lang.System.arraycopy() | CPU의 벡터 지원 기능으로 배열을 빨리 복사한다. |
| java.lang.System.currentTimeMillis() | 대부분 OS가 제공하는 구현체가 빠르다. |
| java.lang.Math.min() | 일부 CPU에서 분기 없이 연산 가능하다. |
| Other java.lang.Math methods | 일부 CPU에서 직접 명령어를 지원한다. |
| 암호화 함수 (e.g., AES) | 하드웨어로 가속하면 성능이 매우 좋아진다. |
✅ 인트린직 추가
새 인트린직을 추가할 때는 복잡도와 유용성 사이에서 저울질을 해봐야 한다.
ex) 자연수 n까지 합계를 구하는 산술 연산
자바 코드로는 O(n), 단순 공식은 O(1) -> n(n + 1) / 2
소요 시간이 일정한 합계 계산 인트린직을 구현해야 할까?
-> 합계를 계산해야 하는 코드가 정말 많다면 인트린직으로 구현해도 좋다.
-> 그렇지 않다면 굳이 JVM에 복잡도를 가중시킬뿐 큰 가치는 없다.
온-스택 치환
✅ 핫 루프 최적화
컴파일을 일으킬 정도로 호출 빈도가 높지는 않지만, 메서드 내부에 핫 루프가 포함된 경우가 있다.
-> 예컨데, 자바 프로그램의 main() 메서드가 그렇다.
핫스팟은 이런 코드를 온-스택 치환(OSR)을 이용해 최적화 한다.
-> 인터프리터가 루프 백 브랜치 횟수를 세어보고 특정 한계치를 초과하면 루프를 컴파일 한 후 치환해서 실행한다.
세이브포인트 복습
GC STW 이벤트뿐만 아니라, 다음 경우에도 전체 스레드가 세이브포인트에 걸린다.
- 메서드를 역최적화
- 힙 덤프를 생성
- 바이어스 락을 취소
- 클래스를 재정의(가령, 인스트루먼테이션 용도로)
핫스팟에서는 다음 지점에 세이브포인트 체크 코드를 넣는다.
- 루프 백 브랜치 시점
- 메서드 반환 시점
코어 라이브러리 메서드
인라이닝하기 적합한 메서드 크기 상한
✅ JarScan
JITWatch에 있는 오픈 소스 툴.
-> 클래스 폴더 또는 JAR 파일 내부에서 바이트코드 크기가 주어진 한계치 이상인 메서드를 모두 찾아낸다.
리눅스 x86_64, 자바8u512 환경에서 java.* 패키지 메서드 중,
바이트코드가 325바이트(FreqInlineSize 한계치)를 초과한 것이 490개나 있다.
ex) java.lang.String 클래스의 toUpperCase(), toLowerCase()는 바이트코드가 무려 439바이트나 돼서 인라이닝 범위를 벗어난다.
-> 이렇게 크기가 커진 까닭은, 대/소문자를 바꾸면 저장할 캐릭터 개수가 달라지는 로케일이 있기 때문이다.
✅ 도메인에 특정한 메서드로 성능 개선
다양한 캐릭터 셋을 고려할 필요 없이 ASCII 캐릭터만 입력받는다면,
toUpperCase()를 도메인에 특정한 메서드로 만들어 바이트코드 크기를 인라이닝 한계치 이하로 줄일 수 있다.
@State(Scope.Thread)
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
public class DomainSpecificUpperCase {
private static final String SOURCE =
"The quick brown fox jumps over the lazy dog";
public String toUpperCaseASCII(String source) {
int len = source.length();
char[] result = new char[len];
for (int i = 0; i < len; i++) {
char c = source.charAt(i);
if (c >= 'A' && c <= 'Z') {
c -= 32;
}
result[i] = c;
}
return new String(result);
}
@Benchmark
public String testStringToUpperCase() {
return SOURCE.toUpperCase();
}
@Benchmark
public String testCustomToUpperCase() {
return toUpperCaseASCII(SOURCE);
}
}
<결과>
Benchmark Mode Cnt Score Error Units
DomainSpecificUpperCase.testCustomToUpperCase thrpt 200 20138368 ± 17907 ops/s
DomainSpecificUpperCase.testStringToUpperCase thrpt 200 8350400 ± 7199 ops/s-> ASCII 전용 버전이 코어 라이브러리보다 약 2.4배 초당 처리 건수가 많다.
✅ 메서드를 작게 하면 좋은 점
인라이닝 가짓수가 늘어난다.
-> 메서드를 작게 유지하면 다양한 인라이닝 트리를 구축해서 핫 경로를 더욱 최적화할 여지가 생긴다.
컴파일하기 적합한 메서드 크기 상한
✅ 컴파일 상한 조정
핫스팟에는 메서드 크기가 어느 이상 초과하면 컴파일되지 않는 한계치(8,000 바이트)가 있다.
운영계 JVM에서는 이 수치를 바꿀 수 없지만, 디버그 JVM에서는 -XX:HugeMethodLimit=<n> 스위치로 설정할 수 있다.
참고자료
✅ 디스패치의 흑마술
https://shipilev.net/blog/2015/black-magic-method-dispatch/
'book > 자바 최적화' 카테고리의 다른 글
| [자바 최적화] 자바 언어의 성능 향상 기법 (0) | 2023.10.09 |
|---|---|
| [자바 최적화] JVM의 코드 실행 (0) | 2023.09.11 |
| [자바 최적화] GC 로깅, 모니터링, 튜닝, 툴 (0) | 2023.09.05 |
| [자바 최적화] 가비지 수집 고급 (0) | 2023.08.29 |
| [자바 최적화] 가비지 수집 기초 (2) | 2023.08.28 |