![[리액티브 프로그래밍] Operator](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FHHWyx%2FbtsHlHeJJah%2FdxzhHYPUtp5txK2GEU4rx0%2Fimg.png)
스프링으로 시작하는 리액티브 프로그래밍 | 황정식 - 교보문고
스프링으로 시작하는 리액티브 프로그래밍 | *리액티브 프로그래밍의 기본기를 확실하게 다진다*리액티브 프로그래밍은 적은 컴퓨팅 파워로 대량의 요청 트래픽을 효과적으로 처리할 수 있는
product.kyobobook.co.kr
Operator란?
✅ Operator
리액티브 스트림즈에서 연산자 역할.
ex) just(), create(), fromArray(), filter(), map()
-> Reactor에서 가장 중요한 구성요소.
+) Operator를 처음 이해할 때는 마블 다이어그램을 보는 것이 좋은데, 마블 다이어그램에 대한 설명은 다음 글을 참고하자.
https://gksdudrb922.tistory.com/317
[리액티브 프로그래밍] 마블 다이어그램(Marble Diagram)
스프링으로 시작하는 리액티브 프로그래밍 책 정리 스프링으로 시작하는 리액티브 프로그래밍 | 황정식 - 교보문고 스프링으로 시작하는 리액티브 프로그래밍 | *리액티브 프로그래밍의 기본기
gksdudrb922.tistory.com
Sequence 생성을 위한 Operator
✅ justOrEmpty

just()의 확장 Operator.
just()와 달리, emit할 데이터가 null일 경우, NPE가 발생하지 않고, onComplete Signal을 전송한다.
emit할 데이터가 null이 아닐 경우, Mono를 생성한다.
+) Flux는 just()만 있고, justOrEmpty()가 없다.
@Slf4j public class Example14_1 { public static void main(String[] args) { Mono .justOrEmpty(null) .subscribe(data -> {}, error -> {}, () -> log.info("# onComplete")); } }
justOrEmpty()에 null을 전달했다.
<결과>
07:40:30.310 [main] INFO - # onCompleteNPE 없이 onComplete Signal을 전송했다.
+) Optional.ofNullable(null), Optional.empty()를 전달해도 onComplete Signal을 전송한다.
✅ fromIterable
Iterable에 포함된 데이터를 emit하는 Flux를 생성한다.
public class SampleData { public static final List<Tuple2<String, Integer>> coins = Arrays.asList( Tuples.of("BTC", 52_000_000), Tuples.of("ETH", 1_720_000), Tuples.of("XRP", 533), Tuples.of("ICX", 2_080), Tuples.of("EOS", 4_020), Tuples.of("BCH", 558_000)); }
@Slf4j public class Example14_2 { public static void main(String[] args) { Flux .fromIterable(SampleData.coins) .subscribe(coin -> log.info("coin 명: {}, 현재가: {}", coin.getT1(), coin.getT2()) ); } }
<결과>
07:51:43.200 [main] INFO - coin 명: BTC, 현재가: 52000000 07:51:43.218 [main] INFO - coin 명: ETH, 현재가: 1720000 07:51:43.218 [main] INFO - coin 명: XRP, 현재가: 533 07:51:43.218 [main] INFO - coin 명: ICX, 현재가: 2080 07:51:43.219 [main] INFO - coin 명: EOS, 현재가: 4020 07:51:43.219 [main] INFO - coin 명: BCH, 현재가: 558000
+) 만약 Flux.just(list)를 사용한다면, 하나의 list 전체를 emit하는 Flux를 생성하게 된다.
✅ fromStream

Stream에 포함된 데이터를 emit하는 Flux를 생성한다.
Java Stream 특성상 Stream은 재사용할 수 없으며, cancel, error, complete 시에 자동으로 닫히게 된다.
public class SampleData { public static final List<String> coinNames = Arrays.asList("BTC", "ETH", "XRP", "ICX", "EOS", "BCH"); }
@Slf4j public class Example14_3 { public static void main(String[] args) { Flux .fromStream(() -> SampleData.coinNames.stream()) .filter(coin -> coin.equals("BTC") || coin.equals("ETH")) .subscribe(data -> log.info("{}", data)); } }
<결과>
07:57:43.592 [main] INFO - BTC 07:57:43.595 [main] INFO - ETH
✅ range
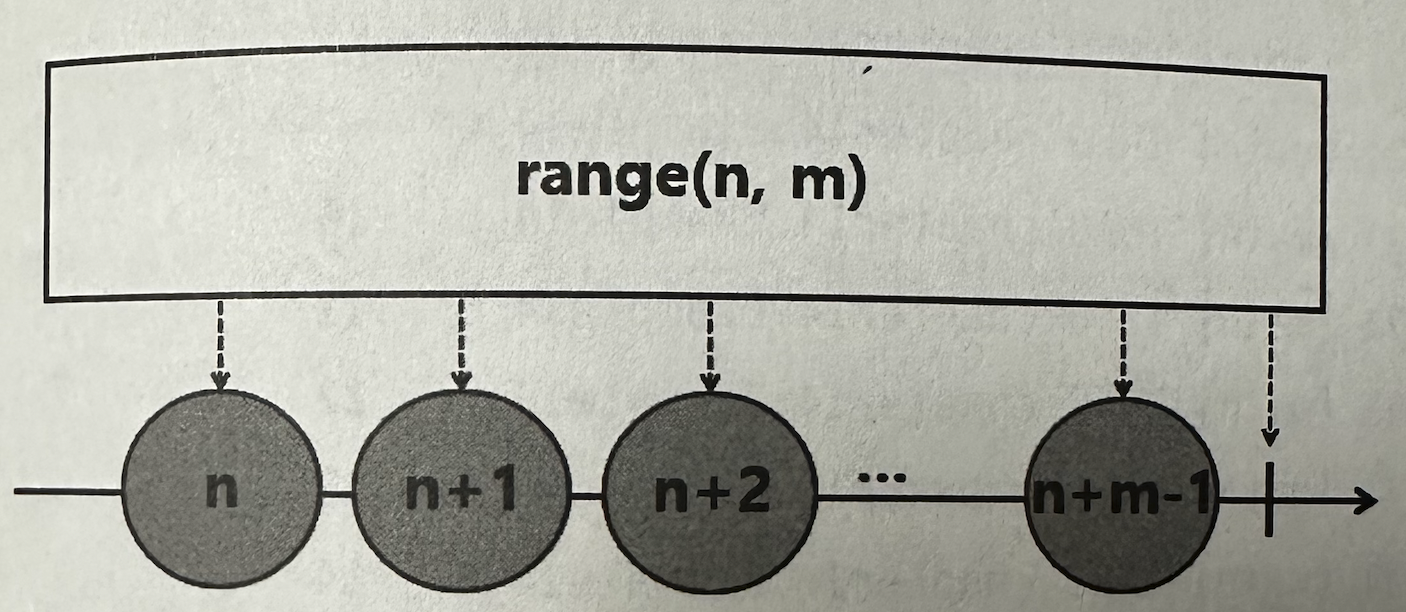
n부터 1씩 증가한 연속된 수를 m개 emit하는 Flux를 생성한다.
for문처럼 특정 횟수만큼 어떤 작업을 처리하고자 할 경우에 주로 사용된다.
@Slf4j public class Example14_4 { public static void main(String[] args) { Flux .range(5, 10) .subscribe(data -> log.info("{}", data)); } }
<결과>
08:05:53.597 [main] INFO - 5 08:05:53.598 [main] INFO - 6 08:05:53.598 [main] INFO - 7 08:05:53.598 [main] INFO - 8 08:05:53.598 [main] INFO - 9 08:05:53.598 [main] INFO - 10 08:05:53.598 [main] INFO - 11 08:05:53.599 [main] INFO - 12 08:05:53.599 [main] INFO - 13 08:05:53.599 [main] INFO - 14
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); }
@Slf4j public class Example14_5 { public static void main(String[] args) { Flux .range(7, 5) .map(idx -> SampleData.btcTopPricesPerYear.get(idx)) .subscribe(tuple -> log.info("{}'s {}", tuple.getT1(), tuple.getT2())); } }
<결과>
08:07:41.584 [main] INFO - 2017's 22483583 08:07:41.586 [main] INFO - 2018's 19521543 08:07:41.586 [main] INFO - 2019's 15761568 08:07:41.586 [main] INFO - 2020's 22439002 08:07:41.587 [main] INFO - 2021's 63364000
✅ defer
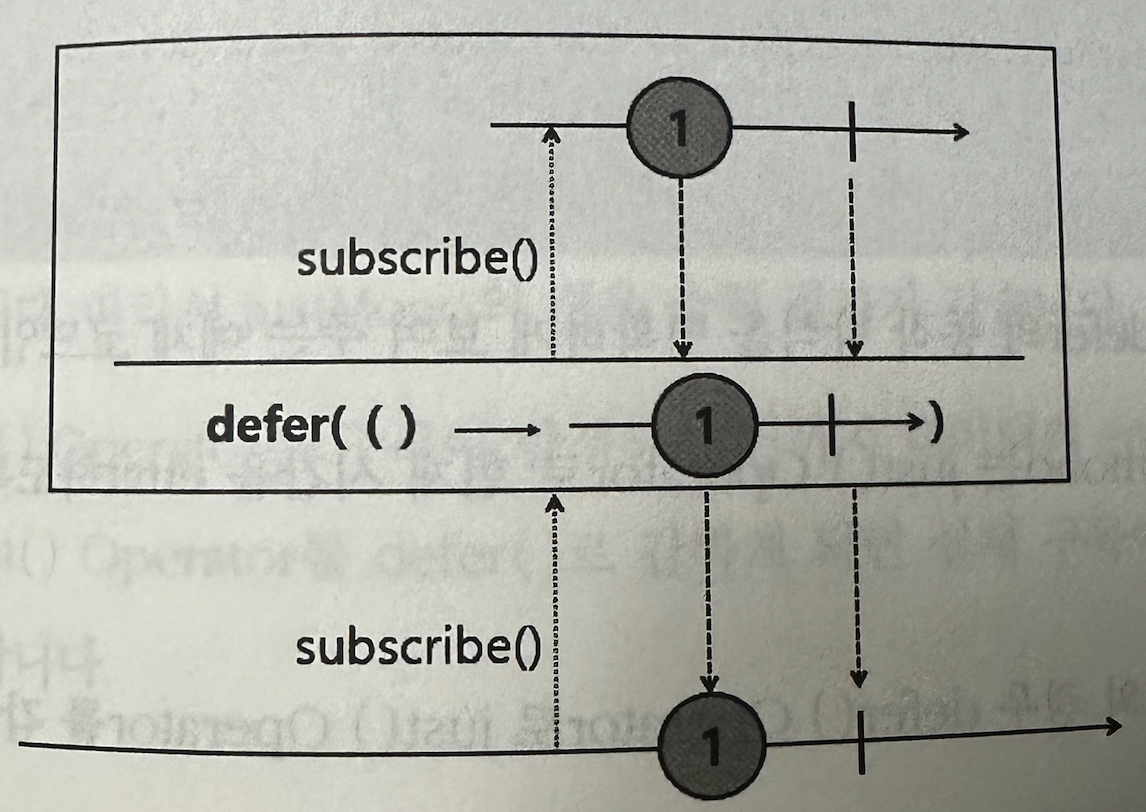
Operator를 선언한 시점에 데이터를 emit하는 것이 아니라, 구독하는 시점에 데이터를 emit한다.
defer()는 데이터 emit을 지연시키기 때문에 꼭 필요한 시점에 데이터를 emit할 수 있다.
@Slf4j public class Example14_6 { public static void main(String[] args) throws InterruptedException { log.info("# start: {}", LocalDateTime.now()); Mono<LocalDateTime> justMono = Mono.just(LocalDateTime.now()); Mono<LocalDateTime> deferMono = Mono.defer(() -> Mono.just(LocalDateTime.now())); Thread.sleep(2000); justMono.subscribe(data -> log.info("# onNext just1: {}", data)); deferMono.subscribe(data -> log.info("# onNext defer1: {}", data)); Thread.sleep(2000); justMono.subscribe(data -> log.info("# onNext just2: {}", data)); deferMono.subscribe(data -> log.info("# onNext defer2: {}", data)); } }
첫 번째 Mono는 just()로 현재 시간을 emit한다.
두 번째 Mono는 defer() & just()로 현재 시간을 emit한다.
2초의 지연 시간을 가진 후에 두 Mono에 대한 첫 번째 구독이 발생한다.
또 2초의 지연 시간을 가진 후에 두 Mono에 대한 두 번째 구독이 발생한다.
<결과>
08:14:56.692 [main] INFO - # onNext just1: 2024-05-13T08:14:54.602106 08:14:56.694 [main] INFO - # onNext defer1: 2024-05-13T08:14:56.694660 08:14:58.704 [main] INFO - # onNext just2: 2024-05-13T08:14:54.602106 08:14:58.707 [main] INFO - # onNext defer2: 2024-05-13T08:14:58.707562
defer() & just()를 사용한 Mono의 경우, 예상했던 것처럼 2초의 간격을 두고 emit되었다.
그런데 just()만 사용한 Mono의 경우 지연 시간가는 상관없이 동일한 시간을 출력한다.
왜 이런 결과가 발생할까?
사실 just()는 Hot Publisher이기 때문에, 구독 여부와 상관없이 데이터를 emit한다.
그리고 구독이 발생하면 emit된 데이터를 다시 reply해서 Subscriber에게 전달하는 것이다.
반대로 defer()는 구독이 발생하기 전까지 emit을 지연시키기 때문에 실제 구독이 발생할 때 데이터를 emit한다.
+) Hot Publisher에 대한 설명은 다음 글을 참고한다.
https://gksdudrb922.tistory.com/318
[리액티브 프로그래밍] Cold Sequence와 Hot Sequence
스프링으로 시작하는 리액티브 프로그래밍 책 정리 스프링으로 시작하는 리액티브 프로그래밍 | 황정식 - 교보문고 스프링으로 시작하는 리액티브 프로그래밍 | *리액티브 프로그래밍의 기본기
gksdudrb922.tistory.com
@Slf4j public class Example14_7 { public static void main(String[] args) throws InterruptedException { log.info("# start: {}", LocalDateTime.now()); Mono .just("Hello") .delayElement(Duration.ofSeconds(3)) .switchIfEmpty(sayDefault()) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(3500); } private static Mono<String> sayDefault() { log.info("# Say Hi"); return Mono.just("Hi"); } }
switchIfEmpty()는 Upstream Publisher가 데이터를 emit하지 않으면 호출된다.
Upstream Mono가 "Hello"라는 데이터를 emit하기 때문에 switchIfEmpty()는 호출되지 않을 것으로 기대된다.
<결과>
21:23:39.803 [main] INFO - # start: 2024-05-13T21:23:39.801993 21:23:39.875 [main] INFO - # Say Hi 21:23:42.900 [parallel-1] INFO - # onNext: Hello
그러나 실제로 sayDefault()는 호출되었다.
그 이유는, Upstream Mono의 데이터 emit 여부와 다르게, sayDefault()라는 Mono를 선언한 순간 이미 메서드는 호출되기 때문이다.
만약, switchIfEmpty()를 정말 대체용 Mono로 사용하고 싶다면, defer()를 사용하면 된다.
.switchIfEmpty(Mono.defer(() -> sayDefault()))
+) 위 예제와 관련된 자세한 설명은 다음 링크를 참고한다.
https://stackoverflow.com/questions/54373920/mono-switchifempty-is-always-called
Mono switchIfEmpty() is always called
I have two methods. Main method: @PostMapping("/login") public Mono<ResponseEntity<ApiResponseLogin>> loginUser(@RequestBody final LoginUser loginUser) { return socialServ...
stackoverflow.com
✅ using
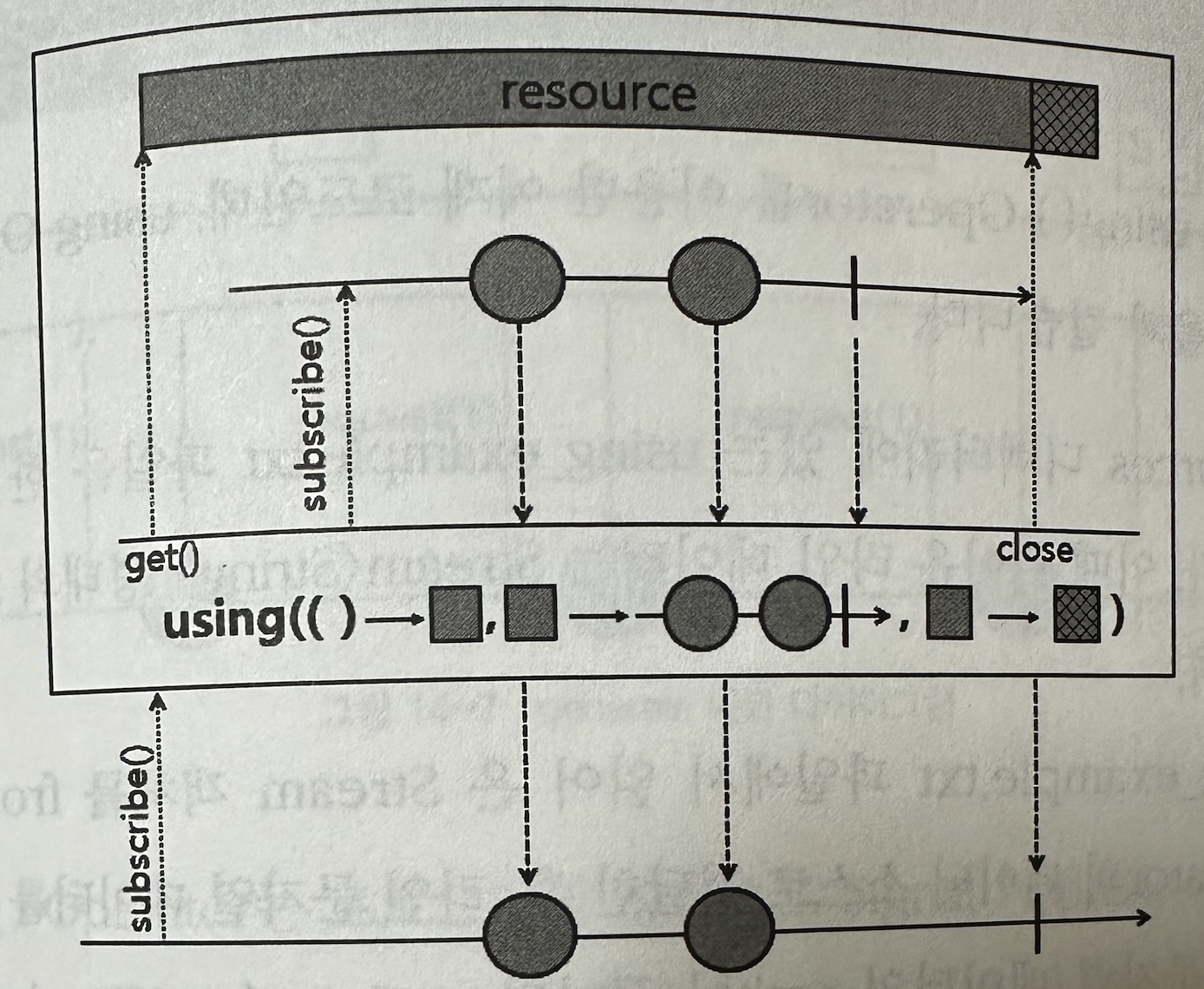
파라미터로 전달받은 resource를 emit하는 Flux를 생성한다.
- 첫 번째 파라미터: 읽어 올 resource
- 두 번째 파라미터: resource를 emit하는 Flux
- 세 번째 파라미터: onComplete 또는 onError Signal이 발생할 경우, 후처리.
@Slf4j public class Example14_8 { public static void main(String[] args) { Path path = Paths.get("D:\\resources\\using_example.txt"); Flux .using(() -> Files.lines(path), Flux::fromStream, Stream::close) .subscribe(log::info); } }
- using_example.txt 파일을 한 라인씩 읽어온다. 읽어 온 라인 데이터는 Stream<String> 형태다.
- Stream 객체를 fromStream()으로 emit한다.
- onComplete Signal이 발생하면 Stream을 닫는다.
- 파일에서 라인을 다 읽을 때까지 1 ~3 과정을 반복한다.
<결과>
21:05:05.378 [main] INFO - Hello, world! 21:05:05.379 [main] INFO - Nice to mee you! 21:05:05.380 [main] INFO - Good bye~
✅ generate()
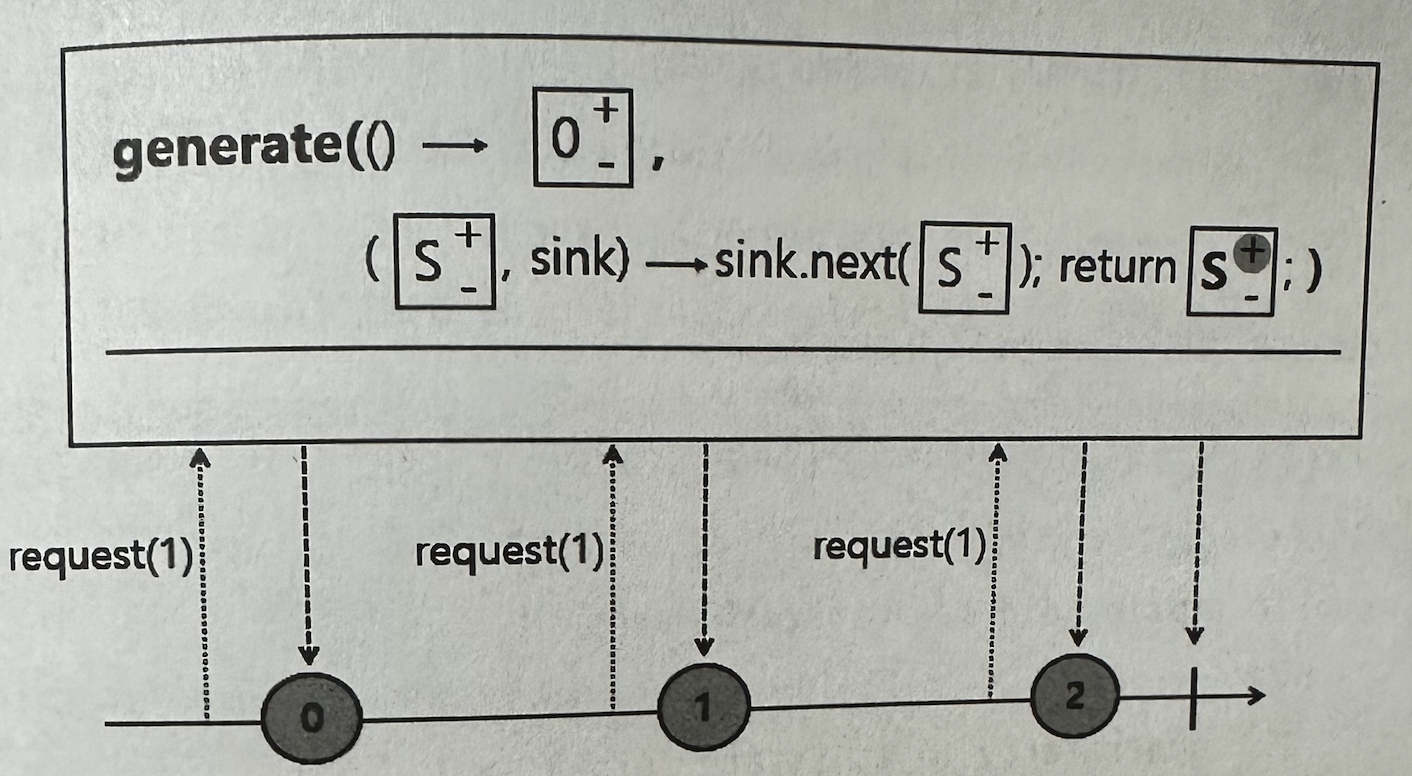
프로그래밍 방식으로 Signal을 발생시키며, 특히 동기적으로 데이터를 순차적으로 emit하고자 할 때 사용한다.
@Slf4j public class Example14_9 { public static void main(String[] args) { Flux .generate(() -> 0, (state, sink) -> { sink.next(state); if (state == 10) sink.complete(); return ++state; }) .subscribe(data -> log.info("# onNext: {}", data)); } }
초깃값은 0, 값이 10일 경우 onComplete Signal을 발생시킨다.
<결과>
21:13:22.228 [main] INFO - # onNext: 0 21:13:22.230 [main] INFO - # onNext: 1 21:13:22.230 [main] INFO - # onNext: 2 21:13:22.230 [main] INFO - # onNext: 3 21:13:22.230 [main] INFO - # onNext: 4 21:13:22.230 [main] INFO - # onNext: 5 21:13:22.230 [main] INFO - # onNext: 6 21:13:22.230 [main] INFO - # onNext: 7 21:13:22.231 [main] INFO - # onNext: 8 21:13:22.231 [main] INFO - # onNext: 9 21:13:22.231 [main] INFO - # onNext: 10
@Slf4j public class Example14_10 { public static void main(String[] args) { final int dan = 3; Flux .generate(() -> Tuples.of(dan, 1), (state, sink) -> { sink.next(state.getT1() + " * " + state.getT2() + " = " + state.getT1() * state.getT2()); if (state.getT2() == 9) sink.complete(); return Tuples.of(state.getT1(), state.getT2() + 1); }, state -> log.info("# 구구단 {}단 종료!", state.getT1())) .subscribe(data -> log.info("# onNext: {}", data)); } }
구구단 3단을 출력하는 예제이다.
세 번째 파라미터로 Sequence가 종료될 때, 후처리를 할 수 있다.
<결과>
21:14:50.281 [main] INFO - # onNext: 3 * 1 = 3 21:14:50.283 [main] INFO - # onNext: 3 * 2 = 6 21:14:50.283 [main] INFO - # onNext: 3 * 3 = 9 21:14:50.283 [main] INFO - # onNext: 3 * 4 = 12 21:14:50.283 [main] INFO - # onNext: 3 * 5 = 15 21:14:50.283 [main] INFO - # onNext: 3 * 6 = 18 21:14:50.283 [main] INFO - # onNext: 3 * 7 = 21 21:14:50.283 [main] INFO - # onNext: 3 * 8 = 24 21:14:50.284 [main] INFO - # onNext: 3 * 9 = 27 21:14:50.284 [main] INFO - # 구구단 3단 종료!
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); public static Map<Integer, Tuple2<Integer, Long>> getBtcTopPricesPerYearMap() { return btcTopPricesPerYear .stream() .collect(Collectors.toMap(t1 -> t1.getT1(), t2 -> t2)); } }
@Slf4j public class Example14_11 { public static void main(String[] args) { Map<Integer, Tuple2<Integer, Long>> map = SampleData.getBtcTopPricesPerYearMap(); Flux .generate(() -> 2019, (state, sink) -> { if (state > 2021) { sink.complete(); } else { sink.next(map.get(state)); } return ++state; }) .subscribe(data -> log.info("# onNext: {}", data)); } }
연도별 BTC 최고가를 출력하는 예제다.
<결과>
21:18:42.259 [main] INFO - # onNext: [2019,15761568] 21:18:42.265 [main] INFO - # onNext: [2020,22439002] 21:18:42.265 [main] INFO - # onNext: [2021,63364000]
✅ create
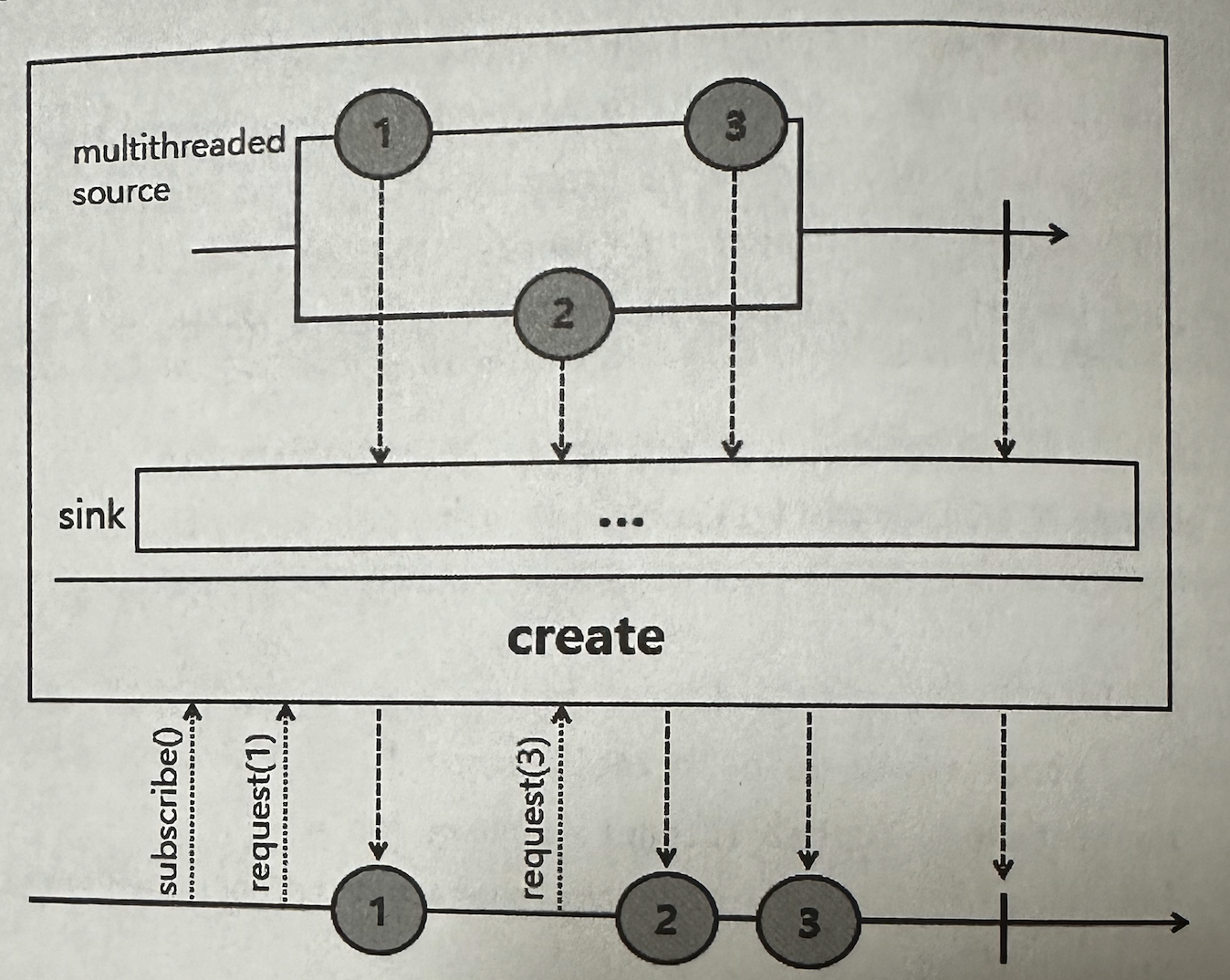
프로그래밍 방식으로 Signal을 발생시킨다.
generate()와 다른 점은 여러 데이터를 비동기적으로 emit할 수 있다.
@Slf4j public class Example14_12 { static int SIZE = 0; static int COUNT = -1; final static List<Integer> DATA_SOURCE = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); public static void main(String[] args) { log.info("# start"); Flux.create((FluxSink<Integer> sink) -> { sink.onRequest(n -> { try { Thread.sleep(1000L); for (int i = 0; i < n; i++) { if (COUNT >= 9) { sink.complete(); } else { COUNT++; sink.next(DATA_SOURCE.get(COUNT)); } } } catch (InterruptedException e) {} }); sink.onDispose(() -> log.info("# clean up")); }).subscribe(new BaseSubscriber<>() { @Override protected void hookOnSubscribe(Subscription subscription) { request(2); } @Override protected void hookOnNext(Integer value) { SIZE++; log.info("# onNext: {}", value); if (SIZE == 2) { request(2); SIZE = 0; } } @Override protected void hookOnComplete() { log.info("# onComplete"); } }); } }
- 구독이 발생하면 BaseSubscriber의 hookOnSubscribe()에서 request(2)를 호출하여 한 번에 두 개의 데이터를 요청한다.
- create()에서 sink.onReqeust()가 실행된다.
- 요청한 개수만큼 데이터를 emit한다.
- BaseSubscriber의 hookOnNext()에서 emit된 데이터를 처리하고, 다시 requets(2)를 호출한다.
- 2 ~ 4 과정이 반복되다가 onComplete Signal을 발생시킨다.
- BaseSubscriber의 hookOncomplete()를 호출한다.
- sink.onDispose()를 호출한다.
<결과>
21:23:01.329 [main] INFO - # start 21:23:02.448 [main] INFO - # onNext: 1 21:23:02.457 [main] INFO - # onNext: 2 21:23:03.463 [main] INFO - # onNext: 3 21:23:03.465 [main] INFO - # onNext: 4 21:23:04.471 [main] INFO - # onNext: 5 21:23:04.474 [main] INFO - # onNext: 6 21:23:05.481 [main] INFO - # onNext: 7 21:23:05.483 [main] INFO - # onNext: 8 21:23:06.487 [main] INFO - # onNext: 9 21:23:06.489 [main] INFO - # onNext: 10 21:23:07.491 [main] INFO - # onComplete 21:23:07.499 [main] INFO - # clean up
+) BaseSubscriber에 대한 설명은 다음 글을 참고한다.
https://gksdudrb922.tistory.com/319
[리액티브 프로그래밍] Backpressure
스프링으로 시작하는 리액티브 프로그래밍 책 정리 스프링으로 시작하는 리액티브 프로그래밍 | 황정식 - 교보문고 스프링으로 시작하는 리액티브 프로그래밍 | *리액티브 프로그래밍의 기본기
gksdudrb922.tistory.com
위 예제는 Subscriber가 request()를 호출하면 Publisher가 요청 개수만큼 데이터를 emit한다.
이제 Subscriber의 요청과 상관없이 비동기적으로 데이터를 emit하는 방식을 살펴보자.
public class SampleData { public static final List<Integer> btcPrices = Arrays.asList(50_000_000, 50_100_000, 50_700_000, 51_500_000, 52_000_000); }
public class CryptoCurrencyPriceEmitter { private CryptoCurrencyPriceListener listener; public void setListener(CryptoCurrencyPriceListener listener) { this.listener = listener; } public void flowInto() { listener.onPrice(SampleData.btcPrices); } public void complete() { listener.onComplete(); } }
public interface CryptoCurrencyPriceListener { void onPrice(List<Integer> priceList); void onComplete(); }
@Slf4j public class Example14_13 { public static void main(String[] args) throws InterruptedException { CryptoCurrencyPriceEmitter priceEmitter = new CryptoCurrencyPriceEmitter(); Flux.create((FluxSink<Integer> sink) -> priceEmitter.setListener(new CryptoCurrencyPriceListener() { @Override public void onPrice(List<Integer> priceList) { priceList.stream().forEach(price -> { sink.next(price); }); } @Override public void onComplete() { sink.complete(); } })) .publishOn(Schedulers.parallel()) .subscribe( data -> log.info("# onNext: {}", data), error -> {}, () -> log.info("# onComplete")); Thread.sleep(3000L); priceEmitter.flowInto(); Thread.sleep(2000L); priceEmitter.complete(); } }
Subscriber가 요청을 보내는 것이 아닌, 데이터를 리스닝하고 있다가, flowInto()와 같은 트리거가 발생하면 데이터를 emit한다.
<결과>
21:47:01.849 [parallel-1] INFO - # onNext: 50000000 21:47:01.859 [parallel-1] INFO - # onNext: 50100000 21:47:01.859 [parallel-1] INFO - # onNext: 50700000 21:47:01.859 [parallel-1] INFO - # onNext: 51500000 21:47:01.860 [parallel-1] INFO - # onNext: 52000000 21:47:03.860 [parallel-1] INFO - # onComplete
다음은 Backpressure 전략을 적용해본다.
@Slf4j public class Example14_14 { static int start = 1; static int end = 4; public static void main(String[] args) throws InterruptedException { Flux.create((FluxSink<Integer> emitter) -> { emitter.onRequest(n -> { log.info("# requested: " + n); try { Thread.sleep(500L); for (int i = start; i <= end; i++) { emitter.next(i); } start += 4; end += 4; } catch (InterruptedException e) {} }); emitter.onDispose(() -> { log.info("# clean up"); }); }, FluxSink.OverflowStrategy.DROP) .subscribeOn(Schedulers.boundedElastic()) .publishOn(Schedulers.parallel(), 2) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(3000L); } }
Backpressure DROP 전략을 사용했다.
+) Backpressure에 대한 설명은 다음 글을 참고하자.
https://gksdudrb922.tistory.com/319
[리액티브 프로그래밍] Backpressure
스프링으로 시작하는 리액티브 프로그래밍 책 정리 스프링으로 시작하는 리액티브 프로그래밍 | 황정식 - 교보문고 스프링으로 시작하는 리액티브 프로그래밍 | *리액티브 프로그래밍의 기본기
gksdudrb922.tistory.com
한 번에 4개의 데이터를 emit하는데, publishOn() 스케줄러의 prefetch 수를 2개로 지정했다. (2개는 DROP될 것으로 예상)
<결과>
21:46:28.921 [boundedElastic-1] INFO - # requested: 2 21:46:29.435 [parallel-1] INFO - # onNext: 1 21:46:29.446 [parallel-1] INFO - # onNext: 2 21:46:29.451 [boundedElastic-1] INFO - # requested: 2 21:46:29.959 [parallel-1] INFO - # onNext: 5 21:46:29.960 [parallel-1] INFO - # onNext: 6 21:46:29.960 [boundedElastic-1] INFO - # requested: 2 21:46:30.467 [parallel-1] INFO - # onNext: 9 21:46:30.468 [parallel-1] INFO - # onNext: 10 21:46:30.469 [boundedElastic-1] INFO - # requested: 2 21:46:30.975 [parallel-1] INFO - # onNext: 13 21:46:30.979 [parallel-1] INFO - # onNext: 14 21:46:30.983 [boundedElastic-1] INFO - # requested: 2 21:46:31.490 [parallel-1] INFO - # onNext: 17 21:46:31.493 [parallel-1] INFO - # onNext: 18 21:46:31.495 [boundedElastic-1] INFO - # requested: 2
Sequence 필터링 Operator
✅ filter
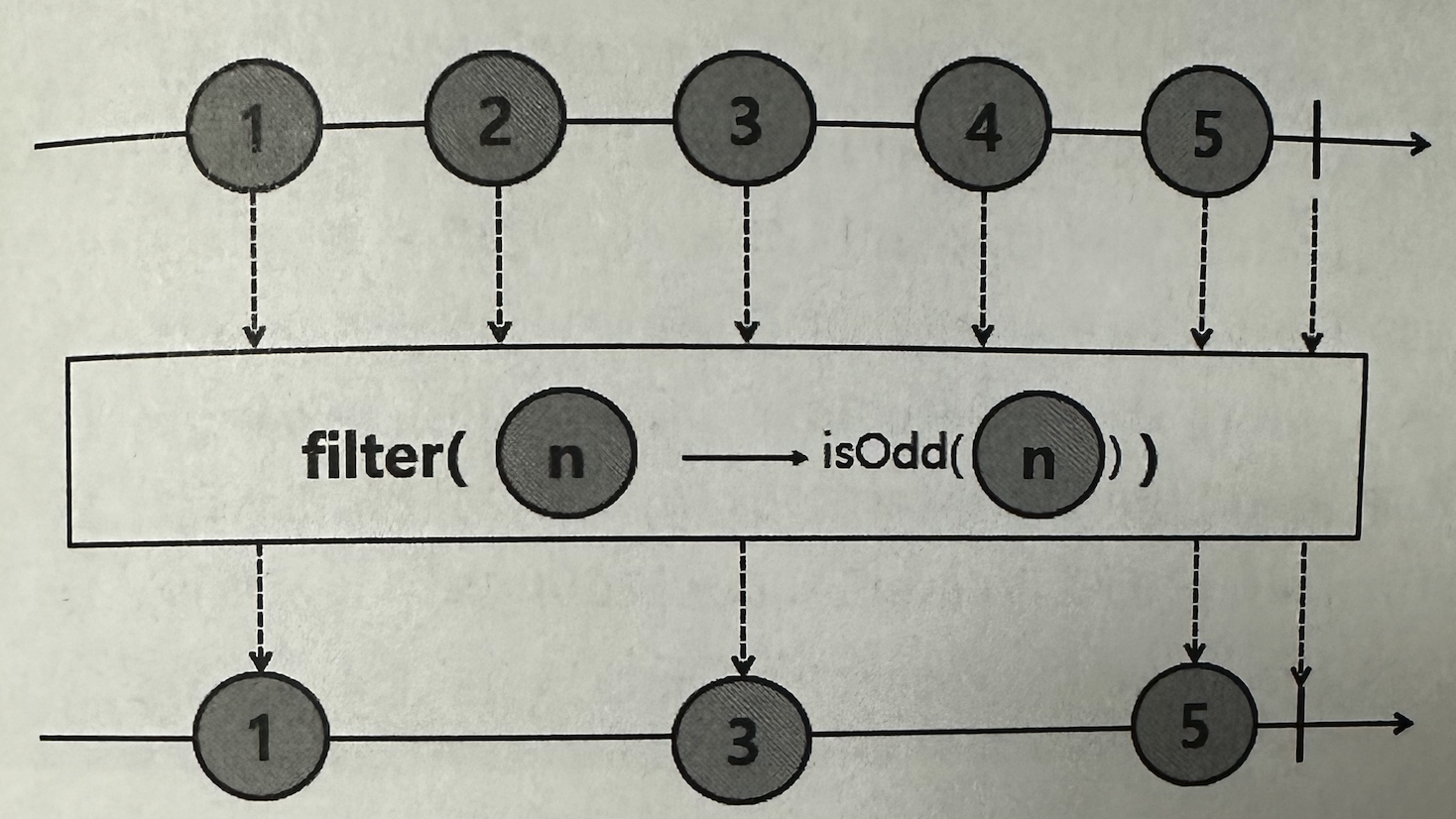
Upstream에서 emit된 데이터 중에서 조건에 일치하는 데이터만 Downstream으로 emit한다.
@Slf4j public class Example14_15 { public static void main(String[] args) { Flux .range(1, 20) .filter(num -> num % 2 != 0) .subscribe(data -> log.info("# onNext: {}", data)); } }
<결과>
07:29:57.598 [main] INFO - # onNext: 1 07:29:57.599 [main] INFO - # onNext: 3 07:29:57.599 [main] INFO - # onNext: 5 07:29:57.599 [main] INFO - # onNext: 7 07:29:57.600 [main] INFO - # onNext: 9 07:29:57.600 [main] INFO - # onNext: 11 07:29:57.600 [main] INFO - # onNext: 13 07:29:57.600 [main] INFO - # onNext: 15 07:29:57.600 [main] INFO - # onNext: 17 07:29:57.601 [main] INFO - # onNext: 19
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); }
@Slf4j public class Example14_16 { public static void main(String[] args) { Flux .fromIterable(SampleData.btcTopPricesPerYear) .filter(tuple -> tuple.getT2() > 20_000_000) .subscribe(data -> log.info(data.getT1() + ":" + data.getT2())); } }
<결과>
07:30:57.132 [main] INFO - 2017:22483583 07:30:57.134 [main] INFO - 2020:22439002 07:30:57.135 [main] INFO - 2021:63364000
public class SampleData { public enum CovidVaccine { Pfizer, AstraZeneca, Moderna, Janssen, Novavax; public static List<CovidVaccine> toList() { return Arrays.asList( CovidVaccine.Pfizer, CovidVaccine.AstraZeneca, CovidVaccine.Moderna, CovidVaccine.Janssen, CovidVaccine.Novavax ); } } public static final List<Tuple2<CovidVaccine, Integer>> coronaVaccines = Arrays.asList( Tuples.of(CovidVaccine.Pfizer, 1_000_000), Tuples.of(CovidVaccine.AstraZeneca, 3_000_000), Tuples.of(CovidVaccine.Moderna, 4_000_000), Tuples.of(CovidVaccine.Janssen, 2_000_000), Tuples.of(CovidVaccine.Novavax, 2_500_000) ); public static Map<CovidVaccine, Tuple2<CovidVaccine, Integer>> getCovidVaccines() { return coronaVaccines .stream() .collect(Collectors.toMap(t1 -> t1.getT1(), t2 -> t2)); } public static final List<CovidVaccine> coronaVaccineNames = CovidVaccine.toList(); }
@Slf4j public class Example14_17 { public static void main(String[] args) throws InterruptedException { Map<CovidVaccine, Tuple2<CovidVaccine, Integer>> vaccineMap = getCovidVaccines(); Flux .fromIterable(SampleData.coronaVaccineNames) .filterWhen(vaccine -> Mono .just(vaccineMap.get(vaccine).getT2() >= 3_000_000) .publishOn(Schedulers.parallel())) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(1000); } }
filterWhen()은 비동기적으로 필터링을 수행한다.
<결과>
07:34:54.822 [parallel-2] INFO - # onNext: AstraZeneca 07:34:54.839 [parallel-3] INFO - # onNext: Moderna
✅ skip
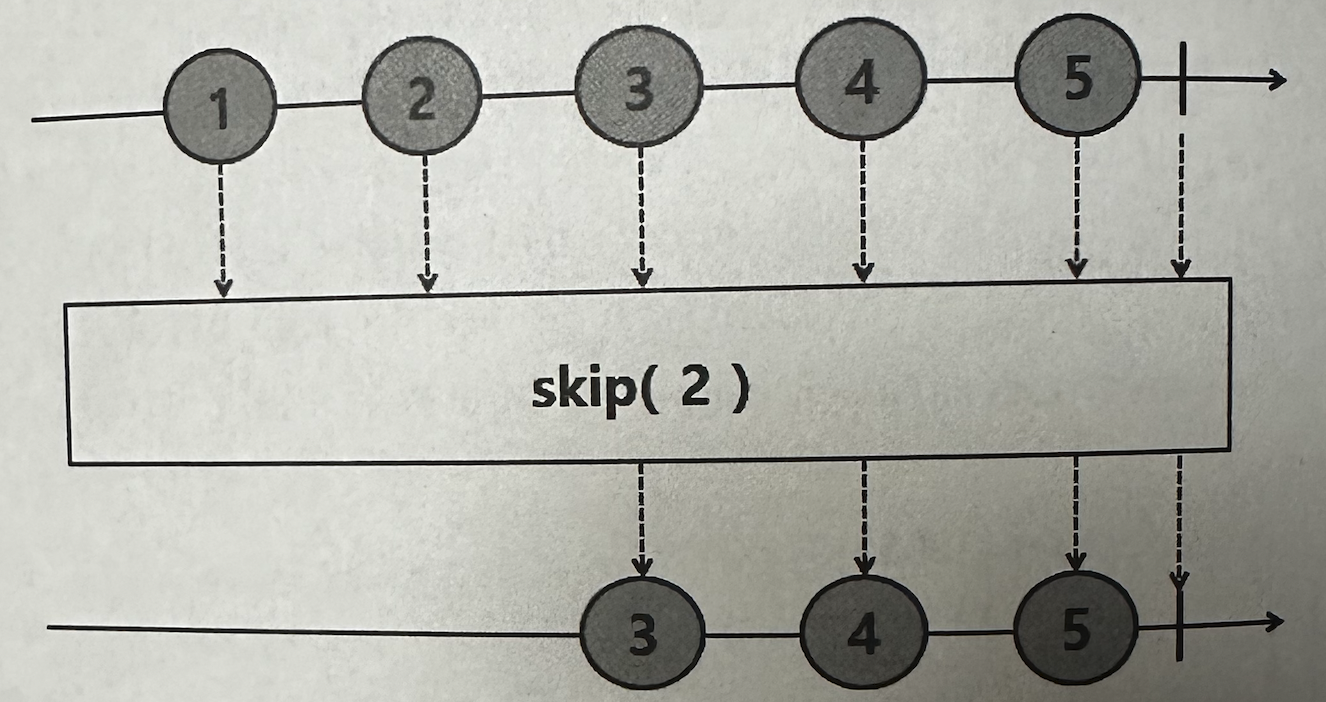
Upstream에서 emit된 데이터 중에서 파라미터로 입력받은 숫자만큼 건너뛴 후, 나머지 데이터를 Downstream으로 emit한다.
@Slf4j public class Example14_18 { public static void main(String[] args) throws InterruptedException { Flux .interval(Duration.ofSeconds(1)) .skip(2) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(5500L); } }
interval()은 0부터 1초에 한 번씩 1 증가한 숫자를 emit한다.
<결과>
07:38:28.115 [parallel-1] INFO - # onNext: 2 07:38:29.114 [parallel-1] INFO - # onNext: 3 07:38:30.111 [parallel-1] INFO - # onNext: 4
skip()은 0과 1을 건너뛰고 2부터 Downstream으로 emit한다.
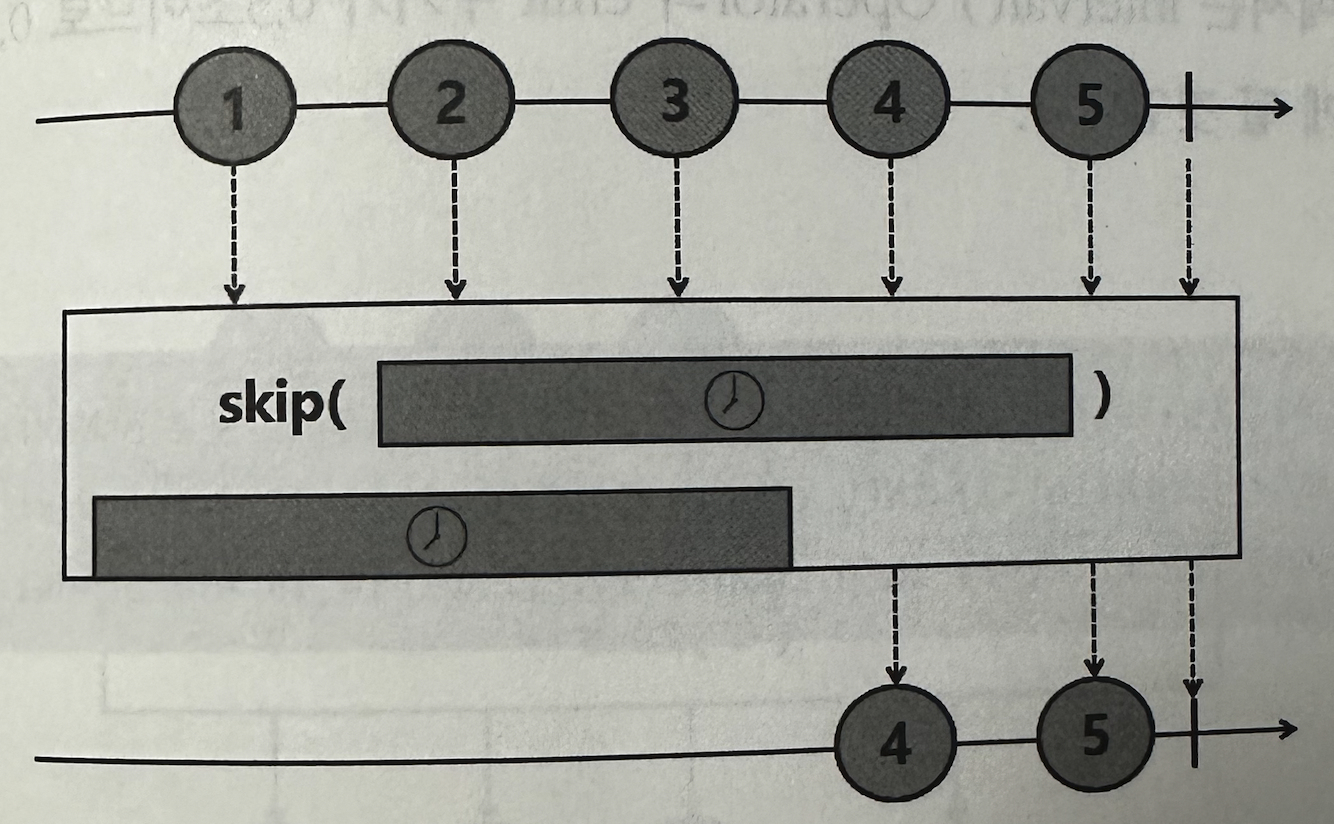
skip()의 파라미터로 시간을 지정하면, 지정한 시간 내에 emit된 데이터를 건너뛴 후, 나머지 데이터를 emit한다.
@Slf4j public class Example14_19 { public static void main(String[] args) throws InterruptedException { Flux .interval(Duration.ofMillis(300)) .skip(Duration.ofSeconds(1)) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(2000L); } }
<결과>
07:41:26.814 [parallel-2] INFO - # onNext: 3 07:41:27.115 [parallel-2] INFO - # onNext: 4 07:41:27.413 [parallel-2] INFO - # onNext: 5
1초 시간 내에 emit되는 데이터는 건너뛴다.
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); }
@Slf4j public class Example14_20 { public static void main(String[] args) { Flux .fromIterable(SampleData.btcTopPricesPerYear) .filter(tuple -> tuple.getT2() >= 20_000_000) .skip(2) .subscribe(tuple -> log.info("{}, {}", tuple.getT1(), tuple.getT2())); } }
<결과>
07:42:52.577 [main] INFO - 2021, 63364000
✅ take
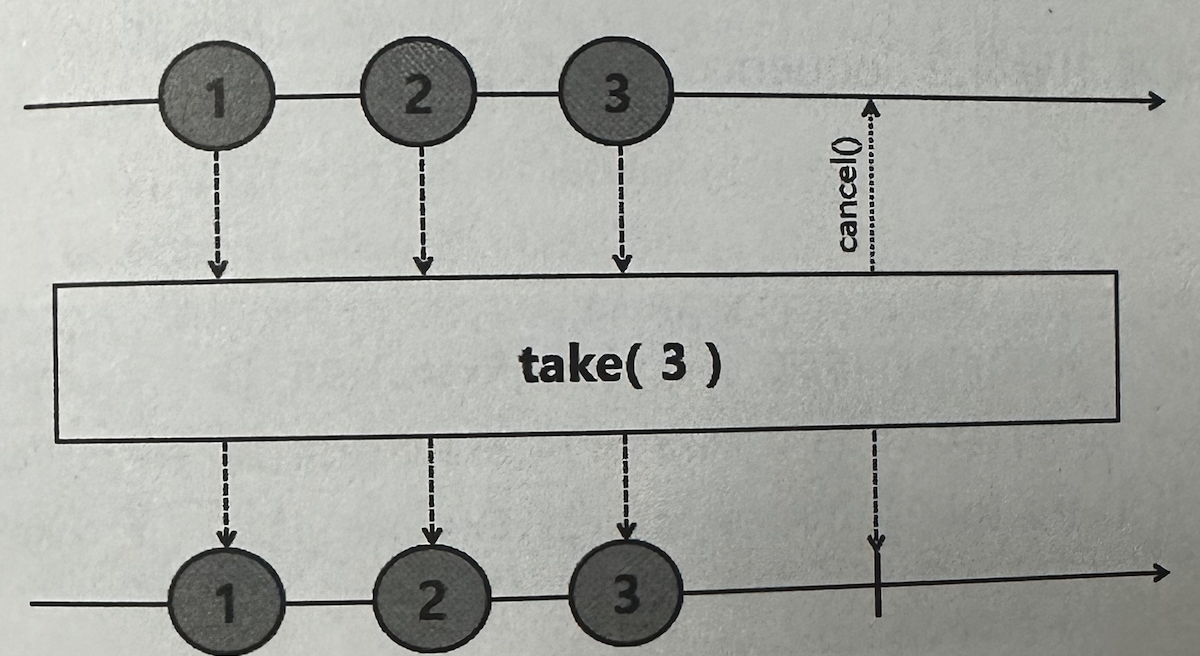
Upstream에서 emit된 데이터 중에서 파라미터로 입력받은 숫자만큼만, 데이터를 Downstream으로 emit한다. (skip의 반대)
@Slf4j public class Example14_21 { public static void main(String[] args) throws InterruptedException { Flux .interval(Duration.ofSeconds(1)) .take(3) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(4000L); } }
<결과>
07:44:47.373 [parallel-1] INFO - # onNext: 0 07:44:48.362 [parallel-1] INFO - # onNext: 1 07:44:49.362 [parallel-1] INFO - # onNext: 2
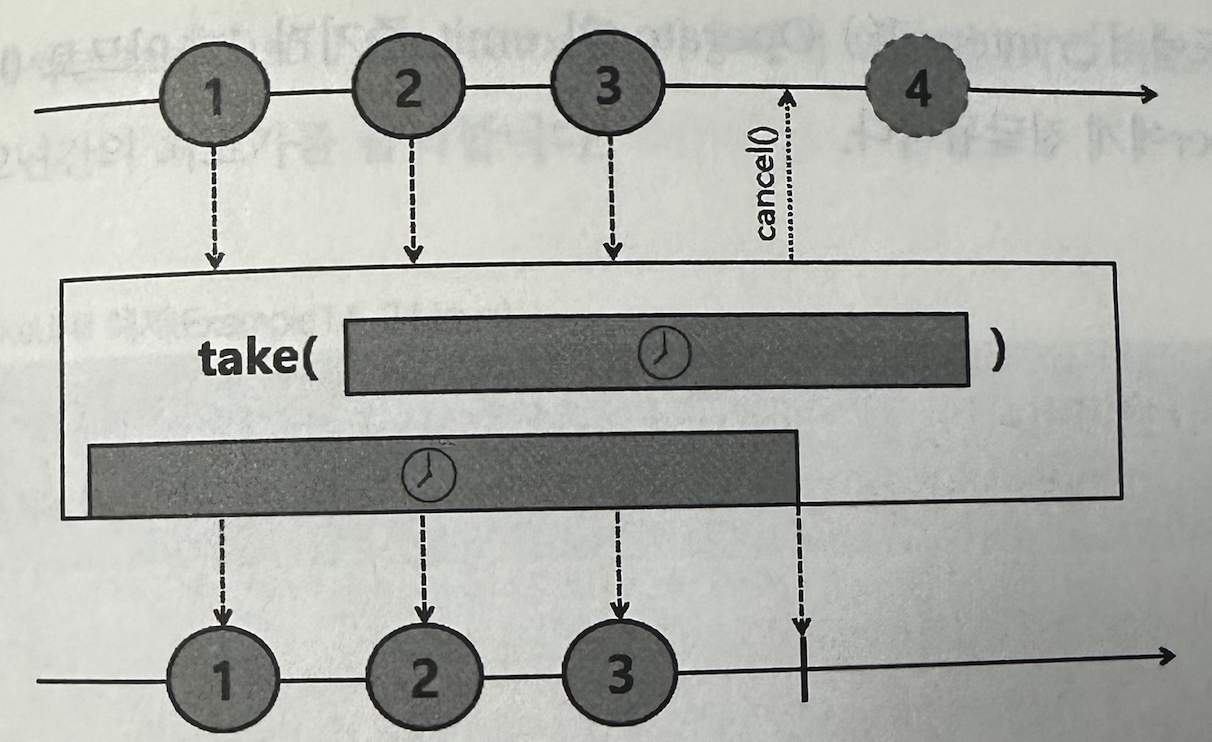
tkae()의 파라미터로 시간을 지정하면, 지정한 시간 내에 emit된 데이터만 emit한다.
@Slf4j public class Example14_22 { public static void main(String[] args) throws InterruptedException { Flux .interval(Duration.ofSeconds(1)) .take(Duration.ofMillis(2500)) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(3000L); } }
<결과>
07:46:33.923 [parallel-2] INFO - # onNext: 0 07:46:34.912 [parallel-2] INFO - # onNext: 1
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); }
@Slf4j public class Example14_23 { public static void main(String[] args) { Flux .fromIterable(SampleData.btcTopPricesPerYear) .takeLast(2) .subscribe(tuple -> log.info("# onNext: {}, {}", tuple.getT1(), tuple.getT2())); } }
takeLast()는 파라미터로 입력한 개수만큼 가장 마지막에 emit된 데이터를 Downstream으로 emit한다.
<결과>
07:47:56.375 [main] INFO - # onNext: 2020, 22439002 07:47:56.378 [main] INFO - # onNext: 2021, 63364000
@Slf4j public class Example14_24 { public static void main(String[] args) { Flux .fromIterable(SampleData.btcTopPricesPerYear) .takeUntil(tuple -> tuple.getT2() > 20_000_000) .subscribe(tuple -> log.info("# onNext: {}, {}", tuple.getT1(), tuple.getT2())); } }
takeUntil()은 파라미터로 입력한 Predicate가 true가 될 때까지 Downstream으로 emit한다.
<결과>
07:49:59.592 [main] INFO - # onNext: 2010, 565 07:49:59.600 [main] INFO - # onNext: 2011, 36094 07:49:59.601 [main] INFO - # onNext: 2012, 17425 07:49:59.601 [main] INFO - # onNext: 2013, 1405209 07:49:59.601 [main] INFO - # onNext: 2014, 1237182 07:49:59.601 [main] INFO - # onNext: 2015, 557603 07:49:59.601 [main] INFO - # onNext: 2016, 1111811 07:49:59.601 [main] INFO - # onNext: 2017, 22483583
Predicate를 평가할 때 사용한 데이터 22463583까지 포함된다.
@Slf4j public class Example14_25 { public static void main(String[] args) { Flux .fromIterable(SampleData.btcTopPricesPerYear) .takeWhile(tuple -> tuple.getT2() < 20_000_000) .subscribe(tuple -> log.info("# onNext: {}, {}", tuple.getT1(), tuple.getT2())); } }
takeWhile()은 파라미터로 입력한 Predicate가 true가 되는 동안에만 Downstream으로 emit한다. (takeUntil의 반대)
<결과>
07:51:25.625 [main] INFO - # onNext: 2010, 565 07:51:25.640 [main] INFO - # onNext: 2011, 36094 07:51:25.640 [main] INFO - # onNext: 2012, 17425 07:51:25.640 [main] INFO - # onNext: 2013, 1405209 07:51:25.640 [main] INFO - # onNext: 2014, 1237182 07:51:25.640 [main] INFO - # onNext: 2015, 557603 07:51:25.640 [main] INFO - # onNext: 2016, 1111811
takeUntil()과 달리, Predicate를 평가할 때 사용한 데이터 22463583까지는 포함되지 않는다.
✅ next
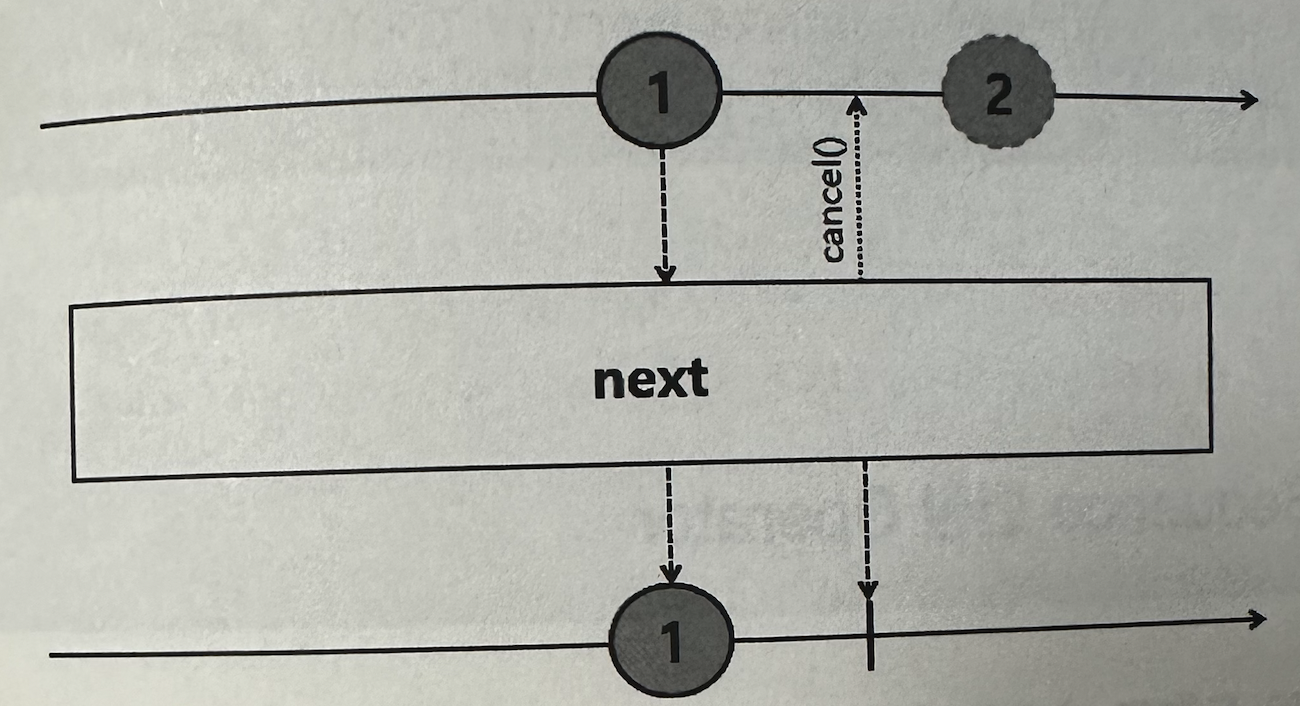
Upstream에서 emit되는 데이터 중에서 첫 번째 데이터만 Downstream으로 emit한다.
만약 Upstream에서 empty를 emit했다면, Downstream으로 empty Mono를 emit한다.
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); }
@Slf4j public class Example14_26 { public static void main(String[] args) { Flux .fromIterable(SampleData.btcTopPricesPerYear) .next() .subscribe(tuple -> log.info("# onNext: {}, {}", tuple.getT1(), tuple.getT2())); } }
<결과>
07:54:20.520 [main] INFO - # onNext: 2010, 565
Sequence 변환 Operator
✅ map
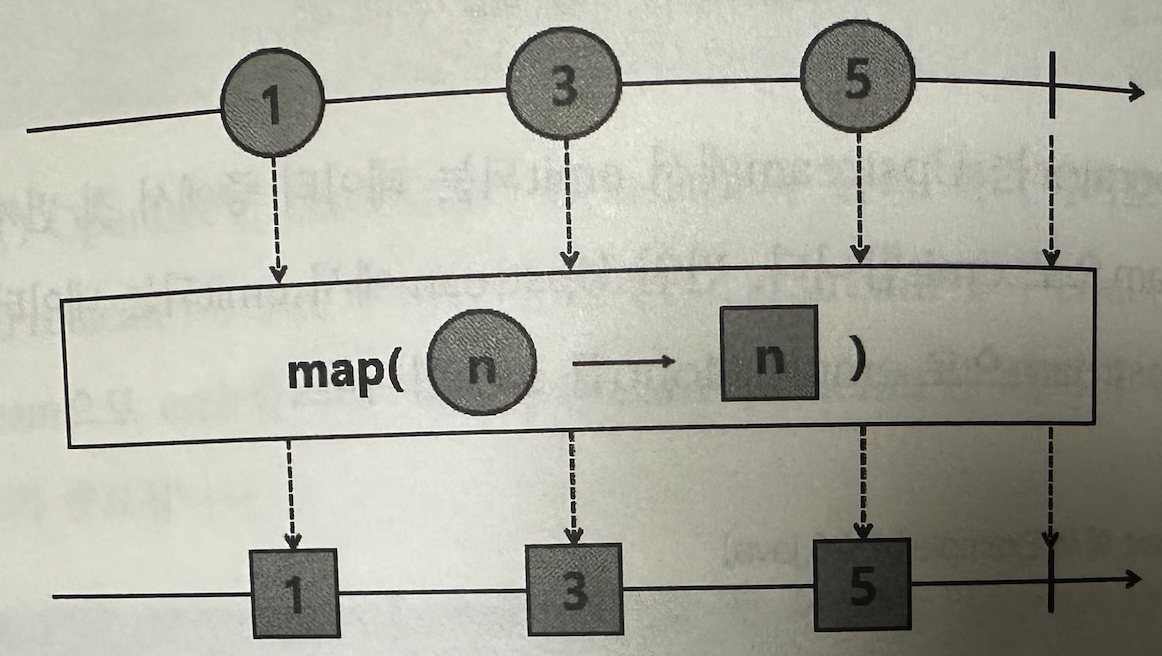
Upstream에서 emit되는 데이터를 mapper Fuction을 사용하여 변환한 후, Downstream으로 emit한다.
@Slf4j public class Example14_27 { public static void main(String[] args) { Flux .just("1-Circle", "3-Circle", "5-Circle") .map(circle -> circle.replace("Circle", "Rectangle")) .subscribe(data -> log.info("# onNext: {}", data)); } }
<결과>
07:31:36.043 [main] INFO - # onNext: 1-Rectangle 07:31:36.045 [main] INFO - # onNext: 3-Rectangle 07:31:36.045 [main] INFO - # onNext: 5-Rectangle
public class SampleData { public static final List<Tuple2<Integer, Long>> btcTopPricesPerYear = Arrays.asList( Tuples.of(2010, 565L), Tuples.of(2011, 36_094L), Tuples.of(2012, 17_425L), Tuples.of(2013, 1_405_209L), Tuples.of(2014, 1_237_182L), Tuples.of(2015, 557_603L), Tuples.of(2016, 1_111_811L), Tuples.of(2017, 22_483_583L), Tuples.of(2018, 19_521_543L), Tuples.of(2019, 15_761_568L), Tuples.of(2020, 22_439_002L), Tuples.of(2021, 63_364_000L) ); }
@Slf4j public class Example14_28 { public static void main(String[] args) { final double buyPrice = 50_000_000; Flux .fromIterable(SampleData.btcTopPricesPerYear) .filter(tuple -> tuple.getT1() == 2021) .doOnNext(data -> log.info("# doOnNext: {}", data)) .map(tuple -> calculateProfitRate(buyPrice, tuple.getT2())) .subscribe(data -> log.info("# onNext: {}%", data)); } private static double calculateProfitRate(final double buyPrice, Long topPrice) { return (topPrice - buyPrice) / buyPrice * 100; } }
<결과>
07:33:07.970 [main] INFO - # doOnNext: [2021,63364000] 07:33:07.973 [main] INFO - # onNext: 26.728%
✅ flatMap
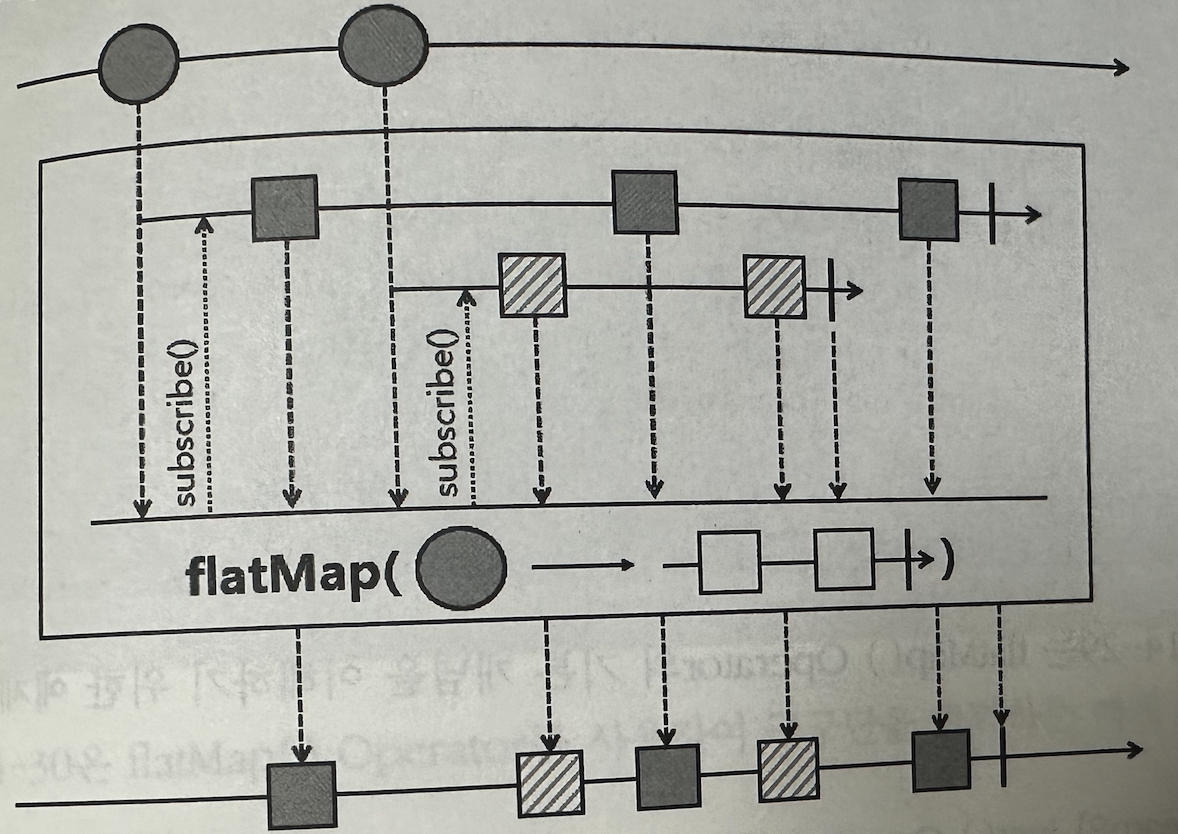
Upstream에서 emit되는 데이터를 Inner Sequence를 통해 여러 건의 데이터로 변환할 수 있다.
@Slf4j public class Example14_29 { public static void main(String[] args) { Flux .just("Good", "Bad") .flatMap(feeling -> Flux .just("Morning", "Afternoon", "Evening") .map(time -> feeling + " " + time)) .subscribe(log::info); } }
<결과>
07:37:09.202 [main] INFO - Good Morning 07:37:09.204 [main] INFO - Good Afternoon 07:37:09.204 [main] INFO - Good Evening 07:37:09.204 [main] INFO - Bad Morning 07:37:09.204 [main] INFO - Bad Afternoon 07:37:09.204 [main] INFO - Bad Evening
@Slf4j public class Example14_30 { public static void main(String[] args) throws InterruptedException { Flux .range(2, 8) .flatMap(dan -> Flux .range(1, 9) .publishOn(Schedulers.parallel()) .map(n -> dan + " * " + n + " = " + dan * n)) .subscribe(log::info); Thread.sleep(100L); } }
<결과>
07:38:44.190 [parallel-1] INFO - 2 * 1 = 2 07:38:44.216 [parallel-1] INFO - 2 * 2 = 4 ... 07:38:44.218 [parallel-1] INFO - 5 * 1 = 5 07:38:44.223 [parallel-1] INFO - 5 * 2 = 10 ... 07:38:44.226 [parallel-1] INFO - 6 * 1 = 6 07:38:44.226 [parallel-1] INFO - 6 * 2 = 12 ... 07:38:44.231 [parallel-1] INFO - 9 * 1 = 9 07:38:44.231 [parallel-1] INFO - 9 * 2 = 18 ... 07:38:44.231 [parallel-1] INFO - 3 * 1 = 3 07:38:44.232 [parallel-1] INFO - 3 * 2 = 6 ... 07:38:44.235 [parallel-1] INFO - 4 * 8 = 32 07:38:44.235 [parallel-1] INFO - 4 * 9 = 36
-> flatMap()은 Inner Sequence를 비동기적으로 실행하면 데이터 emit의 순서를 보장하지 않는다.
✅ concat
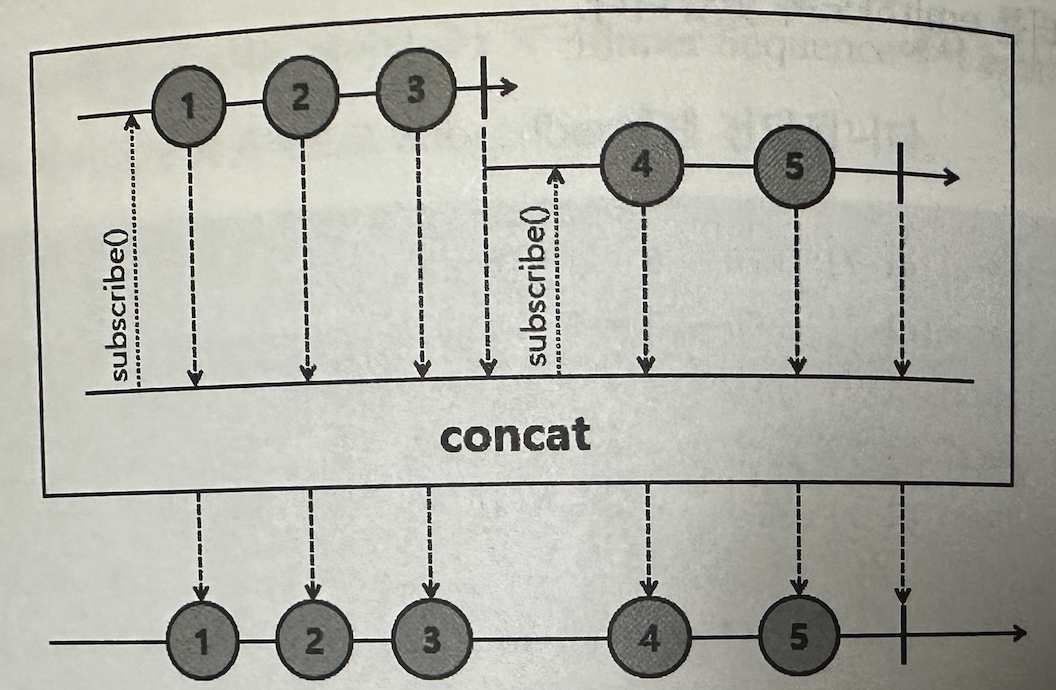
파라미터로 입력되는 Publisher의 Sequence를 연결해서 데이터를 순차적으로 emit한다.
-> 먼저 입력된 Publisher의 Seuquence가 종료될 때까지 나머지 Publisher의 Sequence는 subscribe되지 않고 대기한다.
@Slf4j public class Example14_31 { public static void main(String[] args) { Flux .concat(Flux.just(1, 2, 3), Flux.just(4, 5)) .subscribe(data -> log.info("# onNext: {}", data)); } }
<결과>
07:50:04.461 [main] INFO - # onNext: 1 07:50:04.462 [main] INFO - # onNext: 2 07:50:04.463 [main] INFO - # onNext: 3 07:50:04.463 [main] INFO - # onNext: 4 07:50:04.463 [main] INFO - # onNext: 5
public class SampleData { public enum CovidVaccine { Pfizer, AstraZeneca, Moderna, Janssen, Novavax; } public static final List<Tuple2<CovidVaccine, Integer>> viralVectorVaccines = Arrays.asList( Tuples.of(CovidVaccine.AstraZeneca, 3_000_000), Tuples.of(CovidVaccine.Janssen, 2_000_000) ); public static final List<Tuple2<CovidVaccine, Integer>> mRNAVaccines = Arrays.asList( Tuples.of(CovidVaccine.Pfizer, 1_000_000), Tuples.of(CovidVaccine.Moderna, 4_000_000) ); public static final List<Tuple2<CovidVaccine, Integer>> subunitVaccines = Arrays.asList( Tuples.of(CovidVaccine.Novavax, 2_500_000) ); }
@Slf4j public class Example14_32 { public static void main(String[] args) { Flux .concat( Flux.fromIterable(getViralVector()), Flux.fromIterable(getMRNA()), Flux.fromIterable(getSubunit())) .subscribe(data -> log.info("# onNext: {}", data)); } private static List<Tuple2<SampleData.CovidVaccine, Integer>> getViralVector() { return SampleData.viralVectorVaccines; } private static List<Tuple2<SampleData.CovidVaccine, Integer>> getMRNA() { return SampleData.mRNAVaccines; } private static List<Tuple2<SampleData.CovidVaccine, Integer>> getSubunit() { return SampleData.subunitVaccines; } }
<결과>
07:51:44.107 [main] INFO - # onNext: [AstraZeneca,3000000] 07:51:44.110 [main] INFO - # onNext: [Janssen,2000000] 07:51:44.110 [main] INFO - # onNext: [Pfizer,1000000] 07:51:44.110 [main] INFO - # onNext: [Moderna,4000000] 07:51:44.110 [main] INFO - # onNext: [Novavax,2500000]
✅ merge
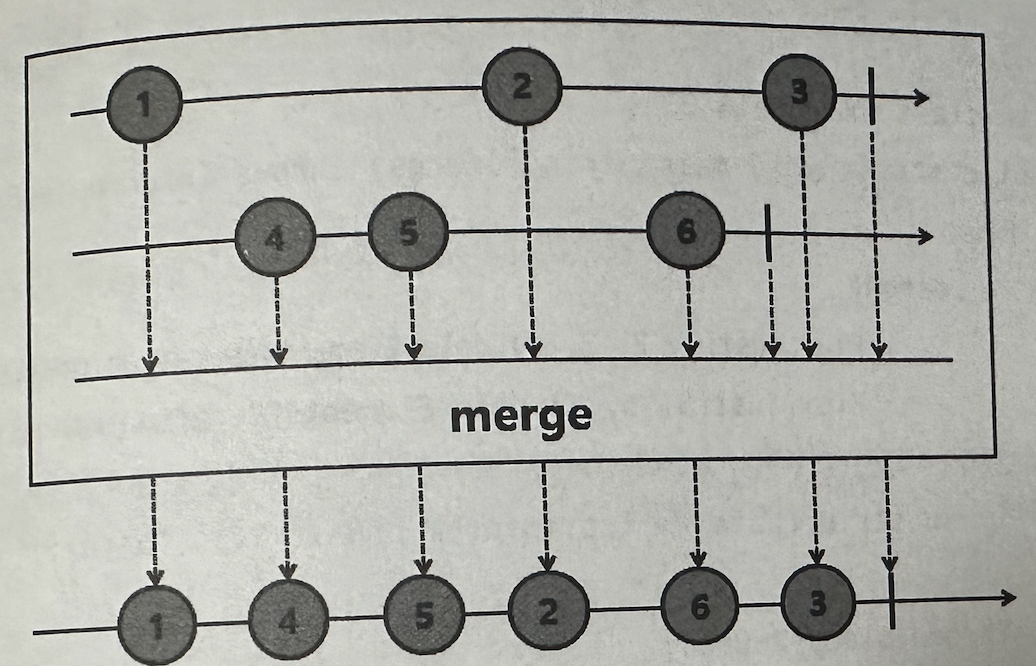
파라미터로 입력되는 Publisher의 Sequence를 인터리빙 방식으로 연결한다.
-> 모든 Publisher의 Sequence가 즉시 subscribe된다.
Q: 인터리빙 방식?
A: 교차로 배치한다는 의미. merge()에서는 emit된 시간 순서대로 merge한다.
@Slf4j public class Example14_33 { public static void main(String[] args) throws InterruptedException { Flux .merge( Flux.just(1, 2, 3, 4).delayElements(Duration.ofMillis(300L)), Flux.just(5, 6, 7).delayElements(Duration.ofMillis(500L)) ) .subscribe(data -> log.info("# onNext: {}", data)); Thread.sleep(2000L); } }
<결과>
07:55:45.411 [parallel-1] INFO - # onNext: 1 07:55:45.605 [parallel-2] INFO - # onNext: 5 07:55:45.744 [parallel-3] INFO - # onNext: 2 07:55:46.050 [parallel-5] INFO - # onNext: 3 07:55:46.112 [parallel-4] INFO - # onNext: 6 07:55:46.362 [parallel-6] INFO - # onNext: 4 07:55:46.620 [parallel-7] INFO - # onNext: 7
public class SampleData { public static Map<String, Mono<String>> nppMap = new HashMap<>(); static { nppMap.put("Ontario", Mono.just("Ontario Done").delayElement(Duration.ofMillis(1500L))); nppMap.put("Vermont", Mono.just("Vermont Done").delayElement(Duration.ofMillis(400L))); nppMap.put("New Hampshire", Mono.just("New Hampshire Done").delayElement(Duration.ofMillis(700L))); nppMap.put("New Jersey", Mono.just("New Jersey Done").delayElement(Duration.ofMillis(500L))); nppMap.put("Ohio", Mono.just("Ohio Done").delayElement(Duration.ofMillis(1000L))); nppMap.put("Michigan", Mono.just("Michigan Done").delayElement(Duration.ofMillis(200L))); nppMap.put("Illinois", Mono.just("Illinois Done").delayElement(Duration.ofMillis(300L))); nppMap.put("Virginia", Mono.just("Virginia Done").delayElement(Duration.ofMillis(600L))); nppMap.put("North Carolina", Mono.just("North Carolina Done").delayElement(Duration.ofMillis(800L))); nppMap.put("Georgia", Mono.just("Georgia Done").delayElement(Duration.ofMillis(900L))); } }
@Slf4j public class Example14_34 { public static void main(String[] args) throws InterruptedException { String[] usaStates = { "Ohio", "Michigan", "New Jersey", "Illinois", "New Hampshire", "Virginia", "Vermont", "North Carolina", "Ontario", "Georgia" }; Flux .merge(getMeltDownRecoveryMessage(usaStates)) .subscribe(log::info); Thread.sleep(2000L); } private static List<Mono<String>> getMeltDownRecoveryMessage(String[] usaStates) { List<Mono<String>> messages = new ArrayList<>(); for (String state : usaStates) { messages.add(SampleData.nppMap.get(state)); } return messages; } }
<결과>
08:00:02.346 [parallel-2] INFO - Michigan Done 08:00:02.438 [parallel-4] INFO - Illinois Done 08:00:02.539 [parallel-7] INFO - Vermont Done 08:00:02.640 [parallel-3] INFO - New Jersey Done 08:00:02.739 [parallel-6] INFO - Virginia Done 08:00:02.839 [parallel-5] INFO - New Hampshire Done 08:00:02.939 [parallel-8] INFO - North Carolina Done 08:00:03.040 [parallel-10] INFO - Georgia Done 08:00:03.138 [parallel-1] INFO - Ohio Done 08:00:03.640 [parallel-9] INFO - Ontario Done
'book > 스프링으로 시작하는 리액티브 프로그래밍' 카테고리의 다른 글
| [리액티브 프로그래밍] Testing (0) | 2024.05.08 |
|---|---|
| [리액티브 프로그래밍] Debugging (0) | 2024.05.06 |
| [리액티브 프로그래밍] Context (0) | 2024.05.06 |
| [리액티브 프로그래밍] Scheduler (0) | 2024.04.21 |
| [리액티브 프로그래밍] Sinks (0) | 2024.04.21 |