![[자바 최적화] 마이크로벤치마킹과 통계](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FB63SX%2FbtsrTqeHcZt%2Fiz8h3INw6z5iQRWSo5OHwk%2Fimg.png)
자바 최적화 책 정리
자바 최적화(Optimizing Java) | 벤저민 J. 에번스 - 교보문고
자바 최적화(Optimizing Java) | 자바 애플리케이션 성능을 한 단계 높여줄 튜닝 이야기성능 튜닝은 실험과학이다. 추측과 구전 튜닝에 의존할 일이 아니다. 이 책은 복잡한 기술 스택을 다루는 중/고
product.kyobobook.co.kr
자바 성능 측정 기초
✅ 자바 벤치마크는 어려워
우리의 목표는 벤치마크로 공정한 테스트를 하는 것
-> 가급적 시스템의 어느 한 곳만 변경하고 다른 외부 요인은 벤치마크 안에 두고 통제하고자 함
그러나 자바 코드 실행은 JIT 컴파일러, 메모리 관리, 그 밖의 서브 시스템과 완전히 떼어넣고 생각할 수 없다.
-> 이처럼 자바 런타임시의 변동 요인을 고려하며 공정한 벤치마크를 하는 것은 상당히 어렵다.
✅ 벤치마크 시 고려해야 할 점
1. 웜업
특정 벤치마크 타이밍을 캡처하기 전에, JVM이 JIT 컴파일러 등을 최대한 활용할 수 있게 JVM 웜업 기간을 두는 것이 좋다.
-> 보통 타이밍을 캡처하지 않는 상태로 벤치마크 대상 코드를 여러 번 반복 실행하는 식으로 JVM을 예열시킨다.
2. 가비지 수집
타이밍 캡처 도중 GC가 안일어나면 좋겠지만, 가비지 수집은 불확정적이어서 어찌할 도리가 없다.
-> GC가 일어날 가능성이 큰 시기에는 타이밍을 캡처하지 않는 것이 최선.
3. 테스트하려는 코드를 실제로 사용하지 않는 것
테스트하려는 코드에서 생성된 결과를 실제로 사용하지 않으면,
JIT 컴파일러가 죽은 코드로 식별하고 우리가 벤치마크하려던 것을 최적화해버릴 가능성이 있다.
4. 허용 오차
허용 오차(오차 범위, 허용 오차가 클수록 결과가 전체를 잘 반영하지 못할 확률이 높음)를 구해 수집한 값의 신뢰도를 파악하는게 좋다.
5. 하드웨어
멀티스레드 코드를 벤치마크할 때는 하드웨어 설정치를 가볍게 웃돌 가능성이 있으니 신경쓰자.
✅ 해결 방안
1. 시스템 전체를 벤치마크한다
저수준 수치는 수집하지 않고, 더 큰 규모에서 유의미한 결과를 얻는다.
2. 마이크로 벤치마킹이 필요하다면, 앞서 언급한 문제들을 공통 프레임워크를 통해 처리한다
이상적인 프레임워크라면 몇 가지 문제는 어느 정도 해결할 것이다.
-> 아래 소개할 JMH가 바로 그런 툴이다.
JMH 소개
될 수 있으면 마이크로벤치마크하지 말지어다(실화)
✅ 이 책의 필자의 일화
1. 어느날 동료가 애플리케이션에서 성능이 안나와 특정 메서드를 위한 벤치마크를 작성하고 있었다.
2. 사실 전체 애플리케이션을 벤치마크 해 보니, 코드는 문제가 없었고, 새로 들여온 인프라 라이브러리가 화근이었다.
3. 성능은 코드 관점보다 더 큰 그림을 봐야 좋다.
휴리스틱: 마이크로벤치마킹은 언제 하나?
✅ 다시 말하지만 마이크로벤치마킹은 어려워
자바는 앞서 언급했듯이, 런타임 환경마다 성능 수치가 제각각이다.
-> 작은 자바 코드 조각보다 자바 애플리케이션 전체를 대상으로 성능 분석을 하는 편이 거의 항상 더 수월하다.
✅ 마이크로벤치마킹을 하는 주요 유스케이스
하지만 어쩔 수 없이 코드 조각을 직접 성능 분석해야 할 때가 있다.
1. 사용 범위가 넓은 범용 라이브러리 코드를 개발한다
적용 범위가 넓기 때문에 유스케이스에 걸쳐 쓸만한 성능을 측정하기 위해 마이크로벤치마킹을 쓸 수 밖에 없는 때가 있다.
2. OpenJDK 또는 다른 자바 플랫폼 구현체를 개발한다
플랫폼 개발자는 마이크로벤치마크의 핵심 사용 커뮤니티를 형성하는 사람들이다.
-> JMH도 원래 OpenJDK 개발팀 본인들이 쓰려고 개발한 툴인데, 입소문이 나면서 세상에 알려지게 됐다.
3. 지연에 극도로 민감한 코드를 개발한다 (ex. 지연 거래)
주로 저지연 금융 거래 분야에서 쓰인다. 물론 이렇게 극단적인 애플리케이션이 아니라면 마이크로벤치마크를 삼가하는 것이 좋다.
JMH 프레임워크
✅ JMH 소개
JMH는 앞서 거론한 마이크로벤치마크의 이슈들을 해소하고자 개발된 프레임워크다.
JVM을 빌드한 사람들이 직접 만든 프레임워크라서,
JMH 제작자는 JVM 버전별로 숨겨진 함정을 어떻게 피하는지 누구보다 잘 알고 있다.
✅ JMH가 고려한 핵심적인 이슈
1. 애너테이션을 통한 동적 대응
벤치마크 프레임워크는 런타임에 벤치마크 내용을 알 수 있으므로 동적이어야 한다.
-> 그래서 JMH는 벤치마크 코드에 애너테이션을 부텨 자바 소스를 추가 생성하는 식으로 작동한다.
2. 루프 최적화 회피
JMH는 벤치마크 코드가 루프 최적화에 걸리지 않을 정도로 조심스레 반복 횟수를 설정한 루프 안에 감싸 넣는다.
벤치마크 실행
✅ JMH 프로젝트 생성
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DgroupId=org.sample \
-DartifactId=test \
-Dversion=1.0해당 명령을 통해 프로젝트를 생성하면, JMH를 사용하기 위한 기본적인 라이브러리를 의존한다.
✅ 블랙홀
일반적으로 JVM은 메서드 내에 실행된 코드가 side effect를 전혀 일으키지 않고,
그 결과를 사용하지 않을 경우 메서드를 삭제 대상으로 삼는다.
-> JMH는 이런 일이 없도록 메서드가 반환한 결과를 블랙홀에 할당한다.
블랙홀은 벤치마크가 과최적화되지 않게 하거나 런타임에 데이터 패턴을 예측하지 않게 한다.
- 런타임에 죽은 코드를 제거하는 최적화를 못 하게 한다.
- 반복되는 계산을 상수 최적화하지 않게 만든다.
- 값을 읽거나 쓰는 행위가 현재 캐시 라인에 영향을 끼치는 잘못된 공유 현상을 방지한다.
- 쓰기 장벽(리소스가 포화되서 병목을 초래하는 지점)으로부터 보호한다.
ex) 벤치마크시, 어떤 메서드의 리턴 값이 int 타입이고 이는 블랙홀에 할당한다면?
Blackhole 클래스의 consume 메서드를 수행한다.
public volatile int i1 = 1, i2 = 2;
public final void consume(int i) {
if (i == i1 & i == i2) {
// SHOULD NEVER HAPPEN
nullBait.i1 = i; // implicit null pointer exception
}
}
여기서 i1, i2는 volatile로 선언된 변수라서 런타임은 반드시 이 두 변수를 재평가해야 한다.
consume 메서드의 조건문은 true가 될 일은 없지만, 컴파일러는 어떻게든 이 코드를 실행시켜야 한다.
-> 따라서, consume 메서드를 통해 int i 라는 리턴값을 죽은 코드로 인식하지 않아, JVM의 최적화로부터 보호할 수 있다.
✅ 벤치마크 예시
앞서 만든 프로젝트로부터 정렬 알고리즘을 벤치마크하는 예제를 만들었다.
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@OutputTimeUnit(TimeUnit.SECONDS)
@Fork(1)
public class SortBenchmark {
private static final int N = 1_000;
private static final List<Integer> testData = new ArrayList<>();
@Setup
public static final void setUp() {
Random randomGenerator = new Random();
for (int i = 0; i < N; i++) {
testData.add(randomGenerator.nextInt(Integer.MAX_VALUE));
}
System.out.println("Setup Complete");
}
@Benchmark
public List<Integer> classicSort() {
List<Integer> copy = new ArrayList<Integer>(testData);
Collections.sort(copy);
return copy;
}
@Benchmark
public List<Integer> standardSort() {
return testData.stream().sorted().collect(Collectors.toList());
}
@Benchmark
public List<Integer> parallelSort() {
return testData.parallelStream().sorted().collect(Collectors.toList());
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(SortBenchmark.class.getSimpleName())
.warmupIterations(100)
.measurementIterations(5).forks(1)
.jvmArgs("-server", "-Xms2048m", "-Xmx2048m")
.addProfiler(GCProfiler.class)
.addProfiler(StackProfiler.class)
.build();
new Runner(opt).run();
}
}애노테이션 등 각각의 요소는 필요에 따라 찾아보면 되고,
중요한 것은 @Benchmark가 붙은 메서드가 바로 마이크로벤치마크 대상이라는 것이다.
실행 결과는 다음과 같다.
Benchmark Mode Cnt Score Error Units
SortBenchmark.classicSort thrpt 5 32043.982 ± 1610.448 ops/s
SortBenchmark.standardSort thrpt 5 25729.306 ± 638.092 ops/s
SortBenchmark.parallelSort thrpt 5 11366.336 ± 715.909 ops/s
얼핏 보면 스트림을 쓰는 것보다 고전적인 방법으로 정렬하는게 더 낫다는 결론을 내리기 쉽다.
✅ 마이크로벤치마크의 위험성
그러나 이 벤치마크가 성능을 정확히 반영하지 못한 부분은 없을까?
앞서 벤치마크한 세 메서드의 가비지 수집의 영향도를 알아보자.
Benchmark Mode Cnt Score Error Units
SortBenchmark.classicSort:gc.alloc.rate thrpt 5 221.653 ± 11.139 MB/sec
SortBenchmark.standardSort:gc.alloc.rate thrpt 5 552.517 ± 13.655 MB/sec
SortBenchmark.parallelSort:gc.alloc.rate thrpt 5 906.390 ± 56.907 MB/sec
이처럼 GC 비율이 다르니, 이는 성능에 영향을 줄 수 밖에 없다.
-> 이처럼 JMH 같은 툴을 쓰더라도 통제되지 않은 변수에 대해 각별히 잘 살펴야 한다.
JVM 성능 통계
오차 유형
✅ 계통 오차
원인을 알 수 없는 요인이 상관관계 있는 형태로 측정에 영향을 미친다.
정확도: 계통 오차를 나타내는 용어, 정확도가 높으면 계통 오차가 낮다.
ex) 만약 어떤 애플리케이션의 여러 서비스를 테스트한다고 했을 때, 모두 응답시간이 대체로 일정하다면?
확인 결과, 테스트 대상 서버와 테스트를 하는 곳의 거리가 매우 멀어 네트워크 지연 시간이 응답 시간의 대부분을 차지했다.
→ 계통 효과가 큰 것이 문제인 사례
✅ 랜덤 오차
측정 오차 또는 무관계 요인이 어떤 상관관계 없이 결과에 영향을 미친다.
정밀도: 랜덤 오차를 나타내는 용어, 정밀도가 높으면 랜덤 오차가 낮다.
ex) 소프트웨어에서 랜덤 오차의 근원은 보통 운영 환경이다.
랜덤 오차는 대부분 정규분포를 따른다. (성능지표-오차확률)
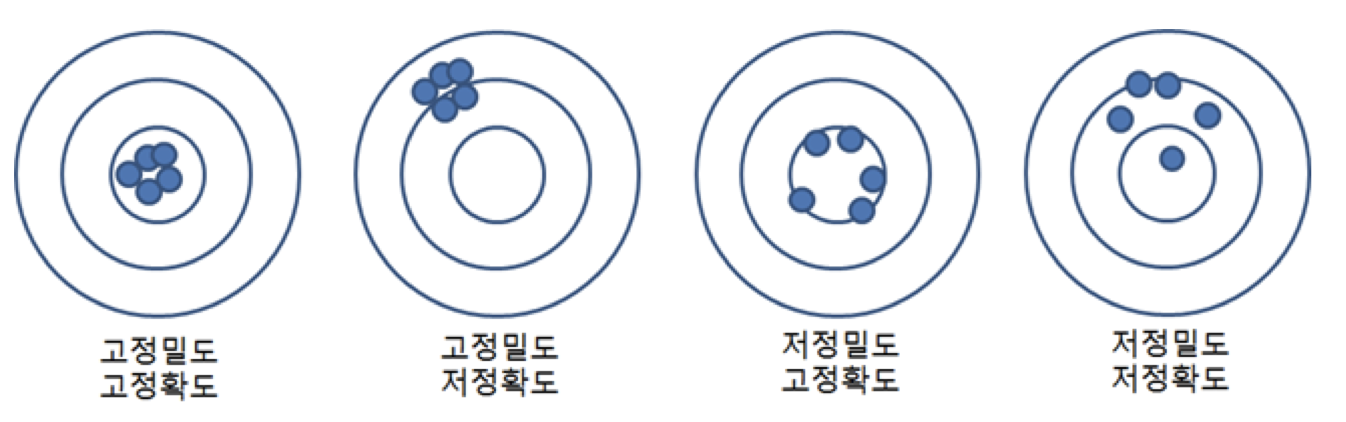
✅ 허위 상관
두 변수가 비슷하게 움직인다고 해서 이들 사이에 연결고리가 있다고 볼 수는 없다.
또한, 아무 관계도 없는 측정값에서도 상관관계가 발견되는 경우가 있다.
비정규 통계학
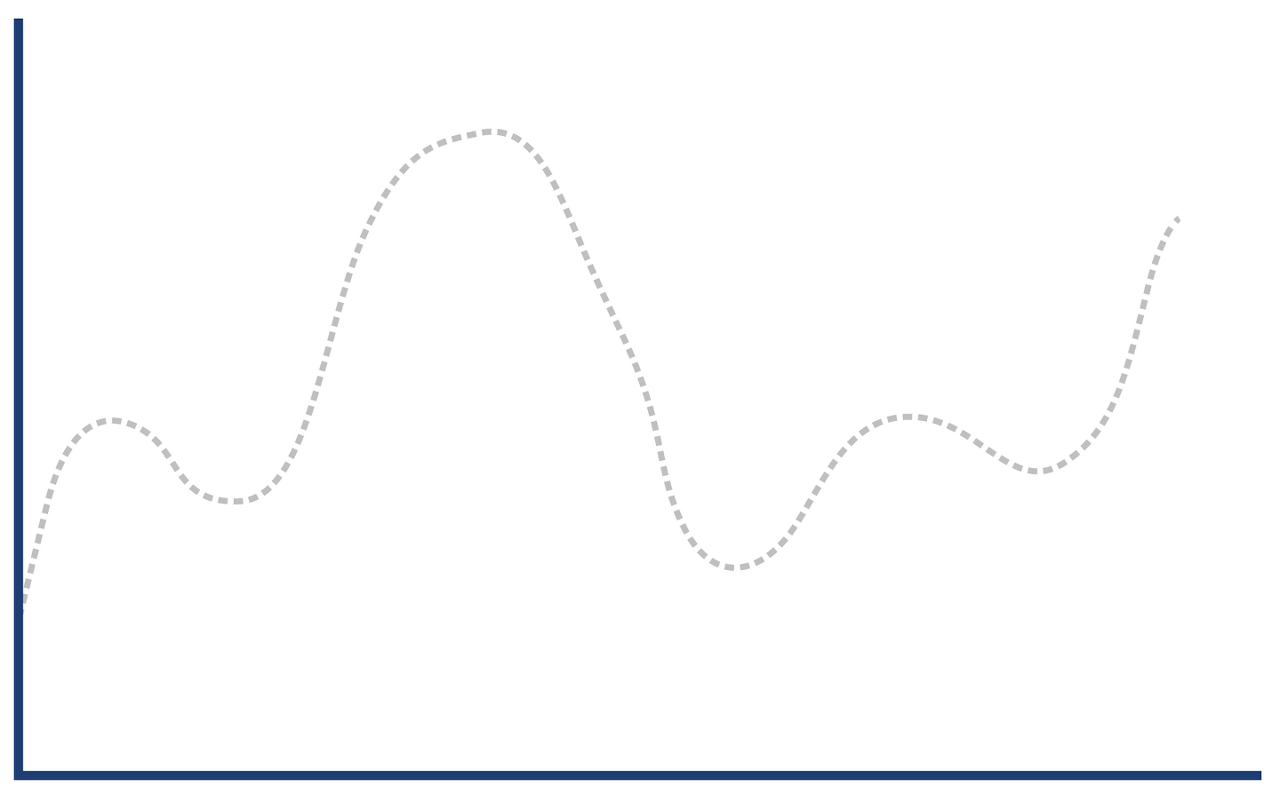
✅ 긴 꼬리형 비정규 분포
메서드(또는 트랜잭션) 시간 분포는 사실 정규 분포와는 거리가 멀고,
JIT 컴파일과 GC 사이클이 없는 핫 패스를 포함한다면, 다음과 같은 '긴 꼬리형 비정규 분포'를 띈다.
✅ 정규 분포와는 다르게 분석
정규 분포와는 다르게 긴 꼬리형임을 감안해, 90% 백분위 수를 차례로 구해,
데이터 형상에 더 적합한 패턴에 따라 샘플링한다.
50.0% level was 23ns
90.0% level was 30ns
99.0% level was 43ns
99.9% level was 164ns
99.99% level was 248ns
99.999% level was 3,458ns
99.9999% level was 17,463ns그 결과,
- 메서드 하나를 실행하는데 평균 23ns가 걸렸고,
- 요청 1,000개당 하나는 (99.9%) 실행 시간이 한 크기 정도로 나빠지며,
- 요청 100,000개당 하나는 실행시간이 두 크기 정도 나빠진다는 사실을 알 수 있다.
+) 여기서 한 크기 나빠진다는 건 평균 실행시간의 10배 (23 * 10 = 230) 느려진다는 것이고, 두 크기 나빠진다는 건 100배 (23 * 100 = 2300) 느려진다는 뜻이다.
✅ 더 정교한 분석
긴 꼬리형 분포는 HdrHistogram이라는 공개 라이브러리를 이용하면 좀 더 정교한 분석이 가능하다.
<dependency>
<groupId>org.hdrhistogram</groupId>
<artifactId>HdrHistogram</artifactId>
<version>2.1.10</version>
</dependency>
ex) 간단한 HdrHistogram 예제
public class BenchmarkWithHdrHistogram {
private static final long NORMALIZER = 1_000_000;
private static final Histogram HISTOGRAM = new Histogram(TimeUnit.MINUTES.toMicros(1), 2);
public static void main(String[] args) throws Exception {
final List<String> values = Files.readAllLines(Paths.get(args[0]));
double last = 0;
for (final String tVal : values) {
double parsed = Double.parseDouble(tVal);
double gcInterval = parsed - last;
last = parsed;
HISTOGRAM.recordValue((long) (gcInterval * NORMALIZER));
}
HISTOGRAM.outputPercentileDistribution(System.out, 1000.0);
}
}
<결과>
Value Percentile TotalCount 1/(1-Percentile)
10.05 0.000000000000 1 1.00
10.05 0.100000000000 1 1.11
991.23 0.200000000000 2 1.25
991.23 0.300000000000 2 1.43
1302.53 0.400000000000 3 1.67
1302.53 0.500000000000 3 2.00
1376.26 0.550000000000 4 2.22
1376.26 0.600000000000 4 2.50
1376.26 0.650000000000 4 2.86
1835.01 0.700000000000 5 3.33
1835.01 0.750000000000 5 4.00
1835.01 0.775000000000 5 4.44
1835.01 0.800000000000 5 5.00
1835.01 0.825000000000 5 5.71
4620.29 0.850000000000 6 6.67
4620.29 1.000000000000 6
#[Mean = 1684.10, StdDeviation = 1418.82]
#[Max = 4620.29, Total count = 6]
#[Buckets = 19, SubBuckets = 256]
긴 꼬리형 분포를 띄는 듯 한데, 맨자료만 봐서는 분석하기 쉽지 않다.
HdrHistogram은 이런 자료를 히스토그램으로 보기 좋게 표시하는 온라인 포매터를 제공하니 참고하면 좋다.
통계치 해석
✅ 복잡한 통계치 분석
ex) HTTP 요청-응답 시간을 측정한 히스토그램
복잡해 보이는 그림이지만, 간단한 그림 몇 개로 구성할 수 있다.
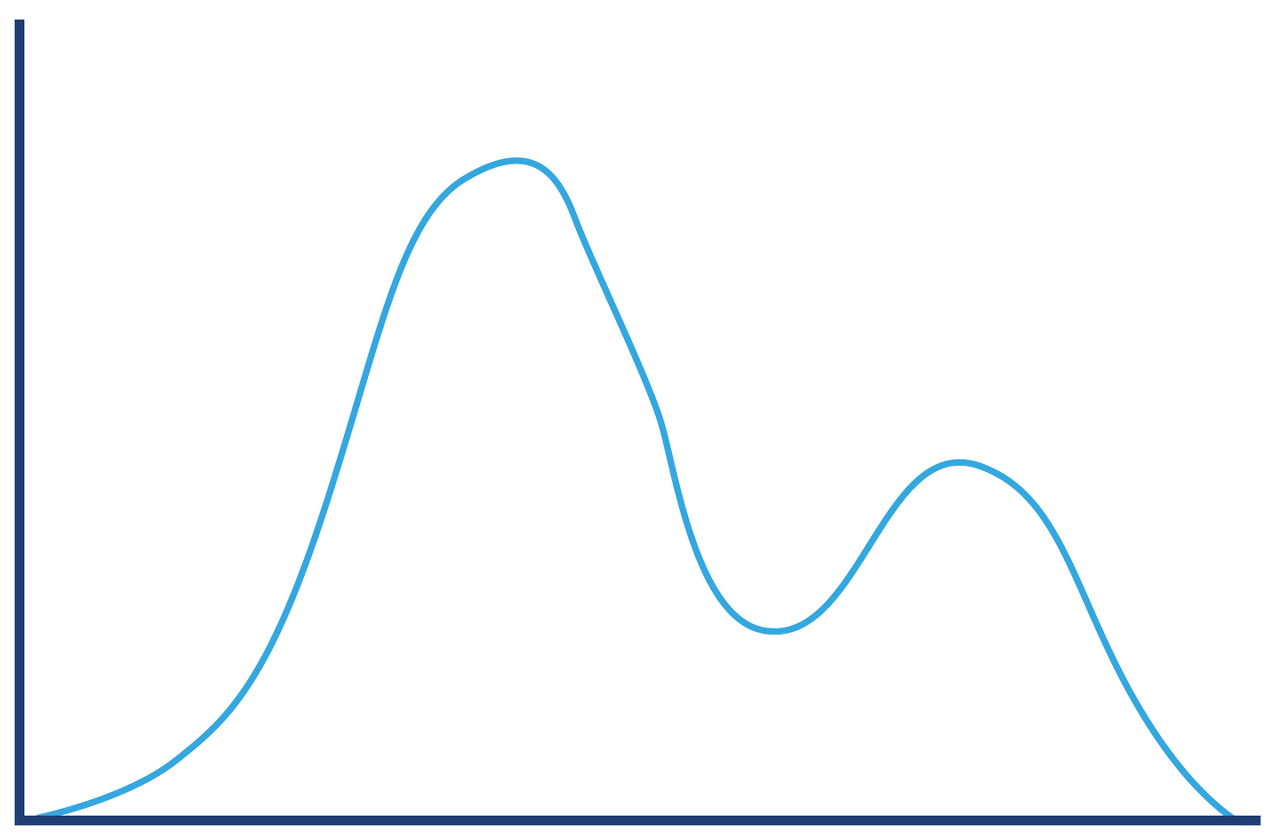
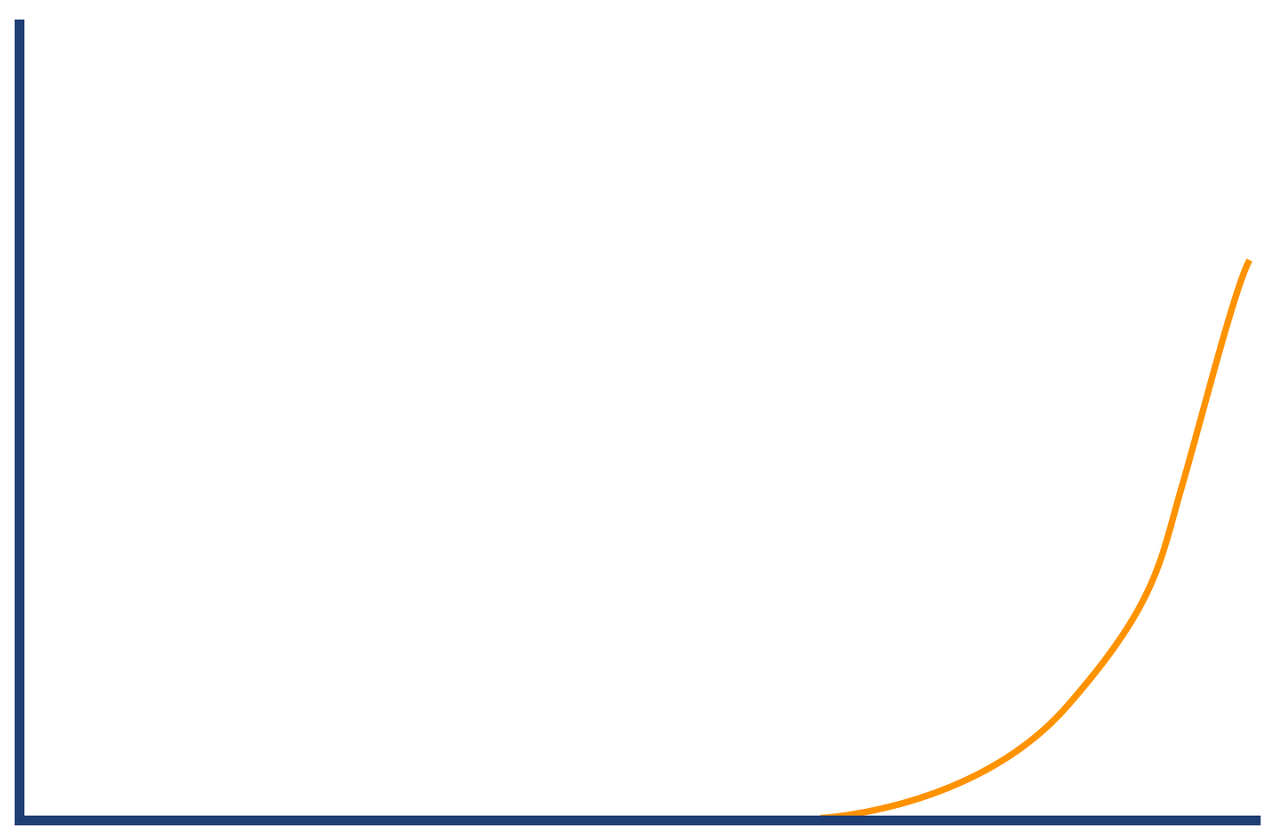
이처럼 일반적인 측정값을 보다 유의미한 하위 구성 요소들로 분해하는 개념은 아주 유용하다.
-> 데이터 및 도메인을 충분히 이해하고, 데이터를 더 작은 집합으로 쪼갠다.
참고자료
https://medium.com/paypal-tech/statistics-for-software-e395ca08005d
'book > 자바 최적화' 카테고리의 다른 글
| [자바 최적화] 가비지 수집 고급 (0) | 2023.08.29 |
|---|---|
| [자바 최적화] 가비지 수집 기초 (2) | 2023.08.28 |
| [자바 최적화] 성능 테스트 패턴 및 안티패턴 (2) | 2023.08.10 |
| [자바 최적화] 하드웨어와 운영체제 (0) | 2023.07.30 |
| [자바 최적화] JVM이야기 (0) | 2023.07.23 |