![[DDD] 도메인 주도 개발을 실제로 적용해보면서](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F2sYBh%2FbtsnSYTOEkM%2Fjq0vkB5w4II9dMPAHkZEAk%2Fimg.png)
DDD를 공부하고 프로젝트에 적용한 부분을 중심으로 기록한다.
앞 내용은 대부분 이론 내용이니, 실제 개발을 해보며 느낀점은 글의 마지막 부분을 참고하자.
도메인 주도 개발
도메인
도메인이란 소프트웨어로 해결하고자 하는 문제 영역에 해당한다.
→ 요구사항으로 볼 수 있다.
+) 개발자는 도메인 설계를 위해 요구사항을 정확히 숙지하여야 하며 도메인 전문가와 꾸준히 소통할 수 있어야 한다.
도메인 모델
도메인 모델은 특정 도메인을 개념적으로 표현한 것이다.
→ 도메인 자체를 이해하기 위한 개념 모델이다.
도메인이 지니고 있는 특성과 기능을 파악할 수 있다.
ex) 객체 기반 모델
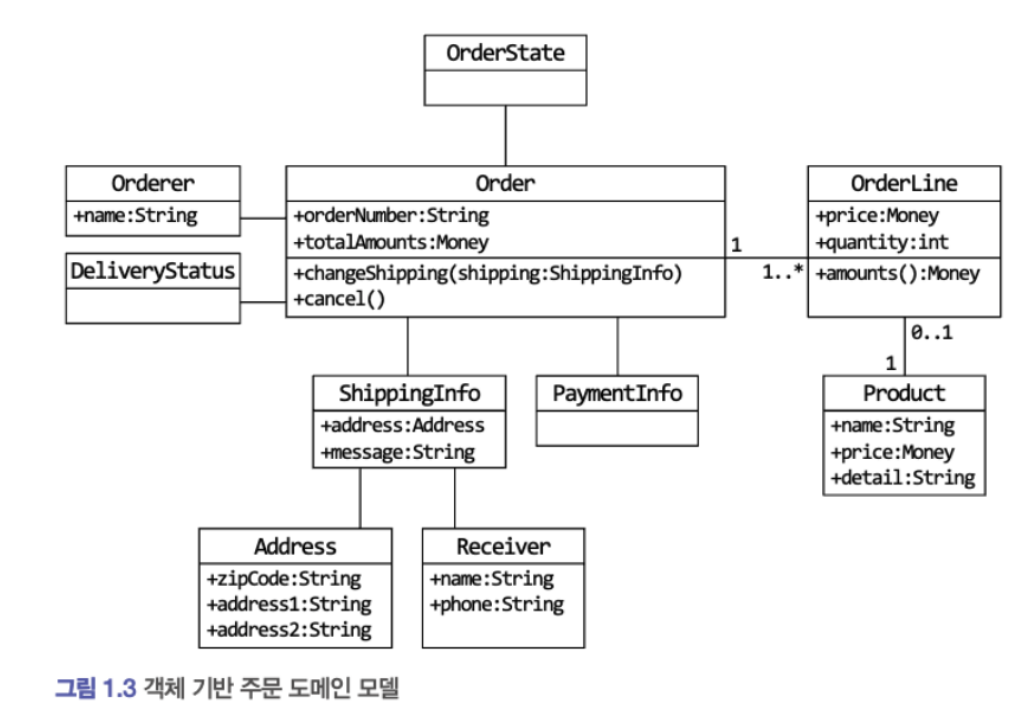
도메인 모델 설계
요구사항 분석을 통해 도메인에 대한 초기 모델을 설계한다.
예를 들어 다음과 같은 요구사항이 있을 때,
- 계좌간 유니크한 계좌번호가 있어야 한다.
- 계좌의 잔액을 조회할 수 있어야 한다.
- 계좌간 입출금을 할 수 있어야 한다.
다음과 같은 도메인 모델을 설계할 수 있다.
public class Account {
@Id
private String accountNumber;
private Long balance;
public Long getBalance() {
return balance;
}
public void withdraw(Long transferAmount) {
balance -= transferAmount;
}
public void deposit(Long transferAmount) {
balance += transferAmount;
}
}
중요한 것은 요구사항을 분석함으로써 도메인 모델이 지니고 있어야 할 상태(데이터)와 기능을 찾을 수 있다는 것이다.
엔티티
엔티티는 식별자를 가진다. 그리고 바뀌지 않는다.
→ 엔티티의 식별자는 고유하므로 두 엔티티의 식별자가 같으면 두 엔티티는 같다고 판단할 수 있다.
식별자를 생성하는 방법은 도메인의 특징과 사용하는 기술에 따라 달라진다.
- 특정 규칙에 따라 생성
- UUID나 Nano ID와 같은 고유 식별자 생성기 사용
- 값을 직접 입력
- 일련번호 사용(auto increment, sequence 등)
Account는 accountNumber를 식별자로 가진다. (3. 값을 직접 입력)
처음에는 auto increment를 통한 정수 id를 가졌는데, 실질적으로 로직에서 거의 사용하지 않고, 클라이언트와 서버 모두 잘 모르는 값을 식별자로 삼는 것보다 명확한 계좌번호를 식별자로 정했다.
+) 또한, 계좌번호는 절대 수정될 수 없다.
참고: PK: UUID vs Auto Increment
나는 도메인 모델인 Account를 엔티티 객체로 잡았다.
일반적으로 엔티티는 DB를 패키징하는 역할만 하고, 도메인 관련해 데이터와 기능을 갖는 도메인 객체를 따로 만들어 사용하는 일례가 있지 만,
내가 진행한 프로젝트 규모에서는 비즈니스 로직이 많지 않고, Account 엔티티를 도메인 객체로 확장해도 데이터를 옮기는 수준의 작업만 하게 될 것 같아서,
우선 엔티티를 도메인 모델로 삼기로 결정했다.
도메인 용어
도메인에서 사용하는 용어를 코드에 반영하는 것은 매우 중요하다.
그렇지 않으면 개발자는 코드의 의미를 해석해야 하는 부담을 갖게 된다.
예를 들어, 이체 검증, 이체, 이체 완료의 일련의 과정이 있다고 하면 이를 코드 상에서 STEP1, STEP2, STEP3라는 표현을 사용할 수 있 다.
이런 경우 개발자는 코드 ↔ 도메인 용어 해석 과정에서 어려움을 겪게 될 것이다.
validateTransfer, Transfer와 같은 명확한 단어를 사용하는 것이 좋다.
+) 심지어 코드에 한글을 사용하는 경우도 있다.
권장되는 방식은 기획자, 개발자가 도메인과 관련된 공통의 언어를 만들고,
대화, 문서, 도메인, 코드 등 모든 곳에서 같은 용어를 사용하는 것이다.
+) 상당히 기본적이면서 중요한 내용이라고 생각한다. 클린코드 '의미 있는 이름' 챕터가 왜 가장 먼저 소개되는지 알 것도 같다.
아키텍처
계층 구조 아키텍처
다음과 같이 네 개의 계층으로 구성된다.
- 표현: 사용자의 요청을 처리하고 사용자에게 정보를 보여준다.
- 응용: 사용자가 요청한 기능을 실행한다. 비즈니스 로직을 직접 구현하지 않으며, 도메인 계층을 조합해서 기능을 실행한다.
- 도메인: 시스템이 제공할 도메인 규칙을 구현한다.
- 인프라스트럭처: 데이터베이스와 같은 외부 시스템과의 연동을 처리한다.
계층 구조의 의존은 상황에 따라 유연함이 있을 수 있다.
예를 들어, 응용 계층은 바로 아래인 도메인 계층에 의존하지만, DB와 접근하기 위해 바로 인프라스트럭처 계층에 의존하기도 한다.
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
public class AccountService { // 응용 계층 서비스
private final AccountRepository accountRepository; // 인프라스트럭처 계층 레포지토리
public AccountsGetResponseDto findAccounts(AccountsGetRequestDto requestDto, Pageable pageable) {
Slice<Account> accounts = accountRepository.findAllByUser(requestDto.getUser(), pageable)
return AccountsGetResponseDto.from(accounts);
}
}
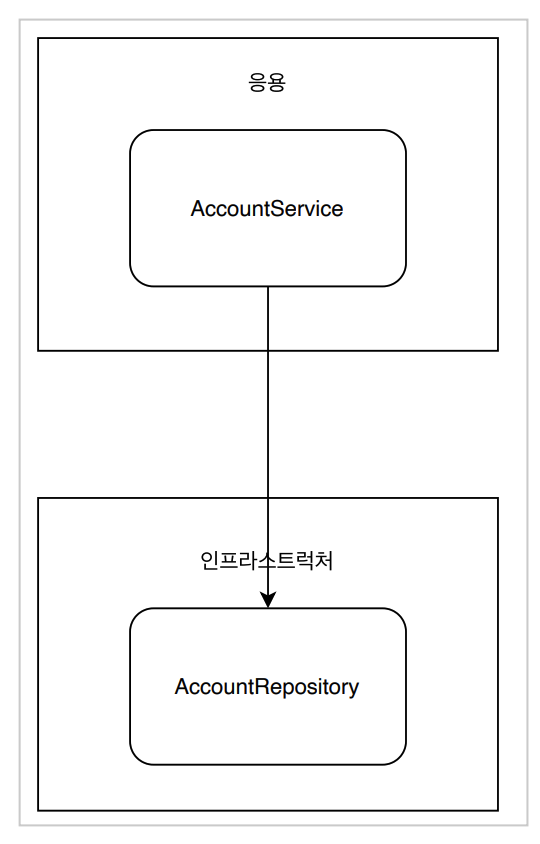
그러나 이 방식은 문제를 안고 있다.
- AccountService만 테스트하기 어렵다 → 이 클래스를 테스트하려면 AccountRepository가 완벽하게 동작해야 한다. AccountRepository 클래스를 모두 만든 이후에 비로소 테스트가 가능하다.
- 구현 방식을 변경하기 어렵다 → 만약 AccountRepository가 JPA가 아닌 Mybatis 방식을 사용한다고 하면 AccountService의 코드도 함께 변경해야 한다. (OCP 위반)
DIP
의존관계를 갖는 인스턴스의 구성이 추상화에 의존하는 것을 뜻한다.
+) DIP 관련 용어에 대한 자세한 설명 참고: 의존성 역전 원리(DIP) 관련 용어
DIP는 저수준 모듈(하위 계층)이 고수준 모듈(상위 계층)에 의존하도록 바꾸며, 이는 추상화한 인터페이스를 통해 이루어진다.
- 고수준 모듈 계층에서 필요한 수준으로 인터페이스를 추상화한다.
- 고수준 모듈은 이 인터페이스를 의존하고, 저수준 모듈은 이 인터페이스를 구현한다.
- 실제 사용할 저수준 구현 객체는 의존 주입을 통해서 전달 받는다.
즉, AccountService가 AccountRepository 클래스를 직접 의존하는 것이 아닌,
AccountRepository 인터페이스를 의존하고, AccountRepositoryImpl과 같은 구현체를 인프라스트럭처 계층에 생성하는 것이 앞선 문제 를 해결하는 더 적절한 설계라고 할 수 있다.
이렇게 하면 실제 레포지토리 구현체가 없어도, 인터페이스에 대한 mock을 통해 테스트를 진행할 수 있다.
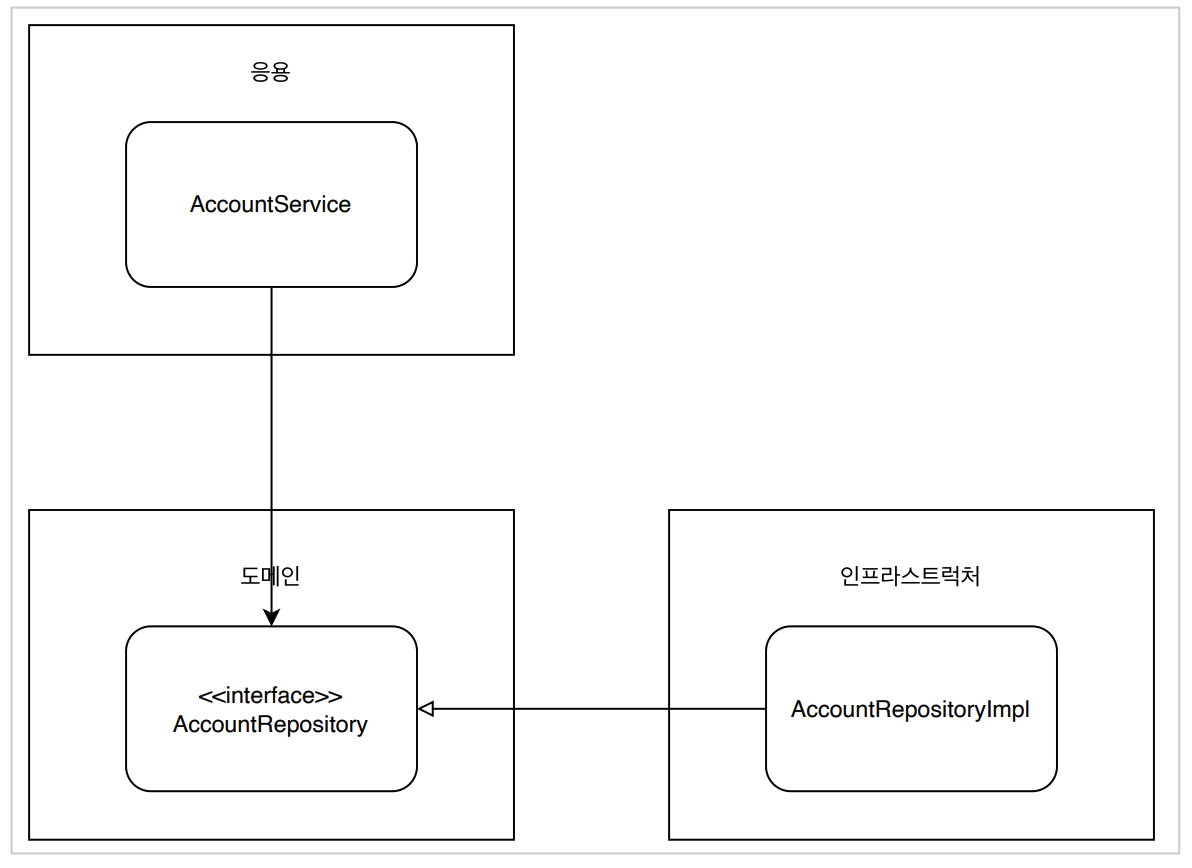
실무적인 관점
1. 무조건 다른 계층에서 인프라스트럭처에 대한 의존을 없앨 필요는 없다.
예를 들어 스프링의 응용 서비스는 트랜잭션 처리를 위해 스프링이 제공하는 @Transactional을 사용하는 것이 편리하다.
JPA를 사용할 경우 @Entity나 @Table과 같은 JPA 애노테이션을 도메인 모델 엔티티에 사용하는 것이 XML 매핑 설정을 이용하는 것보 다 편리하다.
만약 응용 계층에서 @Transactional 애노테이션을 사용하지 않고 트랜잭션을 관리하려 한다면? 배보다 배꼽이 더 클 수 있다.
→ 계층간 독립성과 적당한 허용에 대한 편의성 간에 유연한 사고가 필요하다.
2. 인프라스트럭처 계층을 꼭 사용해야 하는가
일반적으로 Spring Data JPA를 사용하는 방식은 다음과 같다.
public interface AccountRepository extends JpaRepository<Account, String> {
}
리포지토리는 인터페이스이기 때문에 도메인 영역에 생성하고 그 구현체를 인프라스트럭처 계층에 생성한다고 생각할 수 있다.
그러나 해당 인터페이스는 이미 JpaRepository를 의존하고 있다. 이미 JPA 기술을 사용한다고 못박아 놓은 것이다.
→ 해당 인터페이스를 확장해 JPA 말고 여러 기술을 활용한다는 논리에 어긋난다.
도메인 영역의 인터페이스도 JPA를 사용한다고 하고, 인프라스트럭처 영역의 구현체도 JPA를 사용하고 있다면 둘의 계층을 나눈 이유가 불명확하다.
또한 현재 프로젝트 특성상 JPA를 사용 안하는 경우는 거의 없을 것 같다면?
→ 해당 사고에 따라 나는 인프라스트럭처 계층을 없애고 리포지토리 관련한 모든 객체를 도메인 영역에 배치시켰다.
→ 인프라스트럭처 계층은 정말 해당 기술에 대한 확장 가능성이 있는지에 대해 꼼꼼히 따져볼 필요가 있을 것이다.
도메인 영역 구성요소
엔티티와 밸류
도메인 모델의 엔티티와 DB 모델의 엔티티의 가장 큰 차이점은 도메인 모델의 엔티티는 데이터와 함께 도메인 기능을 함께 제공한다는 점이 다.
또 다른 차이점은 도메인 모델의 엔티티는 두 개 이상의 데이터가 개념적으로 하나인 경우 밸류 타입을 이용해서 표현할 수 있다는 것이다.
애그리거트
도메인이 커지면서 많은 엔티티가 출현하고 점점 더 복잡해진다.
→ 이 때 개별 도메인에 일일이 초점을 맞추다 보면 큰 틀에서 도메인 모델을 관리할 수 없는 상황에 빠질 수 있다.
애그리거트를 사용하면 관련 객체를 묶어서 객체 군집 단위로 모델을 바라볼 수 있게 된다. 애그리거트는 군집에 속한 대표 도메인인 루트 엔 티티를 갖는다.
→ 애그리거트를 사용하는 코드는 루트 엔티티가 제공하는 기능을 실행하고, 루트를 통해 애그리거트 내의 다른 엔티티에 접근한다.
+) 현재 프로젝트는 엔티티의 수가 많지 않기 때문에 따로 애그리거트 개념을 도입하지 않았다.
리포지터리
필요한 객체를 물리적인 저장소에서 구하거나 저장할 때 리포지터리를 사용한다.
엔티티처럼 요구사항에서 도출되는 도메인 모델이 아닌 리포지터리는 구현을 위한 도메인 모델이다.
리포지터리는 애그리거트 단위로 도메인 객체를 저장하고 조회하는 기능을 정의한다.
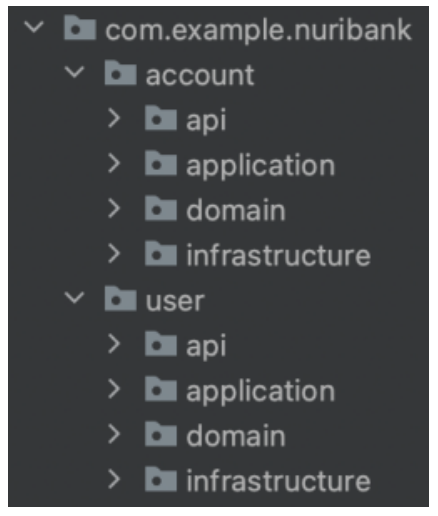
패키지 구성
패키지 구성에 정답이 존재하는 것은 아니지만 앞서 소개한 DDD 계층 구조 방식을 패키지에 적용하면 다음과 같다.
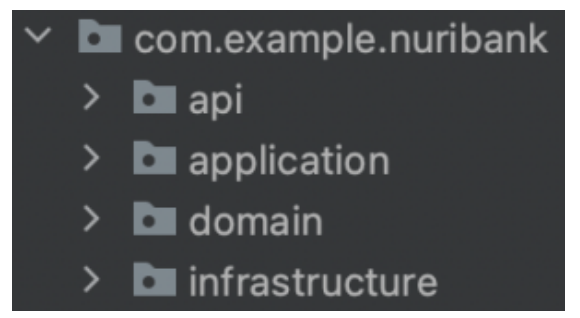
- API - 표현 계층
- application - 응용 계층
- domain - 도메인 계층
- infrastructure - 인프라스트럭처 계층
도메인 계층은 도메인에 속한 하위 도메인(애그리거트)으로 패키지를 구성할 수 있다.

각 도메인마다 엔티티, 도메인 서비스, 리포지터리는 같은 패키지에 위치시켰다.
만약 도메인이 복잡하면 도메인 서비스를 다음과 같이 별도 패키지에 위치시킬 수도 있다.
com.example.nuribank.domain.account.service → com.example.nuribank.domain.service
만약 도메인이 크면 다음과 같이 하위 도메인으로 나누고 각 하위 도메인마다 별도 패키지를 구성할 수 있다.
표현 영역
표현 영역의 역할을 다음의 세 가지와 같다.
- 사용자가 시스템을 사용할 수 있는 흐름(화면)을 제공하고 제어한다.
- 사용자의 요청을 알맞은 응용 서비스에 전달하고 결과를 사용자에게 전달한다.
- 사용자의 세션을 관리한다.
+) 값 검증
값 검증은 표현 영역과 응용 영역에서 모두 수행할 수 있다.
나는 표현 영역에서 필수 값이나 값 형식 등을 검사하고,
응용 영역에서 데이터의 존재 유무 등의 논리적인 오류를 검사한다.
+) 권한 검사
표현 영역에서 하는 검사는 인증된 사용자인지 아닌지 검사하는 것이다.
필터에서 사용자의 인증 정보를 생성하고 인증 여부와 권한을 검사하는 방법이 있다. (스프링 시큐리티)
현재 프로젝트는 사용자 인증에 대한 처리는 이미 되어 있다고 가정한다.
따라서 요청을 받아 응용 서비스를 호출하고 응답하는 정도의 컨트롤러 기능을 주로 사용하고 있다.
@PostMapping("/balance/get")
public ResponseEntity<BaseResponse> getBalance(@Valid @RequestBody AccountBalanceGetRequestDto requestDto) {
AccountBalanceGetResponseDto responseDto = accountService.findBalance(requestDto.getBalance());
return new ResponseEntity<>(BaseResponse.of(OK, responseDto), OK); // 결과 리턴
}
응용 서비스
응용 서비스의 주요 역할은 리포지터리에서 도메인 객체를 가져온 후, 이를 이용해서 사용자의 요청을 처리하는 것이다.
표현 영역 입장에서 보았을 때 응용 서비스는 도메인 영역과 표현 영역을 연결해주는 창구 역할을 한다.
응용 서비스는 주로 도메인 객체 간의 흐름을 제어하기 때문에, 다음과 같은 단순한 형태를 갖는다.
@Transactional // 응용 서비스는 트랜잭션을 관리한다.
public AccountBalanceGetResponseDto findBalance(AccountBalanceGetRequestDto requestDto) {
// 1. 리포지터리에서 도메인 객체를 가져온다.
Account account = inquiryAccountService.findByAccountNumber(requestDto.getAccountNumber());
// 2. 도메인 객체의 비즈니스 로직을 실행한다.
validateAccountService.validateUser(account, requestDto.getUserId()); // 도메인 서비스 호출
// 3. 결과를 리턴한다.
return AccountBalanceGetResponseDto.from(account);
}
새로운 객체를 생성하는 응용 서비스 예시는 다음과 같다.
@Transactional // 응용 서비스는 트랜잭션을 관리한다.
public TransferSaveResponseDto saveTransfer(TransferSaveRequestDto requestDto) {
// 1. 리포지터리에서 도메인 객체를 가져온다.
Account withdrawalAccount = inquiryAccountService.findByAccountNumberForUpdate(requestDto.getWithdrawalAccountNumber());
Account depositAccount = inquiryAccountService.findByAccountNumberForUpdate(requestDto.getDepositAccountNumber());
// 2. 도메인 객체를 생성한다.
Transfer transfer = createTransfer(withdrawalAccount, depositAccount, requestDto);
// 3. 리포지터리에 도메인 객체를 저장한다.
transferRepository.save(transfer);
// 4. 결과를 리턴한다.
return TransferSaveResponseDto.from(transfer);
}
응용 서비스는 이처럼 도메인 객체를 조회(저장)하고, 비즈니스 로직을 실행하고, 표현 계층에 결과를 반환하는 역할을 수행한다.
응용 서비스는 가능한 명확하고 단순해야 한다. 복잡하다면 비즈니스 로직의 일부를 구현하고 있을 가능성이 높다.
→ 응용 서비스를 통해 여러 도메인 간에 상호작용을 제어할 수 있다. DDD에서 중요한 요소라고 생각한다.
실무적인 관점
1. 응용 서비스에 인터페이스가 필요한가
나의 경우 대게 필요하지 않았다.
응용 서비스는 런타임에 교체하는 경우가 거의 없고, 보통 명확한 기능에 대한 서비스 형태를 취하기 때문에 확장의 가능성도 적다.
도메인 서비스
도메인 서비스는 도메인 영역에 위치한 도메인(비즈니스) 로직을 표현할 때 사용한다.
주로 다음 상황에서 도메인 서비스를 이용한다.
- 여러 도메인 객체가 필요한 기능: 한 도메인에 넣기 애매한 도메인 기능을 억지로 특정 도메인에 구현하면 복잡하다. 이럴 때는 별도 도메인 서비스를 구현함으로써 문제를 해결할 수 있다.
- 외부 시스템 연동이 필요한 도메인 로직: 구현하기 위해 타 시스템을 사용해야 하는 로직
+) 나는 여기에 추가로 하나의 도메인이더라도 그것이 복잡하거나 도메인 안에서 해결하기 어려울 때, 도메인 서비스를 사용했다.
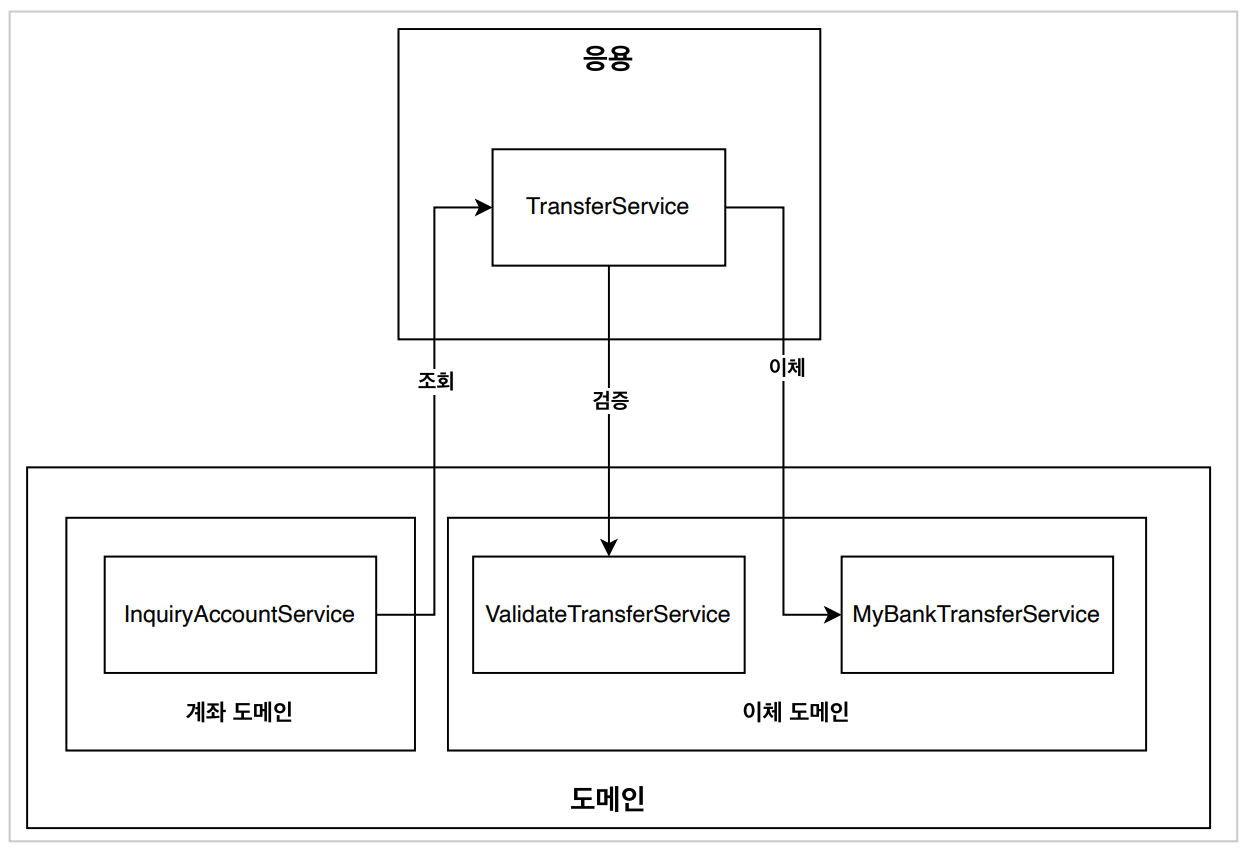
계좌 조회 - 특정 조건에 따라 도메인 조회
public Account findByAccountNumber(String accountNumber) {
Account account = accountRepository.findById(accountNumber)
.orElseThrow(() -> new EntityNotFoundException("[" + accountNumber + "] 해당 계좌번호에 대한 계좌가 존재하지 않습니다.");
if (account.getUsageStatus().equals(NO)) {
throw new UsageImpossibleException("[" + accountNumber + "] 현재 사용 가능한 계좌가 아닙니다.");
}
return account;
}
이체 - 도메인의 값을 변경
public void transfer(Account withdrawalAccount, Account depositAccount, Long transferAmount) {
withdrawalAccount.withdraw(transferAmount);
depositAccount.deposit(transferAmount);
}
응용서비스 - 도메인서비스 예시
DDD에 대한 고민
공부를 하면서 문득 생각이 들었다.
나는 DDD를 왜 하고 있지?
원초적이면서도 중요한 내용이라고 생각한다.
도메인 주도 개발의 여러 가지 장단점들은 인터넷에서 쉽게 볼 수 있지만, 내가 개발하면서 얻은 사고는 이렇다.
도메인이란 무엇일까? 도메인은 요구사항이고, 문제의 영역이다.
그리고 내가 관심있는 소프트웨어 개발은 도메인에 관련된 문제를 해결하는 것이다.
하나의 소프트웨어는 여러 개의 도메인으로 구분되고, 각 도메인들이 서로 상호작용 하며 문제를 해결한다.
DDD는 도메인에 특화된 로직들을 도메인에 책임을 부여하고,
사용자 관점의 응용 서비스들은 도메인 간에 상호작용을 위해 해당 도메인 로직들을 호출한다.
public AccountBalanceGetResponseDto findBalance(AccountBalanceGetRequestDto requestDto) {
Account account = inquiryAccountService.findByAccountNumber(requestDto.getAccountNumber());
validateAccountService.validateUser(account, requestDto.getUserId());
return AccountBalanceGetResponseDto.from(account);
}
"도메인을 가져와서 → 검증하고 → 결과를 반환하자"
해당 코드를 짜면서 느낀 것은 코드가 요구사항을 그대로 풀어 쓴 것 같다는 느낌을 받았다.
소프트웨어의 복잡성을 최소화하면서 요구사항을 쉽게 반영할 수 있는 구조가 문제 해결을 위한 좋은 구조라는 생각이 들었다.
"도메인 간 어떻게 독립적으로 관리할 수 있을까"라는 사고에서,
더 근본적으로 "문제해결을 위해 어떻게 도메인들을 다룰 수 있을까" 에 대한 고민으로 발전했고,
이에 따라 DDD에 관심이 생겼던 것 같다.
여기까지 DDD를 공부하고 프로젝트에 적용하면서 이해한 내용들이다.
아직 많이 부족하다고 느끼지만 천천히 배워 나가고 있다.
'ddd' 카테고리의 다른 글
| [DDD] 조용호님 특강: 도메인 주도 설계의 사실과 오해 (2) | 2023.07.08 |
|---|