![[Kotlin] 코틀린에서의 FP](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FekLKQO%2FbtsiuNiudJ8%2F4XynHkW3VqIDPLj0TKKjok%2Fimg.png)
자바 개발자를 위한 코틀린 입문(Java to Kotlin Starter Guide)
자바 개발자를 위한 코틀린 입문(Java to Kotlin Starter Guide) - 인프런 | 강의
이 강의를 통해 Kotlin 언어의 특성과 배경, 문법과 동작 원리, 사용 용례, Java와 Kotlin을 함께 사용할 때에 주의할 점 등을 배울 수 있습니다., - 강의 소개 | 인프런
www.inflearn.com
강의를 들으며 내용 정리
코틀린에서 배열과 컬렉션을 다루는 방법
배열
사실 배열은 잘 사용하지 않는다. 이펙티브 자바에서도 리스트를 사용할 것을 권장한다.
그래도 간략한 문법은 알아두자.
<java>
int[] array = {100, 200};
for (int i = 0; i < array.length; i++) {
System.out.printf("%s %s", i, array[i]);
}
<kotlin>
val array = arrayOf(100, 200)
for (i in array.indices) {
println("${i} ${array[i]}")
}array.indices는 0부터 마지막 index까지의 Range이다.
for ((idx, value) in array.withIndex()) {
println("${idx} ${value}")
}withIndex()를 사용하면, 인덱스와 값을 한 번에 가져올 수 있다.
array.plus(300)값을 쉽게 넣을 수도 있다.
코틀린에서의 Collection - List, Set, Map
코틀린에서 컬렉션은 불변인지, 가변인지를 설정해야 한다.
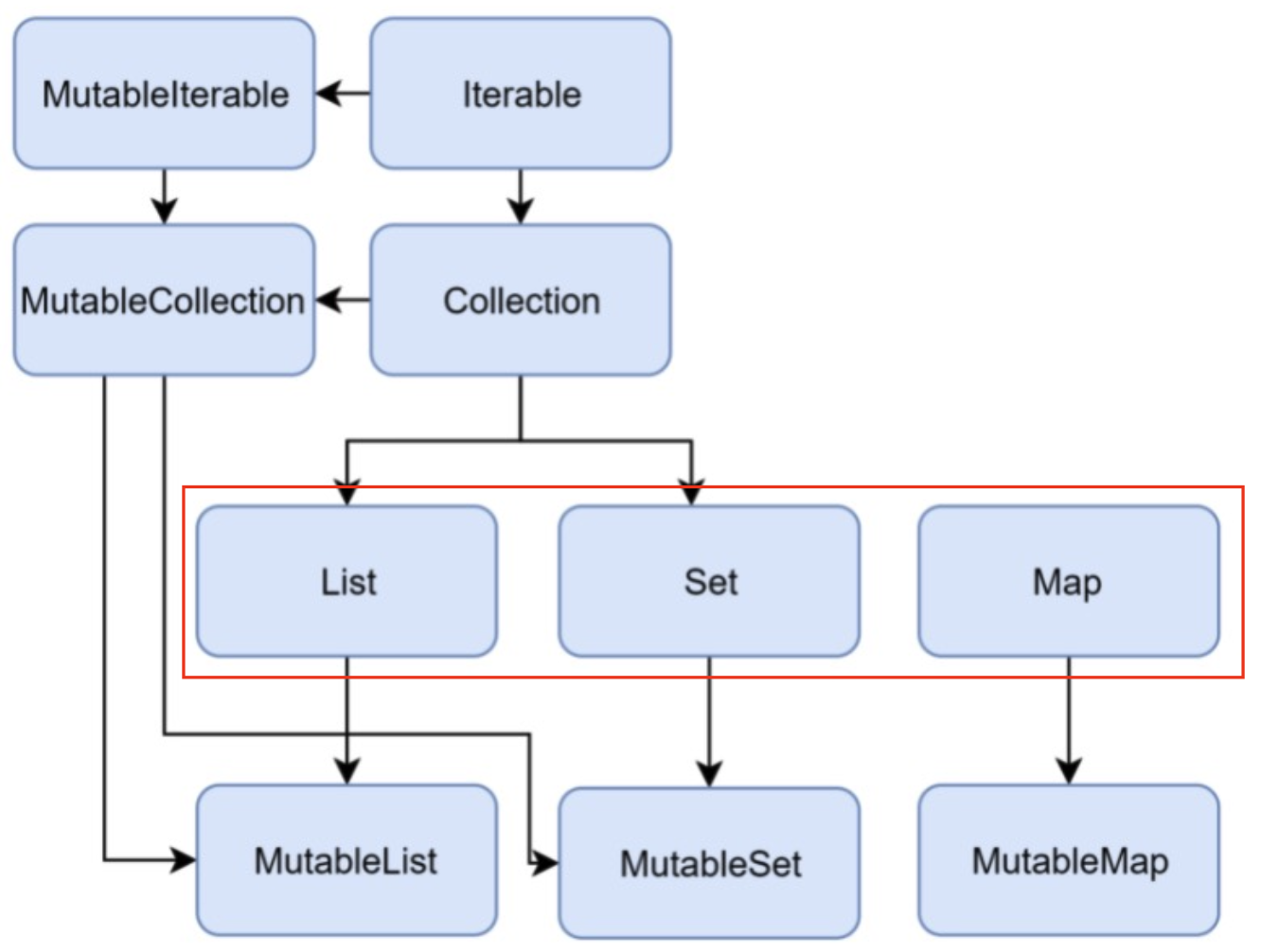
빨간 박스 친 곳이 자바와 동일한 이름의 컬렉션이자, 불변 컬렉션이고, (컬렉션에 element를 추가, 삭제할 수 없다)
Mutual로 시작하는 컬렉션이 가변 컬렉션이다. (컬렉션에 element를 추가, 삭제할 수 있다)
+) 물론 불변 컬렉션이라 하더라도 Reference Type인 element의 필드는 바꿀 수 있다.
ex) 불변List = [Money(price=1000), Money(price=2000)] -> [Money(price=5000), Money(price=2000)]
List
코틀린은 불변/가변을 지정해 주어야 한다는 사실을 기억하고, 다음 예시를 보자.
<java>
final List<Integer> numbers = Arrays.asList(100, 200);
<kotlin>
val numbers = listOf(100, 200)
val emptyList = emptyList<Int>() // 타입 명시적으로 적어줌불변 리스트 예시이다.
listOf(100, 200)처럼 element에 따라 타입을 추론할 수 있는 경우 타입을 적어줄 필요 없지만,
emptyList의 경우 빈 리스트이기 때문에 타입을 명시적으로 적어줘야 한다.
useNumbers(emptyList()) // 타입 추론
private fun useNumbers(numbers: List<Int>) {
}물론 이렇게 타입을 추론할 수 있는 경우라면 생략 가능하다.
다음 예시를 보자.
<java>
// 하나를 가져오기
System.out.println(numbers.get(0));
// For Each
for (int number : numbers) {
System.out.println(number);
}
// 전통적인 For문
for (int i = 0; i < numbers.size(); i++) {
System.out.printf("%s %s", i, numbers.get(i));
}
<kotlin>
// 하나를 가져오기
println(numbers[0])
// For Each
for (number in numbers) {
println(number)
}
// 전통적이 For문
for ((index, number) in numbers.withIndex()) {
println("${index}, ${number}")
}Collection에서도 withIndex를 사용할 수 있다.
만약 가변 리스트를 만들고 싶다면?
val numbers = mutableListOf(100, 200)
numbers.add(300)자바의 ArrayList와 사용법이 동일하다.
+) tips
우선 불변 리스트를 만들고, 꼭 필요한 경우 가변 리스트로 바꾸자.
Set
<kotlin>
val numbers = setOf(100, 200)
// For Each
for (number in numbers) {
println(number)
}
// 전통적인 For문
for ((index, number) in numbers.withIndex()) {
println("${index}, ${number}")
}
가변 집합
val numbers = mutableSetOf(100, 200)
Map
<java>
// JDK 8까지
Map<Integer, String> map = new HashMap<>();
map.put(1, "MONDAY");
map.put(2, "TUESDAY");
// JDK 9부터
Map.of(1, "MONDAY", 2, "TUESDAY");
<kotlin>
val map = mutableMapOf<Int, String>()
map.put(1, "MONDAY")
map[1] = "MONDAY" // 위 코드와 같은 표현
mapOf(1 to "MONDAY", 2 to "TUESDAY")
<java>
for (int key : map.keySet()) {
System.out.println(key);
System.out.println(map.get(key));
}
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
<kotlin>
for (key in map.keys) {
println(key)
println(map[key])
}
for ((key, value) in map.entries) {
println(key)
println(value)
}
컬렉션의 null 가능성, Java와 함께 사용하기
컬렉션의 null 가능성
List<Int?> : 리스트에 null이 들어갈 수 있지만, 리스트는 절대 null이 아님.
List<int>? : 리스트에는 null이 들어갈 수 없지만, 리스트는 null일 수 있음.
List<Int?>? : 리스트에 null이 들어갈 수도 있고, 리스트가 null일 수도 있음.
-> ? 위치에 따라 null 가능성 의미가 달라지므로 차이를 잘 이해해야 한다.
Java와 함께 사용하기
자바는 읽기 전용 컬렉션과 변경 가능 컬렉션을 구분하지 않는다.
ex1) 자바에서 코틀린의 불변리스트를 사용한다면?
1. 자바에서는 불변인지 모르기 때문에 element를 추가할 수 있다.
2. 이를 리턴받은 코틀린은 불변리스트지만 element가 추가된 리스트를 받을 수 있다.
자바는 nullable 타입과 non-nullable 타입을 구분하지 않는다.
ex2) 자바에서 코틀린의 non-nullable 리스트를 사용한다면?
1. 자바에서는 non-nullable인지 모르기 대문에 null을 추가할 수 있다.
2. 이를 리턴받은 코틀린은 non-nullable 리스트지만 null이 추가된 리스트를 받을 수 있다.
-> 코틀린 쪽의 컬렉션이 자바에서 호출되면, 컬렉션 내용이 변할 수 있음을 감안해야 한다.
반대로 코틀린에서 자바 컬렉션을 가져다 사용할 때 플랫폼 타입을 신경써야 한다.
ex3) 코틀린에서 자바의 List<Integer>를 사용한다면?
1. 코틀린은 List<Int?>, List<Int>?, List<Int?>? 중 어떤 리스트인지 알 수 없다.
자바 코드를 보며 맥락을 확인하고, 자바 코드를 가져오는 지점을 wrapping한다.
코틀린에서 다양한 함수를 다루는 방법
확장함수
코틀린은 자바와 100% 호환하는 것을 목표로 하고 있다.
그렇다면 이런 고민이 생긴다.
기존 자바 코드 위에 자연스럽게 코틀린 코드를 추가할 수는 없을까?
ex) 자바로 만들어진 라이브러리를 유지보수, 확장할 때 코틀린 코드를 덧붙이고 싶다면?
이러한 니즈로 만들어진 확장함수의 컨셉은 어떤 클래스 안에 있는 메서드처럼 호출할 수 있지만, 함수는 밖에 만들 수 있게 하는 것이다.
바로 예시를 보자.
fun String.lastChar(): Char {
return this[this.length - 1]
}코틀린 함수인데 조금 독특한 형태를 띄고 있다.
바로 함수 이름 부분에 "String"이 포함되어 있다.
해당 함수는 String 클래스를 확장하는 함수이다. 확장함수는 자바의 String 클래스가 아닌 어디서든 정의할 수 있다.
확장함수의 구성은 다음과 같다.
fun 확장하려는클래스.함수이름(파라미터): 리턴타입 {
// this를 이용해 실제 클래스 안의 값에 접근
}여기서 this를 "수신객체"라고 하며, 확장하려는클래스를 "수신객체 타입"이라 한다.
이로써 코틀린에서 확장함수를 원래 String에 있는 멤버함수처럼 사용할 수 있다.
fun main() {
val str: String = "ABC"
println(str.lastChar())
}
Q: 확장함수가 public이고, 확장함수에서 수신객체클래스의 private 함수를 가져오면 캡슐화가 깨지는 것 아닐까?
A: 그렇다. 그래서 확장함수는 수신객체클래스에 있는 private 또는 protected 멤버를 가져올 수 없다.
Q: 멤버함수와 확장함수의 시그니처가 같다면?
<java>
public class Person {
private final String firstName;
private final String lastName;
private int age;
public Person(String firstName, String lastName, int age) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age;
}
public String getFirstName() {
return firstName;
}
public int getAge() {
return age;
}
// 여기!!
public int nextYearAge() {
System.out.println("멤버 함수");
return this.age + 1;
}
}nextYearAge()에 주목하자.
<kotlin>
// 동일한 시그니처의 확장함수
fun Person.nextYearAge(): Int {
println("확장 함수")
return this.age + 1
}
fun main() {
val person = Person("A", "B", 100)
person.nextYearAge() // 결과는?
}
// 결과
멤버 함수결과는 멤버함수가 우선적으로 호출된다.
만약 확장함수를 만들었지만, 다른 기능의 똑같은 멤버함수가 수신객체클래스에 생기면? -> 오류가 발생할 수 있다.
따라서 이런 부분에 주의해서 확장함수를 사용하자.
Q: 확장함수가 오버라이드 된다면?
open class Train(
val name: String = "새마을기차",
val price: Int = 5_000,
)
fun Train.isExpensive(): Boolean {
println("Train의 확장함수")
return this.price >= 10000
}
class Srt : Train("SRT, 40_000")
fun Srt.isExpensive(): Boolean {
println("Srt의 확장함수")
return this.price >= 10000
}Srt가 Train을 상속받는 구조이다.
결과는 다음과 같다.
fun main() {
val train: Train = Train()
train.isExpensive() // Train의 확장함수
val srt1: Train = Srt()
srt1.isExpensive() // Train의 확장함수
val srt2: Srt = Srt()
srt2.isExpensive() // Srt의 확장함수
}정리하면, 해당 변수의 현재 타입, 즉, 정적인 타입에 의해 어떤 확장함수가 호출될지 결정된다.
Q: 자바에서 코틀린의 확장함수를 가져다 사용할 수 있나?
A: 그렇다.
public static void main(String[] args) {
System.out.println(Lec16Kt.lastChar("ABC"));
}이렇게 정적 메서드를 부르는 것처럼 사용 가능하다.
-> Lec16.kt가 처음에 만들었던 lastChar() 확장함수가 있는 파일이고, 자바에서 Lec16Kt로 해당 함수를 호출할 수 있다.
+) 추가로 확장함수라는 개념은 확장프로퍼티와도 연결된다.
fun String.lastChar(): Char {
return this[this.length - 1]
}
val String.lastChar: Char
get() = this[this.length - 1]확장 프로퍼티의 원리는 확장함수 + custom getter와 동일하다.
infix 함수
중위(infix)함수는 함수를 호출하는 새로운 방법이다.
변수.함수이름(argument) 대신 변수 함수이름 argument 구조를 사용한다.
예를 들어, 코틀린 반복문에서 downTo, step도 중위함수이다.
for (i in 3 downTo 1) {
println(i)
}
for (i in 1..5 step 2) {
println(i)
}
중위함수를 직접 만들어보자.
fun Int.add(other: Int): Int {
return this + other
}
infix fun Int.add2(other: Int): Int {
return this + other
}둘은 같은 기능을 함수지만, 아래 함수는 infix 키워드를 붙여주었다.
사용은 다음과 같이 한다.
3.add(4)
3.add2(4)
3 add2 4중위함수는 일반함수, 중위함수 형식 모두 사용할 수 있다.
inline 함수
inline 함수는 함수가 호출되는 대신, 함수를 호출한 지점에서 함수 본문을 그대로 복사 붙여넣기 하고 싶은 경우 사용한다.
예시를 보자.
<kotlin>
fun main() {
3.add3(4)
}
inline fun Int.add3(other: Int): Int {
return this + other
}
<java decompile>
byte $this$add3$iv = 3;
int other$iv = 4;
int $i$f$add3 = false;
int var10000 = $this$add3$iv + other$iv;이처럼 자바 코드에서 add3라는 함수를 호출하는 것이 아닌 add3 함수 본문을 그대로 출력한다.
이렇게 inline 함수를 사용하면 함수를 파라미터로 전달할 때 오버헤드를 줄일 수 있다.
-> 코틀린 라이브러리는 최적화를 위해 적절하게 inline 함수 처리가 되어 있다.
하지만, inline 함수의 사용은 성능 측정과 함께 신중하게 사용되어야 한다.
실제로 인텔리제이에서도 inline 함수를 사용하면, "인라인으로 인한 예상 성능 영향은 미미하다" 는 경고를 내려준다.
지역함수
지역함수는 함수 안에 함수를 선언하는 방법이다.
예시를 보자.
fun createPerson(firstName: String, lastName: String): Person {
if (firstName.isEmpty()) {
throw IllegalArgumentException("firstName은 비어있을 수 없습니다! 현재 값 : $firstName")
}
if (lastName.isEmpty()) {
throw IllegalArgumentException("lastName은 비어있을 수 없습니다! 현재 값 : $lastName")
}
return Person(firstName, lastName, 1)
}코드를 보면 isEmpty로 validation하는 부분이 중복이다.
지역함수를 써서 리팩토링해보자.
fun createPerson(firstName: String, lastName: String): Person {
fun validateName(name: String, fieldName: String) {
if (name.isEmpty()) {
throw IllegalArgumentException("${fieldName}은 비어있을 수 없습니다! 현재 값 : $name")
}
}
validateName(firstName, "firstName")
validateName(lastName, "lastName")
return Person(firstName, lastName, 1)
}이렇게 특정 부분을 함수로 추출하면 좋을 것 같은데, 이 함수를 지금 함수 내에서만 사용하고 싶을 때 지역함수를 사용할 수 있다.
물론 depth가 깊어지기도 하고, 코드가 그렇게 깔끔하지는 않다.
사실 이름을 validate하는 부분도 Person을 생성하는 코드에서 검증해주는 것이 좋을 수도 있다.
코틀린에서 람다를 다루는 방법
Java에서 람다를 다루기 위한 노력
코틀린에서 람다를 알아보기 전에 자바에서 람다가 어떤 배경에서 생겨났는지, JDK 8을 이전과 이후를 기준으로 알아보자.
먼저 JDK 8 이전 자바의 상황을 알아보자.
람다를 공부하기 위한 클래스 Fruit을 정의한다.
public class Fruit {
private final String name;
private final int price;
public Fruit(String name, int price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public int getPrice() {
return price;
}
public boolean isApple() {
return this.name.equals("사과");
}
}
나는 과일가게를 운영하는 입장이다.
public static void main(String[] args) {
List<Fruit> fruits = Arrays.asList(
new Fruit("사과", 1_000),
new Fruit("사과", 1_200),
new Fruit("사과", 1_200),
new Fruit("사과", 1_500),
new Fruit("바나나", 3_000),
new Fruit("바나나", 3_200),
new Fruit("바나나", 2_500),
new Fruit("수박", 10_000)
);
}
고객: 사장님 사과만 보여주세요!
private List<Fruit> findApples(List<Fruit> fruits) {
List<Fruit> apples = new ArrayList<>();
for (Fruit fruit : fruits) {
if (fruit.getName().equals("사과")) {
apples.add(fruit);
}
}
return apples;
}
고객: 사장님 바나나만 보여주세요!
private List<Fruit> findBananas(List<Fruit> fruits) {
List<Fruit> bananas = new ArrayList<>();
for (Fruit fruit : fruits) {
if (fruit.getName().equals("바나나")) {
bananas.add(fruit);
}
}
return bananas;
}
나: 중복이 존재하니 코드를 수정해야겠군.
private List<Fruit> findFruitsWithName(List<Fruit> fruits, String name) {
List<Fruit> results = new ArrayList<>();
for (Fruit fruit : fruits) {
if (fruit.getName().equals(name)) {
results.add(fruit);
}
}
return results;
}뿌듯.
...
고객: 사과랑 바나나 같이 보여주세요.
고객: 사과인데 가격이 1200원을 넘지 않는 것만 보여주세요.
고객: 10000원 이하의 수박과 1000원 이상의 바나나 보여주세요.
나: ... 파라미터를 늘리는 것으로는 안되겠다.
인터페이스와 익명 클래스를 사용하자.
<인터페이스>
public interface FruitFilter {
boolean isSelected(Fruit fruit);
}
<함수>
private List<Fruit> filterFruits(List<Fruit> fruits, FruitFilter fruitFilter) {
List<Fruit> results = new ArrayList<>();
for (Fruit fruit : fruits) {
if (fruitFilter.isSelected(fruit)) {
results.add(fruit);
}
}
return results;
}
<익명클래스를 통함 함수 호출>
filterFruits2(fruits, new FruitFilter() {
@Override
public boolean isSelected(Fruit fruit) {
return Arrays.asList("사과", "바나나").contains(fruit.getName()) &&
fruit.getPrice() > 5_000;
}
});나: 좋다. 고객의 다양한 요구사항에 대한 무수한 메서드 생성을 막았다!
하지만, 익명 클래스를 사용하는 것은 복잡하다.
또한 다양한 필터가 필요할 수 있다.
ex) 특정 과일만을 필터링하는 것 뿐만 아닌, 과일 간 무게 비교, N개의 과일을 한 번에 비교 등
-> JDK 8부터 람다 등장!
(람다는 익명 함수를 지칭하는 용어이고, 기존 익명 함수와 다른 표현 방식이다)
JDK 8은 FruitFilter와 같은 Predicate, Consumer 등을 많이 만들어 두었다.
<함수 호출>
filterFruits(fruits, fruit -> fruit.getName().equals("사과"));변수 -> 변수를 이용한 함수
(변수1, 변수2) -> 변수1과 변수2를 이용한 함수
<함수>
private List<Fruit> filterFruits(List<Fruit> fruits, Predicate<Fruit> fruitFilter) {
List<Fruit> results = new ArrayList<>();
for (Fruit fruit : fruits) {
if (fruitFilter.test(fruit)) {
results.add(fruit);
}
}
return results;
}Predicate은 제네릭 타입인 한 개의 매개변수를 전달받아 특정 작업을 수행 후 Boolean 타입의 값을 반환하는 작업을 수행할 때, 사용됩니다.
fruit이 특정 필터를 만족하는지에 대한 검증은 test() 메서드를 통해 수행한다.
여기서 간결한 스트림이 등장했다.
private List<Fruit> filterFruits(List<Fruit> fruits, Predicate<Fruit> fruitFilter) {
return fruits.stream()
.filter(fruitFilter)
.collect(Collectors.toList());
}깔.끔.
+) 람다는 메서드 레퍼런스를 사용할 수도 있다.
filterFruits(fruits, Fruit::isApple);
이처럼 람다는 "메서드 자체를 직접 넘겨주는 것처럼" 쓸 수 있다.
어디까지나 "넘겨주는 것처럼"이다. 자바에서 함수는 본질적으로 변수에 할당되거나 파라미터로 전달할 수 없다.
코틀린에서의 람다
지금까지 자바에서 람다와 스트림이 어떻게 생겨났는지를 알아보았다.
이제부터는 코틀린에서 람다와 스트림을 어떻게 적용시키는지를 알아보자.
코틀린은 자바와 근본적으로 다른 한 가지가 있다.
코틀린에서는 함수가 그 자체로 값이 될 수 있다. 변수에 할당할 수도, 파라미터로 넘길 수도 있다.
한 번 람다(익명함수)를 변수에 넣어보자.
// 람다를 만드는 방법 1
val isApple: (Fruit) -> Boolean = fun(fruit: Fruit): Boolean {
return fruit.name == "사과"
}
// 람다를 만드는 방법 2
val isApple2: (Fruit) -> Boolean = {fruit: Fruit -> fruit.name == "사과"}보통 두 번째 방법이 간결하게 더 많이 사용한다.
람다를 호출해보자.
// 람다를 직접 호출하는 방법 1
isApple(Fruit("사과", 1000))
// 람다를 직접 호출하는 방법 2
isApple.invoke(Fruit("사과", 1000))
여기서 주목할 점은 람다의 타입이 (Fruit) -> Boolean
즉, (파라미터 타입...) -> 반환 타입 이라는 것이다.
이를 기억하면서 자바의 filterFruit 함수를 코틀린으로 옮겨보자.
filterFruits(fruits, isApple)
private fun filterFruits(fruits: List<Fruit>, filter: (Fruit) -> Boolean): List<Fruit> {
val results = mutableListOf<Fruit>()
for (fruit in fruits) {
if (filter(fruit)) {
results.add(fruit)
}
}
return results
}코틀린에서는 Predicate같은 인터페이스 없이 함수 자체를 파라미터로 넘길 수 있다.
-> 람다를 사용하기 더 편리하다.
+) 추가로 함수를 호출할 때 마지막 파라미터가 함수(람다)인 경우, 소괄호 밖에 람다를 사용가능하다.
// 소괄호 안에 중괄호가 있어 어색하다
filterFruits(fruits, {fruit: Fruit -> fruit.name == "사과"})
// 소괄호 밖에 람다 사용
filterFruits(fruits) { fruit: Fruit -> fruit.name == "사과" }
그리고 람다에서 파라미터가 한 개인 경우 it로 직접 참조할 수 있다.
// fruit -> ... 형식
filterFruits(fruits) { fruit: Fruit -> fruit.name == "사과" }
// it 형식
filterFruits(fruits) {it.name == "사과"}+) 다만 함수를 호출하는 쪽에서는 it가 무엇인지 명확하지 않기 때문에, fruit -> ... 을 사용하는 것을 권장하기도 한다.
Closure
여기 람다를 사용하는 자바 코드가 있다.
String targetFruitName = "바나나";
targetFruitName = "수박";
filterFruits(fruits, (fruit) -> targetFruitName.equals(fruit.getName()));
이 경우 다음과 같은 컴파일 오류가 발생한다.
Variable used in lambda expression should be final or effectively final
즉, 람다는 final 변수, 혹은 실질적인 final 변수만 사용가능하다는 것이다.
targetFruitName은 "바나나"에서 "수박"으로 변경됐기 때문에 실질적인 final이 아니라 람다에서 사용할 수 없는 것이다.
-> 즉, 자바에서 람다를 쓸 때 사용할 수 있는 변수에 제약이 있다.
코틀린은 어떨까?
var targetFruitName = "바나나"
targetFruitName = "수박"
filterFruits(fruits) {it.name == targetFruitName}코틀린에서는 아무런 문제 없이 동작한다.
코틀린에서는 람다가 시작하는 지점에 참조하고 있는 변수들을 모두 포획하여 그 정보를 가지고 있다.
이렇게 해야만 람다를 진정한 변수, 파라미터로서 간주할 수 있다.
-> 이 데이터 구조를 Closure라고 부른다.
Q: 왜 자바에서는 람다에서 외부 변수를 사용하는데 제약을 두었을까?
A: 외부 지역변수를 제어하는 스레드와 람다식을 수행하는 스레드가 다를 수 있기 때문이다.
자바에서는 이러한 멀티 스레드 환경에서의 애매함을 아얘 제거하기 위해 이런 선택을 한 것이다.
참고: https://www.baeldung.com/java-lambda-effectively-final-local-variables
반면 코틀린은 람다를 실질적인 파라미터로 사용하기 위해 외부 지역변수를 직접 람다에서 가져올 수 있는데,
이 이유는 자바는 람다를 익명클래스로 변경시킬 때 primitive 지역변수를 활용한다면, 코틀린은 람다를 익명클래스로 변경시킬 때, reference 지역변수를 활용하게 된다.
즉, 코틀린은 외부 지역변수를 한번 래핑함으로써, 해당 변수 값을 변경할 수 있도록 했다.
-> 따라서, 한 변수를 여러 스레드에서 사용하는 경우 동시성 문제를 고려할 필요가 있다.
다시 try with resources
이전에 작성한 글에서 코틀린에서 try with resources를 다뤘는데,
이제 람다를 배웠으니 조금 더 자세하게 분석을 해보자.
fun readFile(path: String) {
BufferedReader(FileReader(path)).use { reader ->
println(reader.readLine())
}
}코틀린에서는 use를 통해 try with resources를 사용한다.
use를 타고 들어가보자.
<Closeable.kt>
@InlineOnly
@RequireKotlin("1.2", versionKind = RequireKotlinVersionKind.COMPILER_VERSION, message = "Requires newer compiler version to be inlined correctly.")
public inline fun <T : Closeable?, R> T.use(block: (T) -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
var exception: Throwable? = null
try {
return block(this)
} catch (e: Throwable) {
exception = e
throw e
} finally {
when {
apiVersionIsAtLeast(1, 1, 0) -> this.closeFinally(exception)
this == null -> {}
exception == null -> close()
else ->
try {
close()
} catch (closeException: Throwable) {
// cause.addSuppressed(closeException) // ignored here
}
}
}
}코드를 보면 use가 자바의 Closeable 인터페이스를 상속받는 제네릭 타입 클래스(T)의 확장함수라는 것을 알 수 있다.
파라미터로는 (T) -> R이라는 람다를 받는데, 실제로 use를 사용하는 코드를 보면 람다를 인자로 주고 있다.
-> 아는게 생기니 보이는게 많아진다.
코틀린에서 컬렉션을 함수형으로 다루는 방법
필터와 맵
앞으로 예제에서 사용할 클래스와 리스트
data class Fruit(
val id: Long,
val name: String,
val factoryPrice: Long,
val currentPrice: Long,
)
fun main() {
val fruits: List<Fruit> = listOf(
Fruit(1L, "사과", 1_000, 2_000),
Fruit(2L, "바나나", 2_000, 3_000),
Fruit(3L, "수박", 3_000, 4_000),
)
}
Q: 사과만 주세요.
val apples = fruits.filter {fruit -> fruit.name == "사과" }
filter는 람다를 매개변수로 갖는 함수로, 매개변수가 람다 하나이기 때문에 밖으로 뺄 수 있는 것이다.
+) 필터에서 인덱스가 필요하다면?
val apples2 = fruits.filterIndexed { idx, fruit ->
println(idx)
fruit.name == "사과"
}
Q: 사과의 가격들을 알려주세요.
val applePrices = fruits.filter { fruit -> fruit.name == "사과" }
.map { fruit -> fruit.currentPrice }
+) 맵에서 인덱스가 필요하다면?
val applePrices2 = fruits.filter { fruit -> fruit.name == "사과" }
.mapIndexed { idx, fruit ->
println(idx)
fruit.currentPrice
}
+) 매핑 결과가 null이 아닌 것만 가져오고 싶다면?
val values = fruits.filter { fruit -> fruit.name == "사과" }
.mapNotNull { fruit -> fruit.currentPrice }
다양한 컬렉션 처리 기능
// 조건을 모두 만족하면 true, 그렇지 않으면 false
val isAllApple = fruits.all { fruit -> fruit.name == "사과" }
// 조건을 모두 불만족하면 true, 그렇지 않으면 false
val isNoApple = fruits.none { fruit -> fruit.name == "사과" }
// 조건을 하나라도 만족하면 true, 그렇지 않으면 false
val isAnyApple = fruits.any { fruit -> fruit.factoryPrice >= 10_000 }
// 개수를 센다
val fruitCount = fruits.count()
// (오름차순) 정렬을 한다
val fruitSort = fruits.sortedBy { fruit -> fruit.currentPrice}
// (내림차순) 정렬을 한다
val fruitSortDescend = fruits.sortedByDescending { fruit -> fruit.currentPrice}
// 변형된 값을 기준으로 중복을 제거한다
val distinctFruitNames = fruits.distinctBy { fruit -> fruit.name }
.map { fruit -> fruit.name }
// 첫번째 값을 가져온다 (무조건 null이 아니어야 함)
fruits.first()
// 첫번째 값 또는 null(빈리스트)을 가져온다
fruits.firstOrNull()
// 마지막 값을 가져온다 (무조건 null이 아니어야 함)
fruits.last()
// 마지막 값 또는 null(빈리스트)을 가져온다
fruits.lastOrNull()
List를 Map으로
Q: Map<과일이름, List<과일>>이 필요해요.
val map: Map<String, List<Fruit>> = fruits.groupBy { fruit -> fruit.name }
Q: Map<id, 과일>이 필요해요.
val map2: Map<Long, Fruit> = fruits.associateBy { fruit -> fruit.id }
Q: Map<과일이름, List<출고가>>가 필요해요.
val map3: Map<String, List<Long>> = fruits
.groupBy ({ fruit -> fruit.name }, {fruit -> fruit.factoryPrice})+) groupBy의 인자가 두 개이기 때문에, 두 람다를 모두 소괄호 바깥으로 뺄 수 없다. (마지막 람다는 뺄 수 있음)
Q: Map<id, 출고가>가 필요해요.
val map4: Map<Long, Long> = fruits
.associateBy({ fruit -> fruit.id }, { fruit -> fruit.factoryPrice })
Map에 대해서도 앞선 기능들을 대부분 사용할 수 있다.
val map: Map<String, List<Fruit>> = fruits.groupBy { fruit -> fruit.name }
.filter { (key, value) -> key == "사과" }
중첩된 컬렉션 처리
val fruitsIntList: List<List<Fruit>> = listOf(
listOf(
Fruit(1L, "사과", 1_000, 2_000),
Fruit(2L, "바나나", 2_000, 3_000),
Fruit(3L, "수박", 3_000, 4_000),
),
listOf(
Fruit(4L, "사과", 1_000, 2_000),
Fruit(5L, "바나나", 2_000, 3_000),
Fruit(6L, "수박", 3_000, 4_000),
),
listOf(
Fruit(7L, "사과", 1_000, 2_000),
Fruit(8L, "바나나", 2_000, 3_000),
Fruit(9L, "수박", 3_000, 4_000),
)
)
Q: 출고가와 현재가가 동일한 과일을 골라주세요.
val samePriceFruits = fruitsIntList.flatMap { list ->
list.filter { fruit -> fruit.factoryPrice == fruit.currentPrice }
}
List의 확장함수를 사용하여 리팩토링할 수 있다.
data class Fruit(
val id: Long,
val name: String,
val factoryPrice: Long,
val currentPrice: Long,
) {
// custom getter
val isSamePrice: Boolean
get() = factoryPrice == currentPrice
}// 확장함수
val List<Fruit>.samePriceFilter: List<Fruit>
get() = this.filter(Fruit::isSamePrice)// 리팩토링
val samePriceFruits2 = fruitsIntList.flatMap { list -> list.samePriceFilter }
Q: List<List<Fruit>>을 그냥 List<Fruit>으로 바꿔주세요.
fruitsIntList.flatten()+) flatten은 중복 리스트를 1 depth, flat해주는 메서드이고, flatMap은 map + flatten이다.
'kotlin' 카테고리의 다른 글
| [Kotlin] JPA 플러그인 정리 (0) | 2024.07.19 |
|---|---|
| [Kotlin] 추가적으로 알아두어야 할 코틀린 특성 (0) | 2023.06.20 |
| [Kotlin] 코틀린에서의 OOP (0) | 2023.05.07 |
| [Kotlin] 코틀린에서 코드를 제어하는 방법 (4) | 2023.05.07 |
| [Kotlin] 코틀린에서 변수와 타입, 연산자를 다루는 방법 (0) | 2023.05.07 |