![[Spring] AWS S3 파일 압축해서 다운로드 - 여러가지 방법 비교분석](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FvJYVw%2FbtrITodm1gy%2FhEHB7KPBr3QPkJsuC8lq00%2Fimg.png)
이전에 Spring을 통해 S3에서 파일을 다운로드하는 API를 개발한 적이 있었다.
2021.08.05 - [java/spring] - [Spring] AWS S3에서 Spring Boot로 파일 다운로드
[Spring] AWS S3에서 Spring Boot로 파일 다운로드
프로젝트 중 AWS S3에서 특정 버킷의 파일을 다운로드 받아야 하는 상황이 생겨 기록을 한다. build.gradle - 의존성 추가 dependencies { ... implementation 'org.springframework.cloud:spring-cloud-starter-a..
gksdudrb922.tistory.com
그러나 이 방법은 단일 객체 하나를 다운받을 수 있었는데, 이번에는 디렉토리를 포함해서 대용량 파일을 다운받아야 하는 상황이 생겼다.
고민하던 중, S3에 있는 대용량 파일들을 압축해서 사용자에게 zip파일을 제공하면 편리하지 않겠냐는 회사의 제안을 받아 이를 API로 구현하고자 한다.
압축 다운로드 API 자체를 개발하는 것은 어렵지 않았지만, 5GB 정도 되는 대용량 파일이기 때문에 최적화 역시 중요했다.
따라서 여러 가지 다운로드 방법을 테스트해봤고 이를 비교하는 글을 작성하려 한다.
다운로드 방법은 총 3가지로 구현했다.
1. TransferManager 사용 + resource
2. TransferManager 사용 + response
3. 반복문 + 디렉토리 전체 조회
지금부터 하나씩 살펴보겠다.
기본 세팅
먼저 S3 버킷에 대한 퍼블릭 엑세스 설정이 필요하다. 해당 글을 참고하자.
2022.07.25 - [aws] - [AWS] S3 버킷 퍼블릭 엑세스 설정
[AWS] S3 버킷 퍼블릭 엑세스 설정
AWS S3 버킷을 퍼블릭하게 열어두고 사용할 때가 많다. 이번에는 S3 퍼블릭 엑세스에 대한 기본 세팅을 설명한다. 퍼블릭 엑세스 차단 기본적으로 아무 설정 없이 버킷을 생성하면 모든 퍼블릭 엑
gksdudrb922.tistory.com
또한, Spring Boot에서 S3 설정 및 접근에 대한 인증 키를 입력해야 한다. 해당 글을 참고하자.
2022.07.25 - [java/spring] - [Spring] AWS S3 접근
[Spring] AWS S3 접근
라이브러리 추가 implementation 'org.springframework.cloud:spring-cloud-starter-aws:2.2.6.RELEASE' 인증 키 추가 본인 IAM 인증 키를 추가하면 된다. cloud: aws: credentials: instance-profile: false acce..
gksdudrb922.tistory.com
다음 라이브러리를 추가한다.
implementation 'org.springframework.cloud:spring-cloud-starter-aws:2.2.6.RELEASE' // S3 접근 implementation 'net.lingala.zip4j:zip4j:2.6.1' // 압축 다운로드 implementation 'org.apache.commons:commons-text:1.9' // 랜덤 문자열 생성
S3Config에 TransferManager를 추가한다.
TransferManager는 AWS가 제공하는 SDK로, S3 파일 다운로드, 업로드를 용이하게 해주는 클래스이다.
@Configuration public class S3Config { @Value("${cloud.aws.credentials.access-key}") public String accessKey; @Value("${cloud.aws.credentials.secret-key}") public String secretKey; @Value("${cloud.aws.region.static}") public String region; @Bean @Primary public BasicAWSCredentials awsCredentialsProvider(){ BasicAWSCredentials basicAWSCredentials = new BasicAWSCredentials(accessKey, secretKey); return basicAWSCredentials; } @Bean public AmazonS3 amazonS3() { AmazonS3 s3Builder = AmazonS3ClientBuilder.standard() .withRegion(region) .withCredentials(new AWSStaticCredentialsProvider(awsCredentialsProvider())) .build(); return s3Builder; } // 추가 @Bean public TransferManager transferManager() { TransferManager transferManager = TransferManagerBuilder.standard() .withS3Client(amazonS3()) .build(); return transferManager; } }
application.yml(.properties) 파일에 다운로드할 파일이 속한 버킷 이름을 설정하자.
aws: s3: bucket: danuri
당연히 S3에 해당 이름의 버킷이 존재해야 한다.
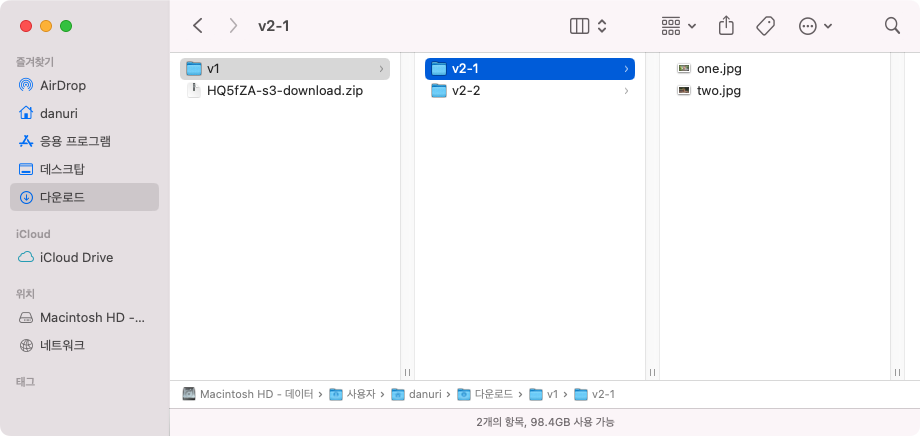
나는 다음과 같은 구조로 버킷을 만들었다.
버킷: danuri
- 디렉토리: v1/
- 디렉토리: v2-1/
- 파일: one.jpg
- 파일: two.jpg
- 디렉토리: v2-2/
- 파일: three.jpg
- 파일: four.jpg
1. TransferManager 사용 + resource
첫 번째 방법은 TransferManager를 사용한다. +resource는 Resource 클래스를 리턴함으로써 파일을 다운로드 한다는 것인데, 자세한 것은 코드를 통해 알아보자.
컨트롤러
S3 다운로드에 쓰일 컨트롤러이다.
@Controller @RequiredArgsConstructor @RequestMapping("/s3") public class S3Controller { private final S3Service s3Service; @GetMapping(value = "/download/zip1/**", produces = MediaType.APPLICATION_OCTET_STREAM_VALUE) public ResponseEntity<Resource> downloadZip1(HttpServletRequest request) throws IOException, InterruptedException { // (1) String prefix = getPrefix(request.getRequestURI(), "/s3/download/zip1/"); // (2) Resource resource = s3Service.downloadZip1(prefix); // (3) HttpHeaders headers = new HttpHeaders(); headers.add("Content-Disposition", "attachment; filename=" + new String(resource.getFilename().getBytes("UTF-8"), "ISO-8859-1")); return new ResponseEntity<>(resource, headers, HttpStatus.OK); } private String getPrefix(String uri, String regex) { String[] split = uri.split(regex); return split.length < 2 ? "" : split[1]; } }
우선 파일 다운로드를 위해서 produces = MediaType.APPLICATION_OCTET_STREAM_VALUE 를 추가하자.
(1)
- URL 구조
/download/zip1/{버킷 내에서 다운로드 할 디렉토리}
{버킷 내에서 다운로드 할 디렉토리} 는 @PathVariable로 가져오지 않는데, 이유는 /v1/v2/... 처럼 path 형태로 변수를 저장하기 위해서다.
이를 getPrefix라는 함수를 통해 URI를 파싱해서 디렉토리 경로(prefix)를 가져오도록 설정했으며, 이를 통해
/download/zip1/v1
/download/zip1/v1/v2
등 다양한 디렉토리 구조 형태를 가져올 수 있다.
(2)
서비스 계층에서 다운로드를 진행하고, 사용자가 다운로드 받을 수 있는 Resource 클래스를 리턴한다.
(3)
"Content-Disposition" 헤더에 파일다운로드를 위한 'attachment'를 추가하고, resource와 함께 리턴한다.
+) 참고로 헤더에 추가하는 설정은 크롬 브라우저 인코딩 방식이다. IE 등 다른 브라우저 방식의 경우 참고자료 3번째 자료를 참고하자.
서비스
@Service @Transactional(readOnly = true) @RequiredArgsConstructor @Slf4j public class S3Service { private final AmazonS3 amazonS3; private final TransferManager transferManager; @Value("${aws.s3.bucket}") private String bucket; public Resource downloadZip1(String prefix) throws IOException, InterruptedException { // (1) // 서버 로컬에 생성되는 디렉토리, 해당 디렉토리에 파일이 다운로드된다 File localDirectory = new File(RandomStringUtils.randomAlphanumeric(6) + "-s3-download"); // 서버 로컬에 생성되는 zip 파일 ZipFile zipFile = new ZipFile(RandomStringUtils.randomAlphanumeric(6) + "-s3-download.zip"); try { // (2) // TransferManager -> localDirectory에 파일 다운로드 MultipleFileDownload downloadDirectory = transferManager.downloadDirectory(bucket, prefix, localDirectory); // (3) // 다운로드 상태 확인 log.info("[" + prefix + "] download progressing... start"); DecimalFormat decimalFormat = new DecimalFormat("##0.00"); while (!downloadDirectory.isDone()) { Thread.sleep(1000); TransferProgress progress = downloadDirectory.getProgress(); double percentTransferred = progress.getPercentTransferred(); log.info("[" + prefix + "] " + decimalFormat.format(percentTransferred) + "% download progressing..."); } log.info("[" + prefix + "] download directory from S3 success!"); // (4) // 로컬 디렉토리 -> 로컬 zip 파일에 압축 log.info("compressing to zip file..."); zipFile.addFolder(new File(localDirectory.getName() + "/" + prefix)); } finally { // (5) // 로컬 디렉토리 삭제 FileUtil.remove(localDirectory); } // (6) // 파일 Resource 리턴 return new FileSystemResource(zipFile.getFile().getName()); } }
코드가 길어보이지만 주석으로 단 번호와 설명을 함께 보면 구조 자체는 크게 어렵지 않다.
코드를 부분적으로 분석해보자.
(1)
// (1) // 서버 로컬에 생성되는 디렉토리, 해당 디렉토리에 파일이 다운로드된다 File localDirectory = new File(RandomStringUtils.randomAlphanumeric(6) + "-s3-download"); // 서버 로컬에 생성되는 zip 파일 ZipFile zipFile = new ZipFile(RandomStringUtils.randomAlphanumeric(6) + "-s3-download.zip");
TransferManager를 사용하면 우선 S3 파일을 로컬에 다운로드 받아야 한다.
즉, S3 -> 로컬 -> 사용자 순으로 다운로드가 진행된다.
해당 부분은 로컬에 파일 다운로드를 위한 디렉토리 및 해당 디렉토리를 압축하기 위한 zip 파일의 이름을 설정하는 코드다.
이름은
디렉토리: {RandomString(6)}-s3-download
zip 파일: {RandomString(6)}-s3-download.zip
으로 설정했다. RandomString을 통해 동일한 이름을 사용하지 않은 이유는 여러 사용자가 동시에 다운로드 하는 경우 디렉토리가 겹칠 수 있기 때문이다.
(2)
// (2) // TransferManager -> localDirectory에 파일 다운로드 MultipleFileDownload downloadDirectory = transferManager.downloadDirectory(bucket, prefix, localDirectory);
TransferManager를 통해 파일을 로컬 디렉토리에 다운로드한다.
TransferManager에 대한 더 자세한 설명은 아래 참고자료 첫 번째 링크를 참고하자.
(3)
// (3) // 다운로드 상태 확인 log.info("[" + prefix + "] download progressing... start"); DecimalFormat decimalFormat = new DecimalFormat("##0.00"); while (!downloadDirectory.isDone()) { Thread.sleep(1000); TransferProgress progress = downloadDirectory.getProgress(); double percentTransferred = progress.getPercentTransferred(); log.info("[" + prefix + "] " + decimalFormat.format(percentTransferred) + "% download progressing..."); } log.info("[" + prefix + "] download directory from S3 success!");
TransferManager은 멀티스레드를 사용하여 멀티파트 전송을 한다.
처리량이 빠르다 등의 좋은 장점이 많은데, 여기서 주의해야 할 점은 비동기 처리이기 때문에, transferManager.downloadDirectory() 메서드 호출 후 다운로드가 완료되지 않아도 다음 코드를 수행한다.
순서가 중요한 코드의 경우 이를 block하는 설정이 필요하다. 해당 API의 경우 다운로드 -> 압축의 순서가 있기 때문에 while(!downloadDirectory.isDone())을 통해 다운로드가 끝날 때까지 대기하도록 설정했다.
이왕 기다리는 김에 다운로드 진행 상황을 보면 좋겠다 생각했고, 위 코드를 돌리면 다음과 같은 로그가 찍힌다.
[v1] download progressing... start [v1] 0.35% download progressing... [v1] 0.70% download progressing... [v1] 1.06% download progressing... [v1] 1.44% download progressing... [v1] 1.80% download progressing... [v1] 2.15% download progressing... ... [v1] 100.00% download progressing... [v1] download directory from S3 success!
+) 물론 다운로드 파일의 용량이 작은 경우 100%가 바로 찍히거나, 로그가 안찍히기도 한다.
(4)
// (4) // 로컬 디렉토리 -> 로컬 zip 파일에 압축 log.info("compressing to zip file..."); zipFile.addFolder(new File(localDirectory.getName() + "/" + prefix));
다운로드를 위한 로컬 디렉토리를 zip 파일로 압축한다.
zip4J 라이브러리를 사용하면 이렇게 addFolder()를 통해 간편하게 디렉토리를 압축할 수 있다.
(5)
// (5) // 로컬 디렉토리 삭제 FileUtil.remove(localDirectory);
finally 문에 속하는 부분으로 다운로드가 성공하던, 중간에 오류가 생기던 로컬 용량을 아끼기 위해 로컬 디렉토리는 꼭 삭제해 줘야 한다.
FileUtil.remove()는 내가 편의를 위해 제작한 메서드로 다음과 같다.
디렉토리 삭제를 용이하게 하고자 했다.
@Slf4j public class FileUtil { public static void remove(File file) throws IOException { if (file.isDirectory()) { removeDirectory(file); } else { removeFile(file); } } public static void removeDirectory(File directory) throws IOException { File[] files = directory.listFiles(); for (File file : files) { remove(file); } removeFile(directory); } public static void removeFile(File file) throws IOException { if (file.delete()) { log.info("File [" + file.getName() + "] delete success"); return; } throw new FileNotFoundException("File [" + file.getName() + "] delete fail"); } }
(6)
// (6) // 파일 Resource 리턴 return new FileSystemResource(zipFile.getFile().getName());
파일을 사용자가 다운로드할 수 있는 형태로 리턴한다.
테스트
이제 크롬 브라우저를 열어서 실제로 파일을 다운로드 받아보자. 각자 버킷의 디렉토리 구조에 맞게 API를 호출하면 된다.
나의 경우 크롬 주소창에 이렇게 입력했다.
http://localhost:8080/s3/download/zip1/v1
정상적으로 다운로드가 되었다.
zip 파일은 설정한데로 랜덤스트링과 함께 이름이 지정되었고,
디렉토리 전체가 빠짐없이 잘 다운로드 된 것을 확인할 수 있다.
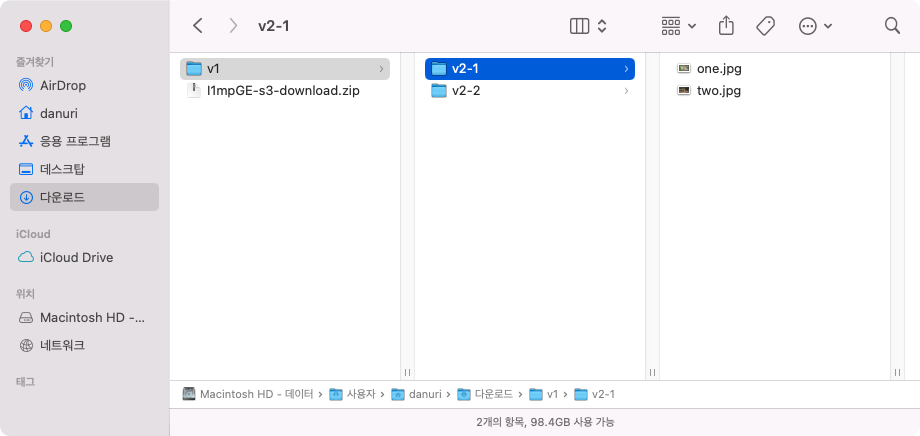
이제 정말 궁금했던 대용량 파일에 대해 테스트해봤다.
다운로드 시간은 당연히 사용자 로컬에 따라 달라지며, 나는 회사에서 지급받은 나름 최신 노트북(LG 그램..?)으로 테스트를 진행했다.
파일은 약 7GB였고, 시간은 다음과 같이 측정되었다.
총 23분 (로컬 다운로드 3분 + 압축 4분 + 사용자 다운로드 16분)
TransferManager의 성능 답게 로컬 다운로드 자체는 정말 빠른 시간에 진행됐다.
그러나, 사용자 다운로드 시간이 오래걸리는 것을 보면 Resource를 리턴하는 방법이 그렇게 좋지는 않다는 것을 느꼈다.
+) 여기서 사용자 다운로드 시간이라는 것은 실제 사용자 브라우저에서 다운로드가 진행되는 시간을 말하는 것이다. 쉽게 말해서, 사용자가 파일이 다운로드 되고 있구나 느낄 수 있는 시점이다.
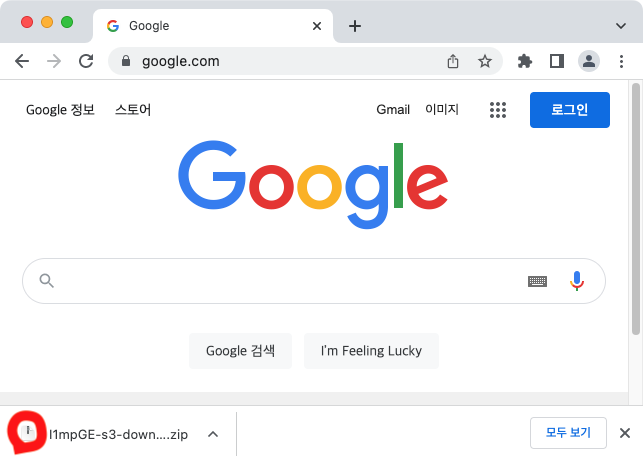
즉, 저기 빨강 동그라미에 다운로드 게이지(?)가 차는 시간이다.
2. TransferManager 사용 + response
1번 방법은 다운로드하는 시간이 오래걸린다. 따라서, 이런 생각이 들었다.
"파일을 압축을 다 한뒤, 다운받게 하지 말고, 압축을 하면서 동시에 다운로드할 수 있으면 좋지 않을까?"
바로 실행에 옮겼다.
컨트롤러
@GetMapping(value = "/download/zip2/**", produces = MediaType.APPLICATION_OCTET_STREAM_VALUE) public void downloadZip2(HttpServletRequest request, HttpServletResponse response) throws IOException, InterruptedException { response.setStatus(HttpServletResponse.SC_OK); response.addHeader("Content-Disposition", "attachment; filename=" + new String((RandomStringUtils.randomAlphanumeric(6) + "-s3-download.zip").getBytes("UTF-8"), "ISO-8859-1")); String prefix = getPrefix(request.getRequestURI(), "/s3/download/zip2/"); s3Service.downloadZip2(prefix, response); }
Resource를 리턴하는 1번 방식과 달리 아무것도 리턴하지 않는다.
대신에, response 자체에 파일을 실어 보낼 계획이다.
따라서, response header에 이전처럼 "Content-Disposition"을 추가하고 서비스 로직을 호출한다.
서비스
public void downloadZip2(String prefix, HttpServletResponse response) throws IOException, InterruptedException { // (1) // 서버 로컬에 생성되는 디렉토리, 해당 디렉토리에 파일이 다운로드된다 File localDirectory = new File(RandomStringUtils.randomAlphanumeric(6) + "-s3-download.zip"); try (ZipOutputStream zipOut = new ZipOutputStream(response.getOutputStream())) { // (2) // TransferManager -> localDirectory에 파일 다운로드 MultipleFileDownload downloadDirectory = transferManager.downloadDirectory(bucket, prefix, localDirectory); // (3) // 다운로드 상태 확인 log.info("[" + prefix + "] download progressing... start"); DecimalFormat decimalFormat = new DecimalFormat("##0.00"); while (!downloadDirectory.isDone()) { Thread.sleep(1000); TransferProgress progress = downloadDirectory.getProgress(); double percentTransferred = progress.getPercentTransferred(); log.info("[" + prefix + "] " + decimalFormat.format(percentTransferred) + "% download progressing..."); } log.info("[" + prefix + "] download directory from S3 success!"); // (4) // 로컬 디렉토리 -> 압축하면서 다운로드 log.info("compressing to zip file..."); addFolderToZip(zipOut, localDirectory); } finally { // (5) // 로컬 디렉토리 삭제 FileUtil.remove(localDirectory); } }
1번 방법과 거의 90% 똑같다.
달라진 점으로는
첫 번째로, (2)번 위에 try문에 ZipOutPutStream에 response.getOutPutStream을 주입했다는 점이다.
response.getOutPutStream에 파일을 write하는 순간 사용자가 해당 파일을 다운로드 할 수 있다고 보면 된다.
(크롬 다운로드 게이지 시작)
두 번째로, (4)번에서 addFolder가 아닌 파일을 압축하면서 다운로드 받을 수 있는 메서드를 추가했다.
ZipFile이 제공하는 addFolder를 사용하지 않기 때문에, 과감히 zip4J 라이브러리가 제공하는 기능은 사용하지 않았다.
addFolederToZip() 직접 제작한 메서드로 다음과 같다.
private void addFolderToZip(ZipOutputStream zipOut, File localDirectory) throws IOException { final int INPUT_STREAM_BUFFER_SIZE = 2048; Files.walkFileTree(Paths.get(localDirectory.getName()), new SimpleFileVisitor<>() { @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { if (attrs.isSymbolicLink()) { return FileVisitResult.CONTINUE; } try (FileInputStream fis = new FileInputStream(file.toFile())) { Path targetFile = Paths.get(localDirectory.getName()).relativize(file); ZipEntry zipEntry = new ZipEntry(targetFile.toString()); zipOut.putNextEntry(zipEntry); byte[] bytes = new byte[INPUT_STREAM_BUFFER_SIZE]; int length; while ((length = fis.read(bytes)) >= 0) { zipOut.write(bytes, 0, length); } zipOut.closeEntry(); } return FileVisitResult.CONTINUE; } @Override public FileVisitResult visitFileFailed(Path file, IOException exc) { System.err.printf("Unable to zip : %s%n%s%n", file, exc); return FileVisitResult.CONTINUE; } }); }
코드를 요약하면 Files.walkFileTree()로 디렉토리의 하위 디렉토리, 파일들을 모두 순회하면서 압축하는 것이다.
이 때, response.getOutPutStream을 주입받은 ZipOut 클래스에 압축을 진행하기 때문에, 압축하면서 동시에 다운로드가 가능한 것이다.
+) 만약, 여러 낱개 파일이 아닌 하나의 파일의 용량이 큰 경우, INPUT_STREAM_BUFFER_SIZE 상수 값을 올리면 해당 파일의 다운로드 속도를 높일 수 있으니 팁으로 알아두자.
테스트
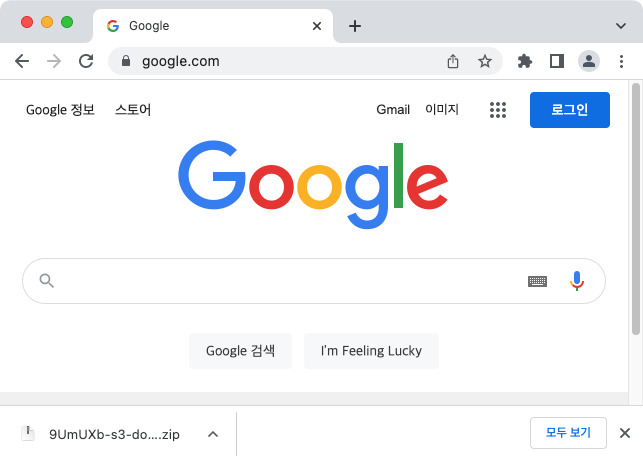
크롬 주소창에 이렇게 입력한다.
http://localhost:8080/s3/download/zip2/v1
정상적으로 다운로드가 되었다.
대용량 파일 역시 테스트해봤다. (7GB)
총 16분 (로컬 다운로드 3분 + 압축&사용자 다운로드 13분)
7분 가량 빨라졌다!
로컬 다운로드 시간은 TransferManager를 사용했으니 당연히 같겠지만,
압축을 하면서 다운로드 받는 방식이 훨씬 빨랐다.
분석을 해보니,
1번 방식은 압축을 전부 진행한 이후 파일을 다운로드해서 느린 데다가,
Resource 형태로 만들어서 리턴하는 것보다 response.getOutPutStream()에 바로 파일을 write하는 것이 더 빠르다는 것을 알았다.
3. 반복문 + 디렉토리 전체 조회
TransferManager는 S3 파일을 로컬에 다운받을 수 있다. 그러나, TransferManager를 계속 사용하다 보니, 또 이런 생각이 들었다.
"S3 파일을 로컬에 다운받지 않고, S3 -> 사용자로 바로 다운로드하게 할 수는 없을까?"
이제 과감히 TransferManager도 사용하지 않기로 한다.
컨트롤러
@GetMapping(value = "/download/zip3/**", produces = MediaType.APPLICATION_OCTET_STREAM_VALUE) public void downloadZip3(HttpServletRequest request, HttpServletResponse response) throws IOException { response.setStatus(HttpServletResponse.SC_OK); response.addHeader("Content-Disposition", "attachment; filename=" + new String((RandomStringUtils.randomAlphanumeric(6) + "-s3-download.zip").getBytes("UTF-8"), "ISO-8859-1")); String prefix = getPrefix(request.getRequestURI(), "/s3/download/zip3/"); s3Service.downloadZip3(prefix, response); }
컨트롤러는 API가 zip3로 변경된 것 빼면 2번 방식과 같다.
서비스
public void downloadZip3(String prefix, HttpServletResponse response) throws IOException { final int INPUT_STREAM_BUFFER_SIZE = 2048; try (ZipOutputStream zipOut = new ZipOutputStream(response.getOutputStream())) { // (1) // 다운로드하려는 S3 bucket, prefix 설정 ListObjectsRequest listObjectsRequest = new ListObjectsRequest(); listObjectsRequest.setBucketName(bucket); if (!prefix.equals("")) { listObjectsRequest.setPrefix(prefix); } ObjectListing s3Objects; do { // (2) // listObjects로 S3 객체 전체 조회 s3Objects = amazonS3.listObjects(listObjectsRequest); for (S3ObjectSummary s3ObjectSummary : s3Objects.getObjectSummaries()) { String fileName = s3ObjectSummary.getKey(); S3Object s3Object = amazonS3.getObject(new GetObjectRequest(bucket, fileName)); // (3) //response에 해당 객체 write InputStream is = s3Object.getObjectContent(); ZipEntry zipEntry = new ZipEntry(fileName); zipOut.putNextEntry(zipEntry); byte[] bytes = new byte[INPUT_STREAM_BUFFER_SIZE]; int length; while ((length = is.read(bytes)) >= 0) { zipOut.write(bytes, 0, length); } zipOut.closeEntry(); is.close(); log.info("download success {}", fileName); } // (4) //객체가 1,000건 이상인 경우를 대비 listObjectsRequest.setMarker(s3Objects.getNextMarker()); } while (s3Objects.isTruncated()); } }
listObjects()를 사용해 원하는 경로의 전체 객체를 가져와서 순차적으로 response.getOutPutStream()에 write하는 코드이다.
코드를 분석해보자.
(1)
// (1) // 다운로드하려는 S3 bucket, prefix 설정 ListObjectsRequest listObjectsRequest = new ListObjectsRequest(); listObjectsRequest.setBucketName(bucket); if (!prefix.equals("")) { listObjectsRequest.setPrefix(prefix); }
S3 객체 전체 조회를 위해 ListObjectsRequest를 설정해야 한다.
prefix가 없는 경우는 setPrefix는 따로 하지 않는다.
(2)
// (2) // listObjects로 S3 객체 전체 조회 s3Objects = amazonS3.listObjects(listObjectsRequest); for (S3ObjectSummary s3ObjectSummary : s3Objects.getObjectSummaries()) { String fileName = s3ObjectSummary.getKey(); S3Object s3Object = amazonS3.getObject(new GetObjectRequest(bucket, fileName)); ... }
listObjects()를 통해 전체 객체의 정보를 조회할 수 있다.
그리고 반복문 내 getObject()로 객체를 하나하나 조회한다.
(3)
// (3) //response에 해당 객체 write InputStream is = s3Object.getObjectContent(); ZipEntry zipEntry = new ZipEntry(fileName); zipOut.putNextEntry(zipEntry); byte[] bytes = new byte[INPUT_STREAM_BUFFER_SIZE]; int length; while ((length = is.read(bytes)) >= 0) { zipOut.write(bytes, 0, length); }
객체를 로컬에 저장하지 않고 바로 InputStream으로 변경해서 write하기 때문에, 로컬에 파일이 저장되지 않아도 된다.
(4)
ObjectListing s3Objects; do { // (2) ... // (3) ... // (4) // 객체가 1,000건 이상인 경우를 대비 listObjectsRequest.setMarker(s3Objects.getNextMarker()); } while (s3Objects.isTruncated());
do - while 문은 (2) (3) 번 전체를 감싸는 반복문이다.
listObjects()는 기본적으로 1,000건의 데이터만 가져오기 때문에 그 이상인 경우, 이처럼 반복문을 통해 객체를 전부 조회할 때까지 listObjects()를 반복해야 한다.
테스트
크롬 주소창에 이렇게 입력한다.
http://localhost:8080/s3/download/zip3/v1
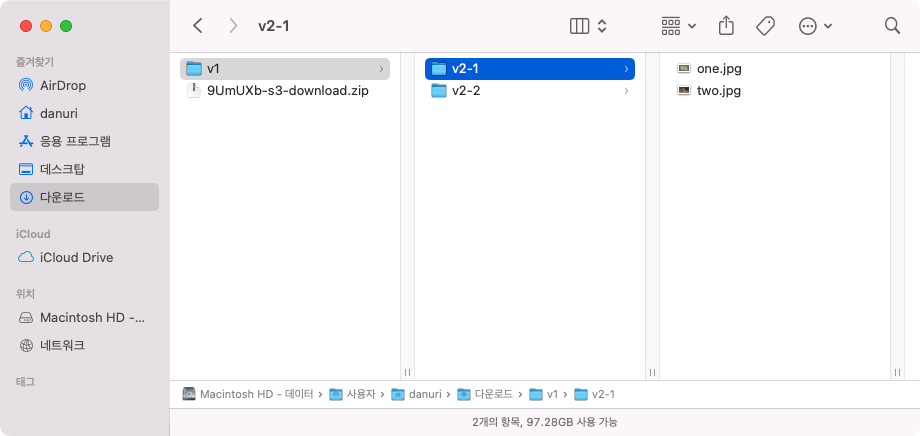
정상적으로 다운로드가 되었다.
대용량 파일 역시 테스트해봤다. (7GB)
총 19분 (압축&사용자 다운로드 19분)
1번 방법보다는 4분 빠르고, 2번 방법보다는 3분 느리다.
로컬 다운로드 시간이 없기 때문에, 제일 빠를 것으로 예상했지만 아니었다.
아무래도 로컬에서 사용자 다운로드를 진행하는 것이 S3에서 직접 다운로드를 진행하는 것보다 빠를테고,
S3에서 로컬로 다운로드하는 TransferManager의 성능이 매우 좋기 때문에 종합적으로 2번 방법이 가장 좋은 것으로 보인다.
그래도 로컬의 메모리를 사용하지 않는다는 측면에서는 만족스러운 성능이다.
총정리
지금까지 소개한 3가지 방법에 대해 정리해본다.
1. TransferManager 사용 + resource
총 23분 (로컬 다운로드 3분 + 압축 4분 + 사용자 다운로드 16분)
2. TransferManager 사용 + response
총 16분 (로컬 다운로드 3분 + 압축&사용자 다운로드 13분)
3. 반복문 + 디렉토리 전체 조회
총 19분 (압축&사용자 다운로드 19분)
결론적으로 3가지 방법 중 나는 2번 방법을 택했다. 그 과정은 이러하다.
처음에는 로컬의 메모리를 사용하지 않는 3번 방법을 택했다. 대용량 파일을 여러 사용자가 동시에 다운받게 되면 로컬 메모리가 부족할 것 같았다. 시간, 공간을 고려한 가장 최적의 선택이라고 생각했다.
그러나 회사에서 서버(EC2)의 저장 용량(EBS)을 더 늘려도 좋다는 허락을 받았고, AWS가 무료로 제공하는 30GB에서 100GB로 늘려, 로컬 용량을 확보한 뒤, 시간이 가장 빠른 2번 방법을 택하기로 했다.
이처럼 각자 상황에 맞춰 적절한 방법을 선택하면 되겠다.
물론 이는 대용량 파일 기준이지, 사실 웬만한 MB 단위 다운로드는 아무 방법이나 선택해도 된다. 오히려 이런 경우 라이브러리를 사용하여 가장 짧고 간단하게 코드를 짤 수 있는 1번 방법을 추천한다. input, output 스트림을 사용하지 않고 addFolder() 하나로 압축할 수 있는 것은 나에겐 나름 혁신이었다.
지금까지 S3 파일 압축 다운로드 API 3가지에 대해 성능을 비교 분석해보았다.
구글 검색을 열심히 하며 찾은 자료들을 종합하는데 꽤 애를 먹었지만, 성장에 좋은 밑거름이 되었다 생각한다.
참고자료
https://docs.aws.amazon.com/ko_kr/sdk-for-java/v1/developer-guide/examples-s3-transfermanager.html
https://iu-corner.tistory.com/entry/33-파일-업로드-처리-첨부파일의-다운로드-혹은-원본-보여주기-스프링
https://mand2.github.io/til/aws_s3_로컬디렉토리_업로드하기/
https://codechacha.com/ko/java-zip-unzip/
'java > spring' 카테고리의 다른 글
| [Spring] Mockito when으로 repository save 리턴받기 (0) | 2022.11.21 |
|---|---|
| [Spring] AWS S3 압축 파일 풀어서 업로드하기 - TransferManager (0) | 2022.08.05 |
| [Spring] AWS S3 객체 삭제 (0) | 2022.08.04 |
| [Spring] 엑셀 다운로드 API (0) | 2022.08.04 |
| [Spring] request multipart file size 조정 (0) | 2022.08.03 |