![[Java] I/O](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FPWdSX%2FbtretfXoXCO%2FGA6OIuPUlVPn2Tn2xFkKw1%2Fimg.png)
https://github.com/whiteship/live-study
whiteship/live-study
온라인 스터디. Contribute to whiteship/live-study development by creating an account on GitHub.
github.com
백기선님 자바 기초 스터디 13주차
목표
자바의 Input과 Ontput에 대해 학습하세요.
학습할 것 (필수)
- 스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
- InputStream과 OutputStream
- Byte와 Character 스트림
- 표준 스트림 (System.in, System.out, System.err)
- 파일 읽고 쓰기
스트림 (Stream) / 버퍼 (Buffer) / 채널 (Channel) 기반의 I/O
입출력이란?
I/O란 Input과 Output의 약자로 간단히 줄여서 입출력이라고 한다. 입출력은 컴퓨터 내부 또는 외부의 장치와 프로그램간의 데이터를 주고받는 것을 말한다. 예를 들어, System.out.println()을 이용해서 화면에 출력하는 것이 있다.
스트림 (Stream)
자바에서 어느 한쪽에서 다른 쪽으로 데이터를 전달하려면, 두 대상을 연결하고 데이터를 전송할 수 있는 무언가가 필요한데 이것을 스트림(Stream)이라 한다.
스트림은 blocking방식으로 동작한다. 데이터를 읽거나 쓰기 위해 스트림에 요청하면 스트림은 자신의 역할에 맞춰 다시 데이터를 읽거나 쓸 수 있을 때까지 다른 작업을 하지 못하고 무한정 기다린다. 그래서 입력과 출력을 동시에 수행하려면 입력을 위한 입력스트림과 출력을 위한 출력스트림이 필요하다.

스트림은 먼저 보낸 데이터를 먼저 받게 되어 있다. 큐(queue)와 같은 FIFO(First In First Out)구조로 되어 있다고 생각하면 된다.
버퍼 (Buffer)
버퍼는 임시로 데이터를 담아둘 수 있는 공간이다. 데이터가 입력될 때마다 스트림은 즉시 데이터를 전송하게 되는데 이 때 매번 디스크 접근이나 네트워크 접근 같은 오버헤드가 발생한다. 이러한 오버헤드를 줄이기 위해 버퍼는 중간에서 입력을 모아서 한 번에 출력함으로써 I/O의 성능을 향상시키는 역할을 한다.
채널 (Channel)
자바의 기본 입출력 방식인 스트림은 blocking 방식과 Non-Buffer의 특징으로 인해 입출력 속도가 느릴 수 밖에 없었다. 자바4부터 이러한 문제점을 해결하고자 NIO(New Input Output)이 포함되었는데, 채널이 NIO의 기본 입출력 방식이다.
채널이란 데이터의 양방향 통로이다. 채널은 스트림과 유사하지만 양방향이기 때문에 입력, 출력을 구분하지 않는다.
또, 채널은 스트림과 다르게 기본적으로 버퍼를 통해서만 입출력을 할 수 있고, blocking 뿐만 아니라 non-blocking방식도 가능해서 스레드를 효과적으로 재사용할 수 있다.
그렇다면 IO대신 무조건 NIO를 사용해야 할까? 그건 아니다. 입출력 처리가 오래 걸리는 작업의 경우 스레드를 재사용하는 non-blocking 방식으로 처리하는 NIO는 좋은 효율을 내지 못할 수 있다. 또한, 대용량 데이터를 처리해야할 경우 NIO의 버퍼 할당 크기가 문제가 된다.
따라서, NIO는 여러 클라이언트를 연결하거나 하나의 입출력 처리작업이 오래걸리지 않는 경우에 사용하는 것이 좋고, IO는 연결 클라이언트 수가 적고 전송되는 데이터가 대용량이면서 순차적으로 처리될 필요성이 있는 경우에 유리하다.
InputStream과 OutputStream
스트림은 바이트단위로 데이터를 전송하며 입출력 대상에 따라 다음과 같은 입출력스트림이 있다.
| 입력스트림 | 출력스트림 | 입출력 대상의 종류 |
| FileInputStream | FileOutputStream | 파일 |
| ByteArrayInputStream | ByteArrayOutputStream | 메모리(byte배열) |
| PipedInputStream | PipedOutputStream | 프로세스(프로세스간의 통신) |
| AudioInputStream | AudioOutputStream | 오디오장치 |
이렇게 여러 종류의 입출력 스트림이 있으며, 어떠한 대상에 대해서 입력or출력을 할 것인지에 따라서 해당 스트림을 선택해서 사용하면 될 것이다. 예를 들어 어떤 파일의 내용을 읽고자 하는 경우 FileInputStream을 사용하면 된다.
| InputStream | OutputStream |
| abstract int read() | abstract void write(int b) |
| int read(byte[] b) | void write(byte[] b) |
| int read(byte[] b, int off, int len) | void wirte(byte[] b, int off, int len) |
표에 나온 메서드의 사용법만 잘 알고 있어도 데이터를 읽고 쓰는 것은 입출력 대상의 종류와 관계없이 아주 간단한 일이 될 것이다.
InputStream의 read()와 OutputStream의 write(int b)는 입출력의 대상에 따라 읽고 쓰는 방법이 다를 것이기 때문에 각 상황에 알맞게 구현하라는 의미에서 추상메서드로 정의되어 있다.
Byte와 Character 스트림
Byte 스트림
InputStream과 OutputStream은 모든 바이트 기반의 스트림의 조상이며 다음과 같은 메서드가 선언되어 있다.
| 메서드명 | 설명 |
| int available() | 스트림으로부터 읽어 올 수 있는 데이터의 크기를 반환한다. |
| void close() | 스트림을 닫음으로써 사용하고 있던 자원을 반환한다. |
| void mark(int readlimit) | 현재위치를 표시해놓는다. 후에 reset()에 의해서 표시해 놓은 위치로 다시 돌아갈 수 있다. readlimit은 되돌아갈 수 있는 byte의 수이다. |
| boolean markSupported() | mark()와 reset()을 지원하는지를 알려 준다. mark()와 reset()기능을 지원하는 것은 선택적이므로, mark()와 reset()을 사용하기 전에 markSupported()를 호출해서 지원여부를 확인해야 한다. |
| abstract int read() | 1 byte를 읽어 온다(0 ~ 255 사이의 값). 더 이상 읽어 올 데이터가 없으면 -1을 반환한다. abstract메소드라서 InputStream의 자손들은 자신의 상황에 알맞게 구현해야한다. |
| int read(byte[] b) | 배열 b의 크기만큼 읽어서 배열을 채우고 읽어 온 데이터의 수를 반환한다. 반환하는 값은 항상 배열의 크기보다 작거나 같다. |
| int read(byte[] b, int off, int len) | 최대 len개의 byte를 읽어서, 배열 b의 지정된 위치(off)부터 저장한다. 실제로 읽어 올 수 있는 데이터가 len개보다 적을 수 있다. |
| void reset() | 스트림에서의 위치를 마지막으로 mark()이 호출되었던 위치로 되돌린다. |
| long skip(long n) | 스트림에서 주어진 길이(n)만큼을 건너뛴다. |
InputStream의 메서드
| 메서드명 | 설명 |
| void close() | 입력소스를 닫음으로써 사용하고 있던 자원을 반환한다. |
| void flush() | 스트림의 버퍼에 있는 모든 내용을 출력소스에 쓴다. |
| abstract void write(int b) | 주어진 값을 출력소스에 쓴다. |
| void write(byte[] b) | 주어진 배열 b에 저장된 모든 내용을 출력소스에 쓴다. |
| void write(byte[] b, int off, int len) | 주어진 배열 b에 저장된 내용 중에서 off번째부터 len개 만큼만을 읽어서 출력소스에 쓴다. |
OutputStream의 메서드
- 스트림의 종류에 따라 mark()와 reset()을 사용하여 이미 읽은 데이터를 되돌려서 다시 읽을 수 있다.
- flush()는 버퍼가 있는 출력스트림의 경우에만 의미가 있으며, OutputStream에 정의된 flush()는 아무런 일도 하지 않는다.
- 프로그램이 종료될 때, 사용하고 닫지 않은 스트림은 JVM이 자동으로 닫아 주기는 하지만, 스트림이 모든 작업을 마쳤으면 close()를 호출해서 반드시 닫아 주어야 한다. 그러나 ByteArrayInputStream과 같이 메모리를 사용하는 스트림과 이후에 알아볼 System.in, System.out과 같은 표준 입출력 스트림은 닫아 주지 않아도 된다.
Character 스트림
지금까지 알아본 스트림은 모두 바이트기반의 스트림이었다. 자바에서는 한 문자를 의미하는 char형이 2byte이기 때문에 바이트기반의 스트림으로 문자를 처리하는 데는 어려움이 있다.
이 점을 보완하기 위해 문자기반의 스트림이 제공된다.
InputStream -> Reader
OutputStream -> Writer| 바이트기반 스트림 | 문자기반 스트림 |
| FileInputStream FileOutputStream |
FileInputReader FileOutputWriter |
| ByteArrayInputStream ByteArrayOutputStream |
CharArrayInputReader CharArrayOutputWriter |
바이트기반 스트림과 문자기반 스트림은 이름만 조금 다를 뿐 활용방법은 거의 같다.
표준 스트림 (System.in, System.out, System.err)
표준 입출력은 콘솔을 통한 데이터 입력과 콘솔로의 데이터 출력을 의미한다. 자바에서는 표준 입출력을 위해 3가지 입출력 스트림 System.in, System.out, System.err를 제공하는데, 이들은 자바 애플리케이션 실행과 동시에 사용할 수 있게 자동 생성되기 때문에 개발자가 별도로 스트림을 생성하는 코드를 작성하지 않아도 된다.
System.in 콘솔로부터 데이터를 입력받는데 사용
System.out 콘솔로부터 데이터를 출력하는데 사용
System.err 콘솔로부터 데이터를 출력하는데 사용out, err, in의 타입은 InputStream과 PrintStream이지만 실제로는 버퍼를 이용하는 BufferedInputStream과 BufferedOutputStream의 인스턴스를 사용한다.
파일 읽고 쓰기
Byte 스트림
FileInputStream과 FileOutputStream
파일에 입출력을 하기 위한 스트림이다. 실제 프로그래밍에서 많이 사용되는 스트림 중의 하나이다.
class FileCopy {
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream("FileCopy.java");
FileOutputStream fos = new FileOutputStream("FileCopy.bak");
int data = 0;
while ((data = fis.read()) != -1) {
fos.write(data);
}
fis.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}<결과 - FileCopy.bak>
class FileCopy {
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream("FileCopy.java");
FileOutputStream fos = new FileOutputStream("FileCopy.bak");
int data = 0;
while ((data = fis.read()) != -1) {
fos.write(data);
}
fis.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}파일의 내용을 읽어서 다른 파일에 그대로 출력하는 간단한 예제이다.
read()의 반환값이 int형(4byte)이긴 하지만, read()는 한 번에 1byte씩 데이터를 읽어 들이기 때문에, char형(2byte)으로 변환한다 해도 손실되는 값은 없다.
그럼 굳이 왜 int를 사용하지? 1byte의 범위가 0~255로 결국 정수이기도 하고, 또 읽을 수 있는 입력값이 더 이상 없음을 알리는 값(-1)도 필요하다. 그래서 다소 크긴 하지만 정수형 중에서는 연산이 가장 빠른 int형 값을 반환하도록 한 것이다.
BufferedInputStream과 BufferedOutputStream
스트림의 입출력 효율을 높이기 위해 버퍼를 사용하는 보조스트림이다.
+) 보조스트림이란 스트림의 기능을 보완하기 위한 것으로써 실제 데이터를 주고받는 스트림이 아니기 때문에 데이터를 입출력할 수 있는 기능은 없지만, 스트림의 기능을 향상시키거나 새로운 기능을 추가할 수 있다.
한 바이트씩 입출력하는 것보다는 버퍼(바이트배열)를 이용해서 한 번에 여러 바이트를 입출력하는 것이 빠르기 때문에 대부분의 입출력 작업에서 사용된다.
BufferedInputStream의 버퍼크기는 보통 입력소스가 파일인 경우 8K 정도의 크기로 하는 것이 보통이며, 생성자에 size 인자를 넣어서 변경할 수도 있다.
read()를 호출하면 입력소스로부터 버퍼 크기만큼의 데이터를 읽어다 자신의 내부 버퍼에 저장한다. 이제 프로그램에서는 입력소스로부터 읽는 것이 아닌 내부의 버퍼로부터 읽어가면서 훨씬 빠르게 작업할 수 있다. (즉, OS 레벨의 시스템 콜 횟수를 줄일 수 있다)
BufferedOutputStream은 역시 버퍼를 이용해서 작업을 하게 된다. 버퍼가 가득 차면, 그 때 버퍼의 모든 내용을 출력 소스에 출력한다. 그리고 버퍼를 비우고 다시 프로그램으로부터 출력을 저장할 준비를 한다.
버퍼가 가득 찼을 때만 출력을 하기 때문에, 마지막 출력부분이 출력소스에 쓰이지 못하고 버퍼에 남아있는 채로 프로그램이 종료될 수 있다는 점을 주의해야 한다. 그래서 모든 출력작업을 마치면 close()를 호출해서 버퍼에 있는 모든 내용을 출력하도록 해야 한다.
무슨 의미인지 잘 이해가 안된다면 아래 예시를 참고하자.
class BufferedOutputStreamEx1 {
public static void main(String[] args) {
try {
FileOutputStream fos = new FileOutputStream("123.txt");
// BufferedOutputStream의 크기를 5로 한다.
BufferedOutputStream bos = new BufferedOutputStream(fos, 5);
// 파일 123.txt에 1부터 9까지 출력한다.
for (int i = '1'; i <= '9'; i++) {
bos.write(i);
}
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}<결과 - 123.txt>
12345크기가 5인 BufferedOutputStream을 이용해서 파일 123.txt에 1부터 9까지 출력하는 예제인데, 결과를 보면 5까지만 출력된 것을 확인할 수 있다. 그 이유는 버퍼에 남아있는 데이터가 출력되지 못한 상태로 프로그램이 종료되었기 때문이다.
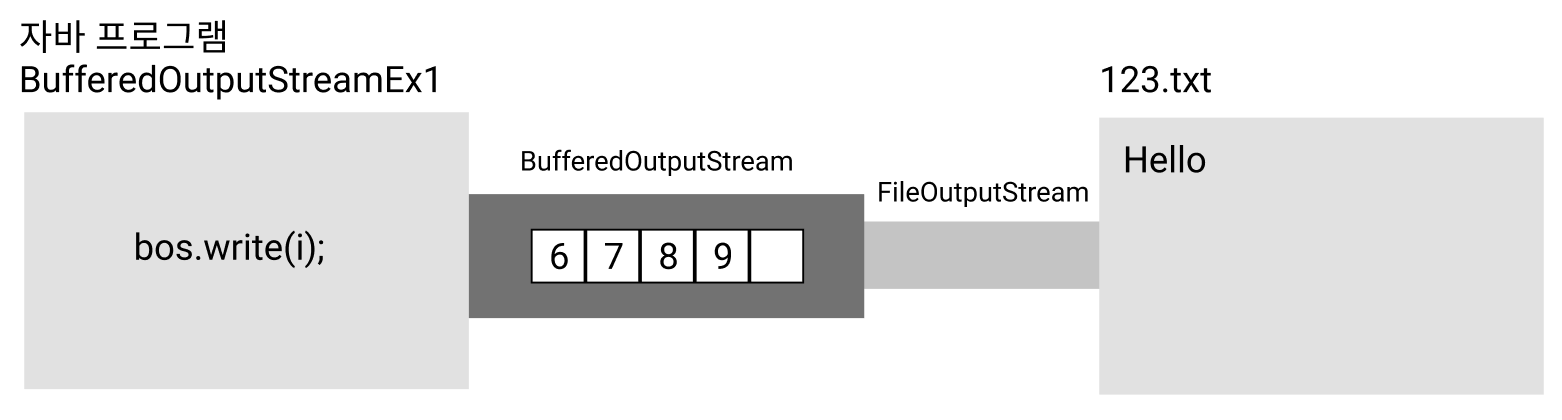
예제에서 fos.close()를 호출해서 스트림을 닫아주기는 했지만, 이렇게 해서는 BufferedOutputStream의 버퍼에 있는 내용이 출력되지 않는다. bos.close()와 같이 BufferedOutputStream의 close()를 호출해 주어야 버퍼에 남아있던 모든 내용이 호출된다.
BufferedOutputStream의 close()는 flush()를 호출해 버퍼를 비우고 FileOutputStream의 close()도 같이 호출해 주기 때문이다.
이처럼 보조스트림을 사용한 경우에는 기반스트림의 close()나 flush()를 호출할 필요없이 단순히 보조스트림의 close()를 호출하기만 하면 된다.
Character 스트림
FileReader와 FileWriter
파일로부터 텍스트데이터를 읽고, 파일에 쓰는데 사용된다.
class FileReaderEx1 {
public static void main(String[] args) {
try {
String fileName = "test.txt";
FileInputStream fis = new FileInputStream(fileName);
FileReader fr = new FileReader(fileName);
int data = 0;
// FileInputStream을 이용해서 파일내용을 읽어 화면에 출력한다.
while ((data = fis.read()) != -1) {
System.out.print((char) data);
}
System.out.println();
fis.close();
// FileReader를 이용해서 파일내용을 읽어 화면에 출력한다.
while ((data = fr.read()) != -1) {
System.out.print((char) data);
}
System.out.println();
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}<결과>
Hello, ìë
íì¸ì?
Hello, 안녕하세요?예제는 같은 내용의 파일(test.txt)을 한번은 FileInputStream으로 다른 한 번은 FileReder로 읽어서 화면에 출력했다. 결과에서도 알 수 있듯이, FileInputStream을 사용했을 때는 한글이 깨져서 출력되는 것을 알 수 있다.
BufferedReader와 BufferedWriter
버퍼를 이용해서 입출력의 효율을 높일 수 있도록 해준다. 버퍼를 이용하면 효율이 비교할 수 없을 정도로 좋아지기 때문에 사용하는 것이 좋다.
BufferedReader의 readLine()을 사용하면 데이터를 라인단위로 읽을 수 있고,
BufferedWriter는 newLine()이라는 줄바꿈해주는 메서드를 가지고 있다.
class BufferedReaderEx1 {
public static void main(String[] args) {
try {
FileReader fr = new FileReader("BufferedReaderEx1.java");
BufferedReader br = new BufferedReader(fr);
String line = "";
for (int i = 1; (line = br.readLine()) != null; i++) {
// ";"를 포함한 라인을 출력한다.
if (line.indexOf(";") != -1) {
System.out.println(i + ":" + line);
}
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}<결과>
1:package week13;
3:import java.io.BufferedReader;
4:import java.io.FileReader;
5:import java.io.IOException;
10: FileReader fr = new FileReader("BufferedReaderEx1.java");
11: BufferedReader br = new BufferedReader(fr);
13: String line = "";
14: for (int i = 1; (line = br.readLine()) != null; i++) {
15: // ";"를 포함한 라인을 출력한다.
16: if (line.indexOf(";") != -1) {
17: System.out.println(i + ":" + line);
20: br.close();
22: e.printStackTrace();BufferedReader의 readLine()을 이용해서 파일을 라인단위로 읽은 다음 indexOf()를 이용해서 ';'를 포함하고 있는지 확인하여 출력하는 예제이다. 파일에서 특정 문자 또는 문자열을 포함한 라인을 쉽게 찾아낼 수 있음을 보여준다.
'java > java' 카테고리의 다른 글
| [Java] JUnit 5 (0) | 2021.09.24 |
|---|---|
| [Java] 제네릭 (1) | 2021.09.19 |
| [Java] 애노테이션 (1) | 2021.09.05 |
| [Java] 다중 조건 정렬 (0) | 2021.08.29 |
| [Java] Enum (1) | 2021.08.27 |